






毕业项目推荐:基于深度学习的PCB板缺陷检测系统(python+卷积神经网络)
概要
PCB缺陷检测在电子制造行业中发挥着关键作用,质量和效率,仍然为自动化生产提供了YOLOv8和YOLOv5深度学习框架的PCB缺陷检测PCB缺陷检测模型。断线、短路和焊点问题。另外,我们还开发用户友好的PCB缺陷检测系统,支持实时实时监测,并图形界面清晰显示检测结果。在本文中,我们将详细介绍如何利用深度学习中的YOLOv5算法来实现对PCB板缺陷的检测,并结合PyQt5设计了一个简约而强大的系统UI界面。通过该界面,您可以轻松选择自己的视频文件或图片文件进行检测,并且还能够根据需要替换训练好的yolov5模型,以适应不同的数据检测需求。
我们的系统界面不仅外观优美,而且具备出色的检测精度和强大的功能。它支持多目标实时检测,并允许您自由选择感兴趣的检测目标。
关键词:PCB板缺陷;目标检测;深度学习;特征融合;注意力机制;卷积神经网络
🔥计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,远程协助,代码定制,私聊会回复!
✍🏻作者简介:机器学习,深度学习,卷积神经网络处理,图像处理
🚀B站项目实战:https://space.bilibili.com/364224477
😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+
🤵♂代做需求:@个人主页
一、整体资源介绍
项目中所用到的算法模型和数据集等信息如下:
**算法模型: **
yolov8、yolov8 + SE注意力机制 或 yolov5、yolov5 + SE注意力机制
**数据集: **
网上下载的数据集,格式都已转好,可直接使用。
以上是本套代码算法的简单说明,**添加注意力机制是本套系统的创新点 ** 。
技术要点
功能展示:
部分核心功能如下:
功能1 支持单张图片识别
系统支持用户选择图片文件进行识别。通过点击图片选择按钮,用户可以选择需要检测的图片,并在界面上查看所有识别结果。该功能的界面展示如下图所示:

功能2 支持遍历文件夹识别
系统支持选择整个文件夹进行批量识别。用户选择文件夹后,系统会自动遍历其中的所有图片文件,并将识别结果实时更新显示在右下角的表格中。该功能的展示效果如下图所示:
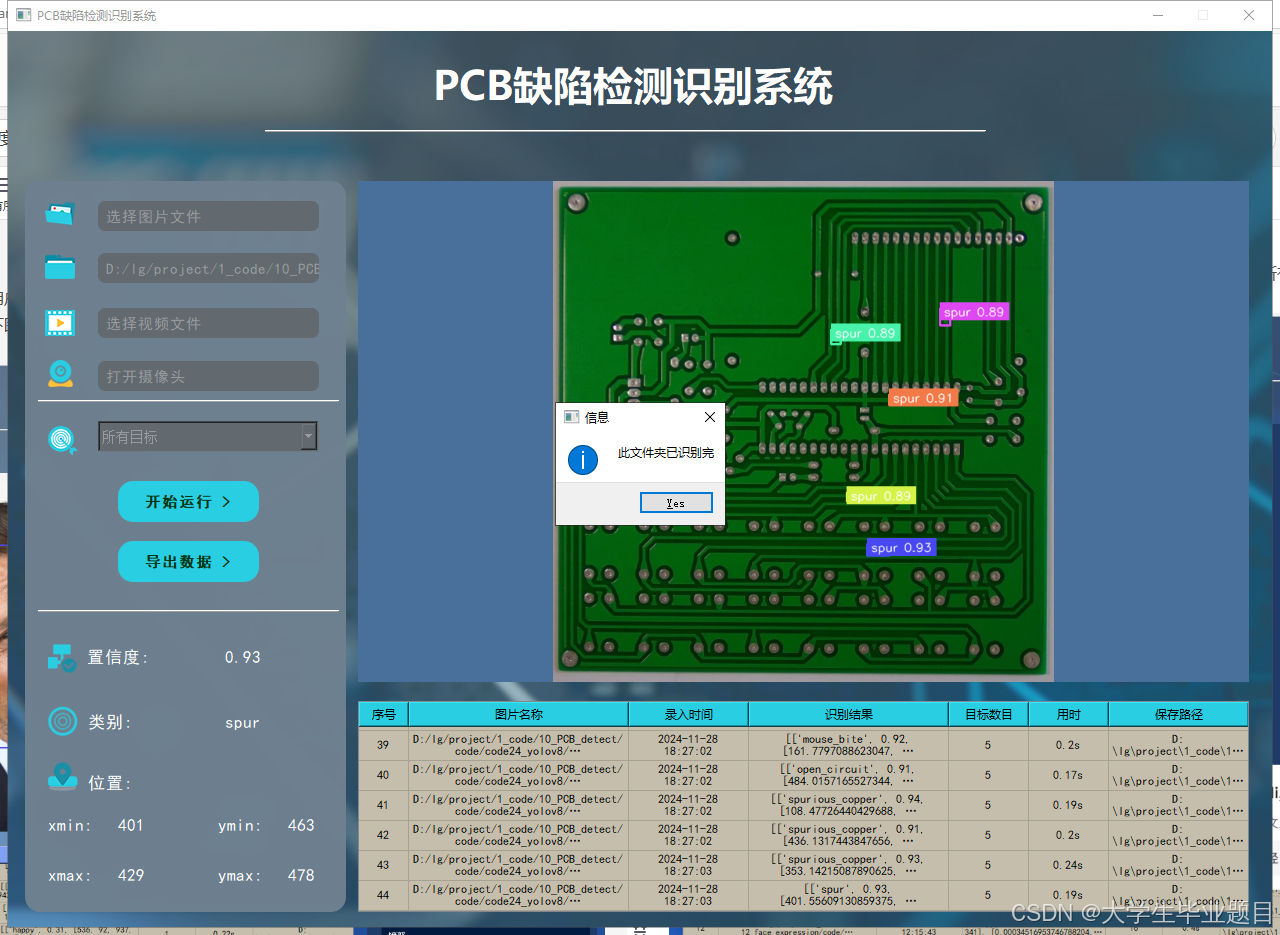
功能3 支持识别视频文件
在许多情况下,我们需要识别视频中的目标。因此,系统设计了视频选择功能。用户点击视频按钮即可选择待检测的视频,系统将自动解析视频并逐帧识别多个目标,同时将识别结果记录在右下角的表格中。以下是该功能的展示效果:
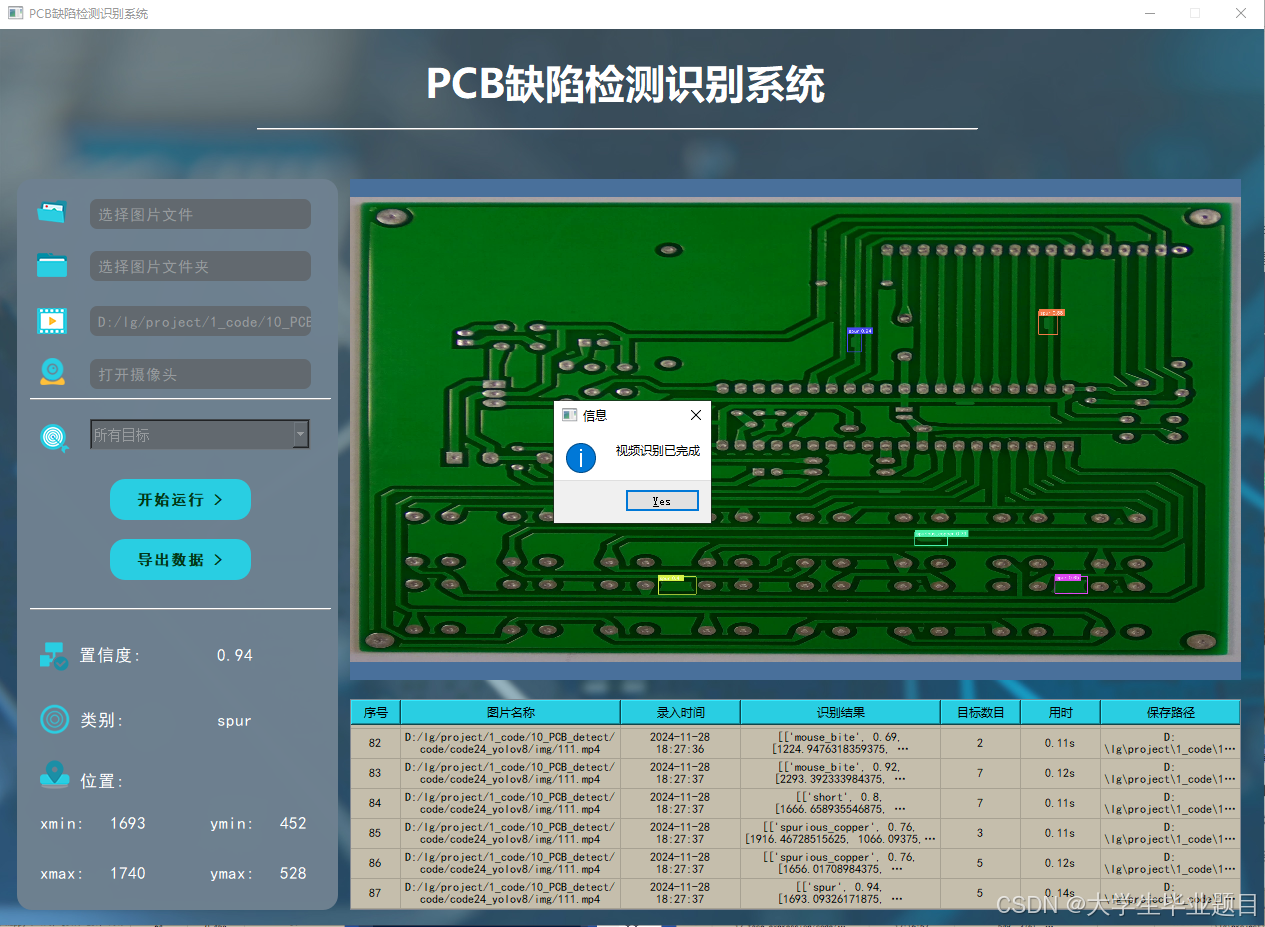
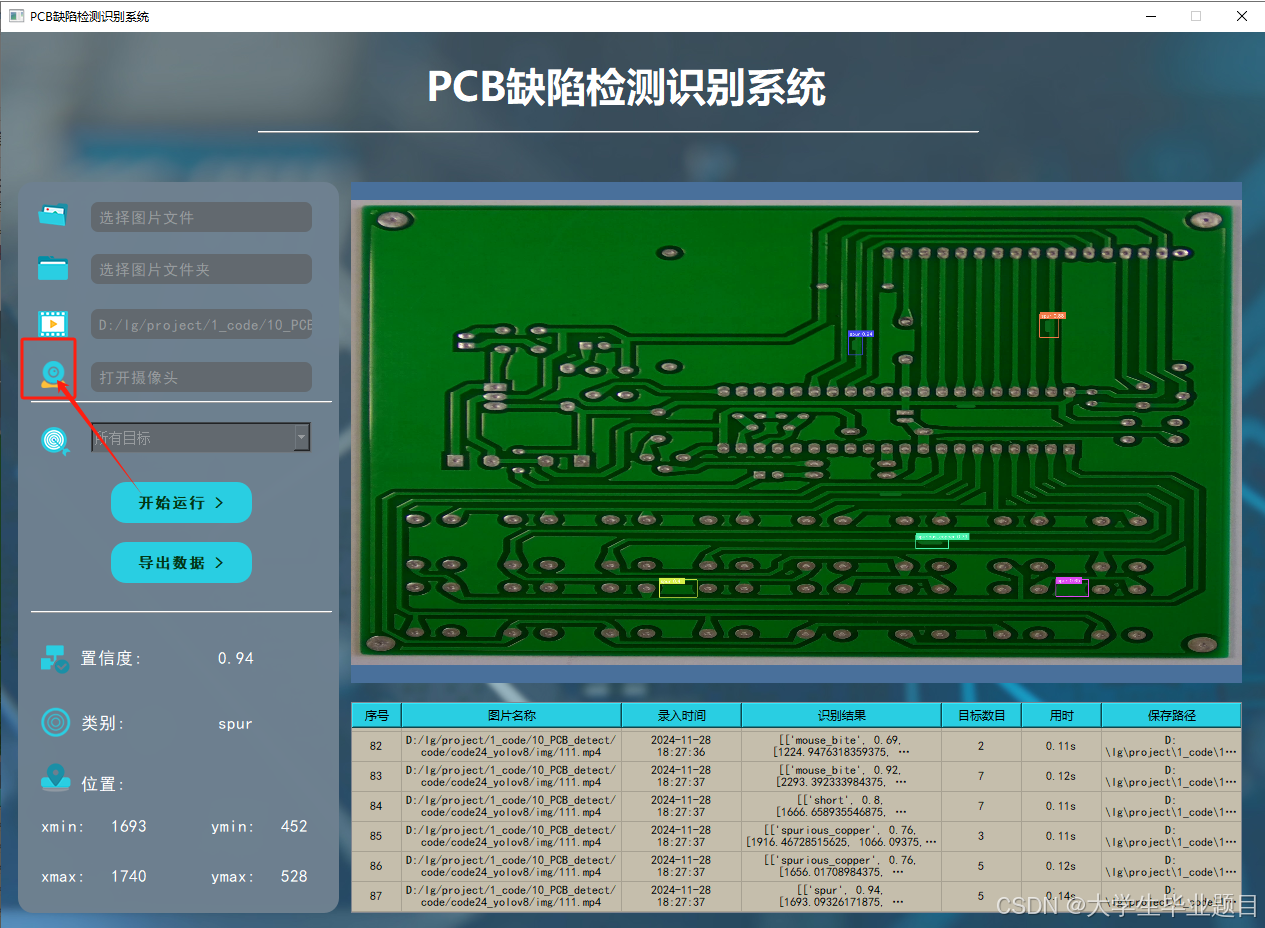
功能4 支持摄像头识别
在许多场景下,我们需要通过摄像头实时识别目标。为此,系统提供了摄像头选择功能。用户点击摄像头按钮后,系统将自动调用摄像头并进行实时识别,识别结果会即时记录在右下角的表格中。
功能5 支持结果文件导出(xls格式)
本系统还添加了对识别结果的导出功能,方便后续查看,目前支持导出xls数据格式,功能展示如下:
功能6 支持切换检测到的目标查看
二、数据集
数据集总共包含下面6个类别,且已经分好 train、val、test文件夹,也提供转好的yolo格式的标注文件,可以直接使用。
missing_hole # 漏孔
mouse_bite # 鼠牙洞
open_circuit # 开路
short # 短路
spur # 毛刺
spurious_copper # 杂铜
数据样式如下:

三、算法介绍
1. YOLOv8 概述
简介
YOLOv8算法的核心特性和改进如下:
相比之前版本,YOLOv8对模型结构进行了精心微调,不再是“无脑”地将同一套参数应用于所有模型,从而大幅提升了模型性能。这种优化使得不同尺度的模型在面对多种场景时都能更好地适应。
然而,新引入的C2f模块虽然增强了梯度流,但其内部的Split等操作对特定硬件的部署可能不如之前的版本友好。在某些场景中,C2f模块的这些特性可能会影响模型的部署效率。
2. YOLOv5 概述
简介
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五个版本。这个模型的结构基本一样,不同的是deth_multiole模型深度和width_multiole模型宽度这两个参数。就和我们买衣服的尺码大小排序一样,YOLOV5n网络是YOLOV5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。不过最常用的一般都是yolov5s模型。

本系统采用了基于深度学习的目标检测算法——YOLOv5。作为YOLO系列算法中的较新版本,YOLOv5在检测的精度和速度上相较于YOLOv3和YOLOv4都有显著提升。它的核心理念是将目标检测问题转化为回归问题,简化了检测过程并提高了性能。
YOLOv5引入了一种名为SPP (Spatial Pyramid Pooling)的特征提取方法。SPP能够在不增加计算量的情况下,提取多尺度特征,从而显著提升检测效果。
在检测流程中,YOLOv5首先通过骨干网络对输入图像进行特征提取,生成一系列特征图。然后,对这些特征图进行处理,生成检测框和对应的类别概率分数,即每个检测框内物体的类别和其置信度。
YOLOv5的特征提取网络采用了CSPNet (Cross Stage Partial Network)结构。它将输入特征图分成两部分,一部分通过多层卷积处理,另一部分进行直接下采样,最后再将两部分特征图进行融合。这种设计增强了网络的非线性表达能力,使其更擅长处理复杂背景和多样化物体的检测任务。
🌟 四、模型训练步骤
- 使用pycharm打开代码,找到
train.py打开,示例截图如下:
 1. 修改
1. 修改 model_yaml的值,根据自己的实际情况修改,想要训练yolov8s模型 就 修改为model_yaml = yaml_yolov8s, 训练 添加SE注意力机制的模型就修改为model_yaml = yaml_yolov8_SE1. 修改data_path数据集路径,我这里默认指定的是traindata.yaml文件,如果训练我提供的数据,可以不用改 - 修改
model.train()中的参数,按照自己的需求和电脑硬件的情况更改# 文档中对参数有详细的说明
model.train(data=data_path, # 数据集
imgsz=640, # 训练图片大小
epochs=200, # 训练的轮次
batch=2, # 训练batch
workers=0, # 加载数据线程数
device=‘0’, # 使用显卡
optimizer=‘SGD’, # 优化器
project=‘runs/train’, # 模型保存路径
name=name, # 模型保存命名
)
- 1. 修改
traindata.yaml文件, 打开traindata.yaml文件,如下所示:

在这里,只需修改 path 的值,其他的都不用改动(仔细看上面的 黄色字体),我提供的数据集默认都是到yolo文件夹,设置到 yolo 这一级即可,修改完后,返回train.py中,执行train.py。 1. 打开train.py,右键执行。
 1. 出现如下类似的界面代表开始训练了
1. 出现如下类似的界面代表开始训练了
 1. 训练完后的模型保存在runs/train文件夹下
1. 训练完后的模型保存在runs/train文件夹下

🌟 五、模型评估步骤
- 打开
val.py文件,如下图所示:
 1. 修改
1. 修改 model_pt的值,是自己想要评估的模型路径 1. 修改data_path,根据自己的实际情况修改,具体如何修改,查看上方模型训练中的修改步骤 - 修改
model.val()中的参数,按照自己的需求和电脑硬件的情况更改model.val(data=data_path, # 数据集路径
imgsz=300, # 图片大小,要和训练时一样
batch=4, # batch
workers=0, # 加载数据线程数
conf=0.001, # 设置检测的最小置信度阈值。置信度低于此阈值的检测将被丢弃。
iou=0.6, # 设置非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。有助于减少重复检测。
device=‘0’, # 使用显卡
project=‘runs/val’, # 保存路径
name=‘exp’, # 保存命名
)
- 1. 修改完后,即可执行程序,出现如下截图,代表成功(下图是示例,具体以自己的实际项目为准。)
 1. 评估后的文件全部保存在在
1. 评估后的文件全部保存在在
runs/val/exp...文件夹下

🌟 六、训练结果
我们每次训练后,会在 run/train 文件夹下出现一系列的文件,如下图所示:

如果大家对于上面生成的这些内容(confusion_matrix.png、results.png等)不清楚是什么意思,可以在我的知识库里查看这些指标的具体含义,示例截图如下:
**🌟完整代码 **
如果您希望获取博文中提到的所有实现相关的完整资源文件(包括测试图片、视频、Python脚本、UI文件、训练数据集、训练代码、界面代码等),这些文件已被全部打包。以下是完整资源包的截图:
您可以通过下方演示视频的视频简介部分进行获取,获取位置看下方图片文字:
🔥计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,远程协助,代码定制,私聊会回复!
✍🏻作者简介:机器学习,深度学习,卷积神经网络处理,图像处理
🚀B站项目实战:https://space.bilibili.com/364224477
😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+
🤵♂代做需求:@个人主页


















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











