







http://blog.csdn.net/pipisorry/article/details/78258198
Seq2seq模型
seq2seq是什么?简单的说,就是根据一个输入序列x,来生成另一个输出序列y。seq2seq有很多的应用,例如翻译,文档摘取,问答系统等等。在翻译中,输入序列是待翻译的文本,输出序列是翻译后的文本;在问答系统中,输入序列是提出的问题,而输出序列是答案。
Encoder-Decoder模型
为了解决seq2seq问题,有人提出了encoder-decoder模型,也就是编码-解码模型。所谓编码,就是将输入序列转化成一个固定长度的向量;解码,就是将之前生成的固定向量再转化成输出序列。
基本的seq2seq模型包含了两个RNN,解码器和编码器,最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量State Vector,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。如下图所示:
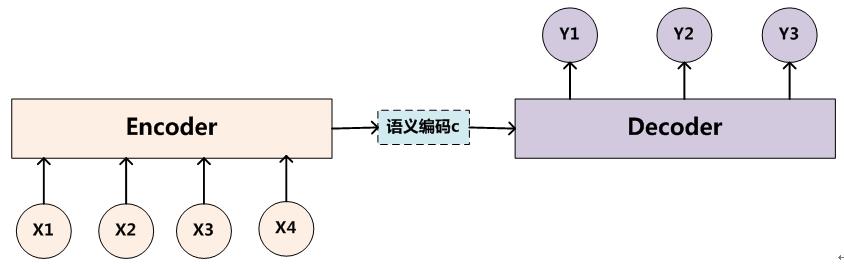

模型展开

编码器和解码器可以使用相同的权重,或者,更常见的是,编码器和解码器分别使用不同的参数。多层神经网络已经成功地用于序列序列模型之中了。
具体实现的时候,编码器和解码器都不是固定的,可选的有CNN/RNN/BiRNN/GRU/LSTM等等,你可以自由组合。比如说,你在编码时使用BiRNN,解码时使用RNN,或者在编码时使用RNN,解码时使用LSTM等等。每个矩形都表示着RNN的一个核,通常是GRU(Gated recurrent units)或者长短期记忆(LSTM)核。
为了方便阐述,选取编码和解码都是RNN的组合。
编码encoder
在RNN中,当前时间的隐藏状态是由上一时间的状态和当前时间输入决定的,也就是
ht=f(ht−1,xt)
获得了各个时间段的隐藏层以后,再将隐藏层的信息汇总,生成最后的语义向量
C=q(h1,h2,h3,…,hTx)
一种简单的方法是将最后的隐藏层作为语义向量C,即
C=q(h1,h2,h3,…,hTx)=hTx
解码decoder
解码阶段可以看做编码的逆过程。这个阶段,我们要根据给定的语义向量C和之前已经生成的输出序列y1,y2,…yt−1来预测下一个输出的单词yt,即
yt=argmaxP(yt)=∏t=1Tp(yt|{y1,…,yt−1},C)
也可以写作
yt=g({y1,…,yt−1},C)
而在RNN中,上式又可以简化成
yt=g(yt−1,st,C)
其中s是输出RNN中的隐藏层
st=f(st−1,y t−1, C)
C代表之前提过的语义向量,yt−1表示上个时间段的输出,反过来作为这个时间段的输入。而g则可以是一个非线性的多层的神经网络,产生词典中各个词语属于yt的概率。
解码分为训练和推理两个阶段
注意,我们这里将decoder分为了training和predicting,这两个encoder实际上是共享参数的,也就是通过training decoder学得的参数,predicting会拿来进行预测。
那么为什么我们要分两个呢,这里主要考虑模型的robust。在training阶段,为了能够让模型更加准确,我们并不会把t-1的预测输出作为t阶段的输入,而是直接使用target data中序列的元素输入到Encoder中。而在predict阶段,我们没有target data,有的只是t-1阶段的输出和隐层状态。当然,predicting虽然与training是分开的,但他们是会共享参数的,training训练好的参数会供predicting使用。
training过程
优化时,采用极大似然估计,让seq a encode后再decode得到seq b的概率最大。
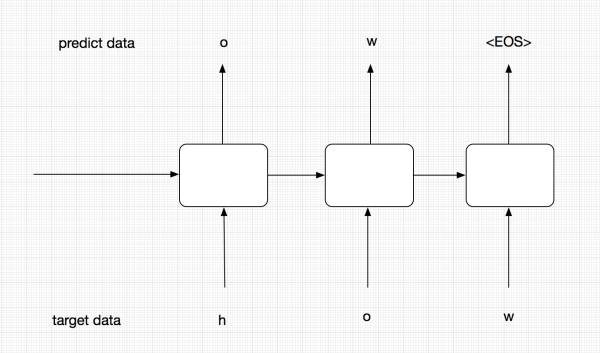
上面的图中代表的是training过程。在training过程中,我们并不会把每个阶段的预测输出作为下一阶段的输入,下一阶段的输入我们会直接使用target data,这样能够保证模型更加准确。
predict阶段

这个图代表我们的predict阶段,在这个阶段,我们没有target data,这个时候前一阶段的预测结果就会作为下一阶段的输入。
[干货|从Encoder到Decoder实现Seq2Seq模型]
解译的过程可以被理解为运用贪心算法(一种局部最优解算法,即选取一种度量标准,默认在当前状态下进行最好的选择)来返回对应概率最大的词汇;
或是通过集束搜索(Beam Search(Bahdanau, Bengio 2014),一种启发式搜索算法,可以基于设备性能给予时间允许内的最优解)在序列输出前检索大量的词汇,从而得到最优的选择;
或者通过random sample(Graves 2013)。
[Deeplearning:集束搜索beam search]

[seq2seq模型 ]
seq2seq模型的损失函数
一般而言,会用最大似然法来最大化输出序列基于输入序列的条件概率:

因此损失函数可以表示为:

一个多层的seq2seq的LSTM神经网络的处理行为

encoder-decoder的局限性
最大的局限性就在于编码和解码之间的唯一联系就是一个固定长度的语义向量C。也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中去。
这样做有两个弊端,一是语义向量无法完全表示整个序列的信息,还有就是先输入的内容携带的信息会被后输入的信息稀释掉,或者说,被覆盖了。输入序列越长,这个现象就越严重。这就使得在解码的时候一开始就没有获得输入序列足够的信息, 那么解码的准确度自然也就要打个折扣了。
由于基础Seq2Seq的种种缺陷,随后引入了Attention的概念以及Bi-directional encoder layer等。
在机器翻译任务上,Cho等人在Decoder部分进行了改进,为Decoder RNN的每个结点添加了由Encoder端得到的上下文向量作为输入,使得解码过程中的每个时刻都有能力获取到上下文信息,从而加强了输出序列和输入序列的相关性(Cho Ket al. 2014)。
注意事项
bucking、填充和反转encoder输入
桶(bucket)的方法,这也是一种对于变长度句子翻译的很好用的工具。当我们想从英文翻译到法语的时候,输入的英文的长度为L1而输出法语的长度则为L2。而我们现在已知英文从encoder_input进入法语从decoder_input输出(其标识有GO的前缀),这样我们就需要一个(L1,L2+1)长的seq2seq模型,来对每一对英法文进行处理.这将导致一个庞大的图形,由许多非常相似的子图组成。另一方面,我们可以用特殊的PAD符号来填充每个句子。那么我们只需要一个seq2seq模型,用于填充长度。然而对于一些非常短的语句和词汇,我们的模型将会变得低效,编码和解码太多的PAD填充符会变得很没有意义。
似乎我们需要在对过短和过长句子的处理之间找到一个平衡点,我们会使用不同长度的桶,并且在桶上放置不同的句子并且填充他们至桶满。在translate.py之中,我们会使用以下的默认长度的桶。
buckets = [(5, 10), (10, 15), (20, 25), (40, 50)]
这意味着如果输入是具有3个令牌的英文句子,并且相应的输出是具有6个令牌的法语句子,那么它们将被放入第一个数据桶,并填充到编码器输入的长度为5,解码器输入的长度为10 。如果我们有一个8个令牌的英文句子,相应的法语句子有18个令牌,那么它们将不适用于(10,15)桶,所以(20,25)桶将被使用,即英文句子被填补到20个长度,而法国一到25个长度。
请记住,当构建解码器输入时,我们将特殊GO符号添加到到了里面。这是在seq2seq_model.py的get_batch()函数中完成的,其也会反转英语的输入。正如Sutskever所说,这有助于改善机器学习后的结果。现在有句英文I go.就会被分解为["I", "go", "."],其将作为编码器的输入,而输出Je vais.则会被分解为["Je", "vais", "."]。其会被放入(5,10)的桶中。所以经过反转并且田冲后的输入就是[PAD PAD "." "go" "I"],而输出则是[GO "Je" "vais" "." EOS PAD PAD PAD PAD PAD]。
seq2seq模型的选择

注意力模型Attention Model
融合attention的decoder:

[A Two-stage Conversational Query Rewriting Model with Multi-task Learning]
代码实现及示例
seq2seq有多种多样的形式,使用了不同的RNN核,但是万变不离其宗,其总是接受一个编码和解码的输入。
TensorFlow seq2seq模型
TensorFlow也为此创建了一个模型:tensorflow/tensorflow/python/ops/seq2seq.py,最基本的RNN编码-解码器就像是这样子的:
outputs, states = basic_rnn_seq2seq(encoder_inputs, decoder_inputs, cell)Tensorflow中实现encoder-decoder模型
tensorflow中数据预处理
在神经网络中,对于文本的数据预处理无非是将文本转化为模型可理解的数字,这里都比较熟悉,不作过多解释。
需要对target端的数据进行一步预处理。在这里我们需要加入以下四种字符,<PAD>主要用来进行字符补全,<EOS>和<GO>都是用在Decoder端的序列中,告诉解码器句子的起始与结束,<UNK>则用来替代一些未出现过的词或者低频词。
-
< PAD>: 补全字符。
-
< EOS>: 解码器端的句子结束标识符。
-
< UNK>: 低频词或者一些未遇到过的词等。
-
< GO>: 解码器端的句子起始标识符。
用下图解释:

我们此时只看右边的Decoder端,可以看到我们的target序列是[<go>, W, X, Y, Z, <eos>],其中<go>,W,X,Y,Z是每个时间序列上输入给RNN的内容,我们发现,<eos>并没有作为输入传递给RNN。因此我们需要将target中的最后一个字符去掉,同时还需要在前面添加<go>标识,告诉模型这代表一个句子的开始。


构造Decoder
-
对target数据进行embedding。
-
构造Decoder端的RNN单元。
-
构造输出层,从而得到每个时间序列上的预测结果。
-
构造training decoder。
-
构造predicting decoder。
[干货|从Encoder到Decoder实现Seq2Seq模型]
encoder-decoder对联示例
给出上联对下联图例

Encoder-Decoder框架加上Attention应该会显著提升产生下联的质量,原因还是因为它是要求严格对仗的。
上联给出 完全自动生成对联(上联也自动生成)
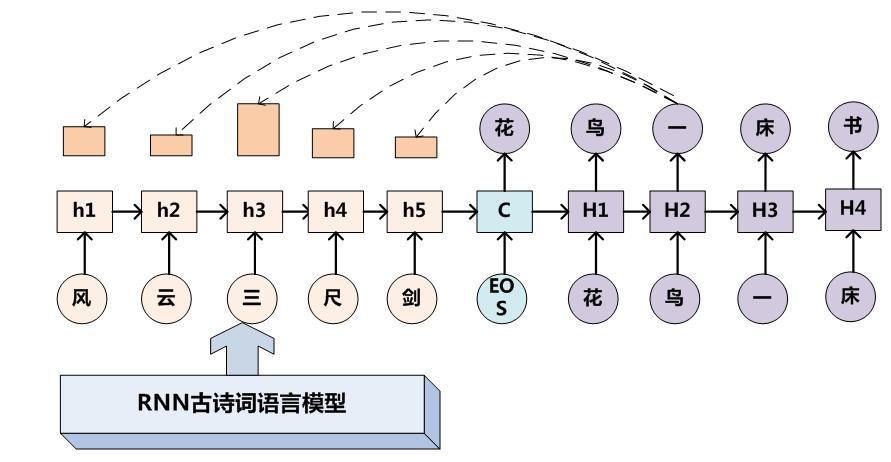
[使用Encoder-Decoder模型自动生成对联的思路 ]
seq2seq在回复生成(Response Generation)任务中的应用和论文
Shang等人针对单轮对话任务提出了一种混合模型,使用基础模型的上下文向量建模输入序列的整体信息,使用Attention的加权和动态捕捉每次解码所需的局部信息,将两者拼接作为新的上下文向量进行解码(Shang L et al. 2015)。
此外,Serban等人提出了多层次的RNN模型来完成多轮对话任务。其中底层Encoder负责句子级的编码,高层Encoder读取底层Encoder对所有历史句子的编码作为输入从而对上下文进行编码,最后由Decoder根据上下文编码解码出输出序列(Serban I Vet al. 2016a)。
用于回复生成的Sequence to sequence模型所产生的回复,存在一个较为普遍的问题:回复内容的相关性问题。通过实验结果的观察,大家发现模型总是倾向于生成一般性的万能回复,如“我不知道”,“我也是”等。很多人针对这个问题对Sequence to sequence模型进行了相应的改进。
Li等人提出可以使用最大互信息目标函数来训练模型,将输入输出序列的互信息视为相关性的参考指标,使模型预测出和输入序列具有最大互信息的输出序列,从而获得相关性更好的回复(LiJ etal. 2015)。
Serban等人提出了在生成阶段引入一个随机的隐变量来增强回复的多样性(Serban I V et al. 2016b),之后又提出了在基本结构上加入一个主题词Encoder以加强回复和输入序列相关性的方法(Serban I V et al. 2016c)。
此外,Mou等人也基于这种利用主题词的方法来解决万能回复的问题,他们首先使用统计的方式计算出一个应该在回复中出现的主题词,然后由这个主题词开始使用Sequence to sequence模型先逆向生成回复的前半句,然后再正向生成回复的后半句,两者拼接形成最终的回复(Mou L et al. 2016)。
(Zhu Q et al. 2016)认为模型中所有回复均由开始字符开始生成,可能是导致万能回复的一个问题,进而将生成阶段分成了两部分进行,在不使用开始字符的条件下生成第一个回复的字符。我们将Encoder的最后一个隐层状态向量c看做当前时刻的上下文,使用一个相似度矩阵来计算c与所有候选词Embedding向量的相似性,进而在所有候选词中选取相似性最大者作为第一个字符。其中相似度矩阵作为模型的参数在训练过程中和其他参数共同学习得到。获取第一个字符后,使用这个字符由Decoder继续后续的生成。
Image Caption图片说明
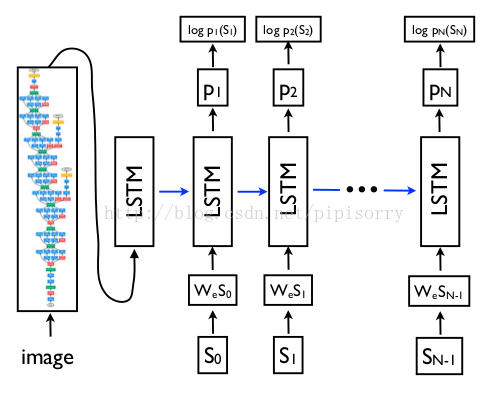
LSTM model combined with a CNN image embedder (as defined in [24]) and word embeddings.
[Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge]
from: http://blog.csdn.net/pipisorry/article/details/78258198
ref: 两篇文章针对机器翻译的问题
Google Brain团队 [Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural networks. In NIPS, 2014.]
Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》
[图片seq2seq模型]














 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









