







RetinaNet
https://blog.csdn.net/JNingWei/article/details/80038594
https://zhuanlan.zhihu.com/p/59910080
第二个上面写的focal loss比较好
交叉熵损失函数写的比较好的
https://blog.csdn.net/dcrmg/article/details/80010342?utm_source=blogkpcl14
因为focal loss是出自交叉熵(cross entropy loss)
交叉熵简介
https://blog.csdn.net/xg123321123/article/details/80781611
交叉熵描述了两个概率分布之间的距离,当交叉熵越小说明二者之间越接近。尽管交叉熵刻画的是两个概率分布之间的距离,但是神经网络的输出却不一定是一个概率分布。为此我们常常用Softmax回归将神经网络前向传播得到的结果变成概率分布。
https://zhuanlan.zhihu.com/p/61944055
知乎解释
cross entropy loss
其中:
- ——类别的数量;
- ——指示变量(0或1),如果该类别和样本的类别相同就是1,否则是0;
- ——对于观测样本属于类别
的预测概率。
来自:https://zhuanlan.zhihu.com/p/35709485
举个例子
假设是多分类问题,一共三个类别。M= 3
| ground truth( | class 1 | class 2 | class 3 |
| sample 1 | 0 | 1 | 0 |
模型预测值
| model predict( | class 1 | class 2 | class 3 |
| sample 1 | 0.2 | 0.3 | 0.5 |
其实可以直接写出来只有ground truth中类别为1的才会计算在loss里面,只对 ground_truth所对应的那一个单类进行响应计算,loss可以直接写成
不过现在都是使用balanced cross-entropy loss的,定义如下
这样做的好处是
https://blog.csdn.net/panglinzhuo/article/details/77131063
由于one-stage detecor训练时正负样本数目相差较大,常见的做法就是给正负样本加上权重,给数量较少的正样本的loss更大的权重,减小负样本loss的权重。
Focal Loss
focal loss的公式
是不同类别的分类概率,
是个大于0的值,
是个[0,1]间的小数,
和
都是固定值,不参与训练。从表达式可以看出:
- 无论是前景类还是背景类,
越大,权重
就越小。也就是说easy example可以通过权重进行抑制。换言之,当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。
用于调节positive和negative的比例,前景类别使用
时,对应的背景类别使用
;
和
、
时,ResNet-101+FPN作为backbone的结构有最优的性能。
此外作者还给了几个实验结果:
- 在计算
- Focal Loss的公式并不是固定的,也可以有其它形式,性能差异不大,所以说Focal Loss的表达式并不crucial。
在训练初始阶段因为positivie和negative的分类概率基本一致,会造成公式1起不到抑制easy example的作用,为了打破这种情况,作者对最后一级用于分类的卷积的bias(具体位置见图2)作了下小修改,把它初始化成一个特殊的值 。
在论文中取
,这样做能在训练初始阶段提高positive的分类概率。
focal loss的解决的问题
究其原因,就是因为one-stage受制于万恶的 “类别不平衡” 。
- 什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的 bbox属于background。
- “类别不平衡”又如何会导致检测精度低呢?
因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也 可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
- 那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN罩着。
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。 经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最 初生成的anchor那样夸张了。就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
不过,其实two-stage系的detector也不能完全避免这个问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成 的影响。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分 类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖 慢了。
- 那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标 签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失 败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
TF实现
神经网络的输出,也就是前向传播的输出可以通过Softmax回归变成概率分布,之后就可以使用交叉熵函数计算损失了。
交叉熵一般会跟Softmax一起使用,在tf中对这两个函数做了封装,就是 tf.nn.softmax_cross_entropy_with_logits 函数,可以直接计算神经网络的交叉熵损失。
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)
其中 y 是网络的输出,y_ 是期望输出。
针对分类任务中,正确答案往往只有一个的情况,tf提供了更加高效的 tf.nn.sparse_softmax_cross_entropy_with_logits 函数来求交叉熵损失。
均方误差
与分类任务对应的是回归问题,回归问题的任务是预测一个具体的数值,例如雨量预测、股价预测等。回归问题的网络输出一般只有一个节点,这个节点就是预测值。这种情况下就不方便使用交叉熵函数求损失函数了。
回归问题中常用的损失函数式均方误差(MSE,mean squared error),定义如下:
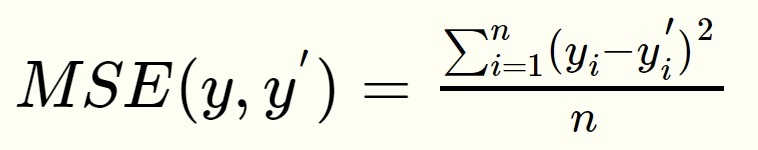
均方误差的含义是求一个batch中n个样本的n个输出与期望输出的差的平方的平均值。
tf中实现均方误差的函数为:
mse = tf.reduce_mean(tf.square(y_ - y))
在有些特定场合,需要根据情况自定义损失函数,例如对于非常重要场所的安检工作,把一个正常物品错识别为危险品和把一个危险品错识别为正常品的损失显然是不一样的,宁可错判成危险品,不能漏判一个危险品,所以就要在定义损失函数的时候就要区别对待,对漏判加一个较大的比例系数。在tf中可以通过以下函数自定义:
loss = tf.reduce_sum(tf.select(tf.greater(v1,v2),loss1,loss2))















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









