






llama.cpp 的主要目标是在各种硬件(本地和云端)上以最少的设置和最先进的性能实现 LLM 推理。
https://github.com/ggerganov/llama.cpp
llama-cpp-python 是 llama.cpp 库的简单 Python 绑定。
https://github.com/abetlen/llama-cpp-python
llama-cpp-python 提供了:
-
通过 ctypes 接口对 C API 进行低级访问。
-
用于文本完成的高级 Python API
-
- 类似 OpenAI 的 API
- LangChain 兼容性
- LlamaIndex 兼容性
-
OpenAI 兼容的 Web 服务器
-
- 本地 Copilot 替换
- 函数调用支持
- Vision API 支持
- 多种模型
功能很强大,我们在本文只需要学习如何在本地使用 llama-cpp-python 构建一个类似 OpenAI 的 API,并在 LangChain 框架中使用这个 API 提供的 LLM。
首先我们去 HuggingFace 上下载一个中文版的 8B Llama3.1 量化模型,下载链接:
https://huggingface.co/shenzhi-wang/Llama3.1-8B-Chinese-Chat/blob/main/gguf/llama3.1_8b_chinese_chat_q8_0.gguf
https://huggingface.co/shenzhi-wang/Llama3.1-8B-Chinese-Chat
什么是量化?请看此前的文章:想要学习大语言模型中的量化吗?
下载完毕之后,打开终端,运行:
python -m llama_cpp.server --model C:\Home\Documents\Projects\models\Llama\llama3.1_8b_chinese_chat_q8_0.gguf
看到这个输出就表示成功了:

访问:http://localhost:8000/docs 就可以访问 API 的接口文档了。
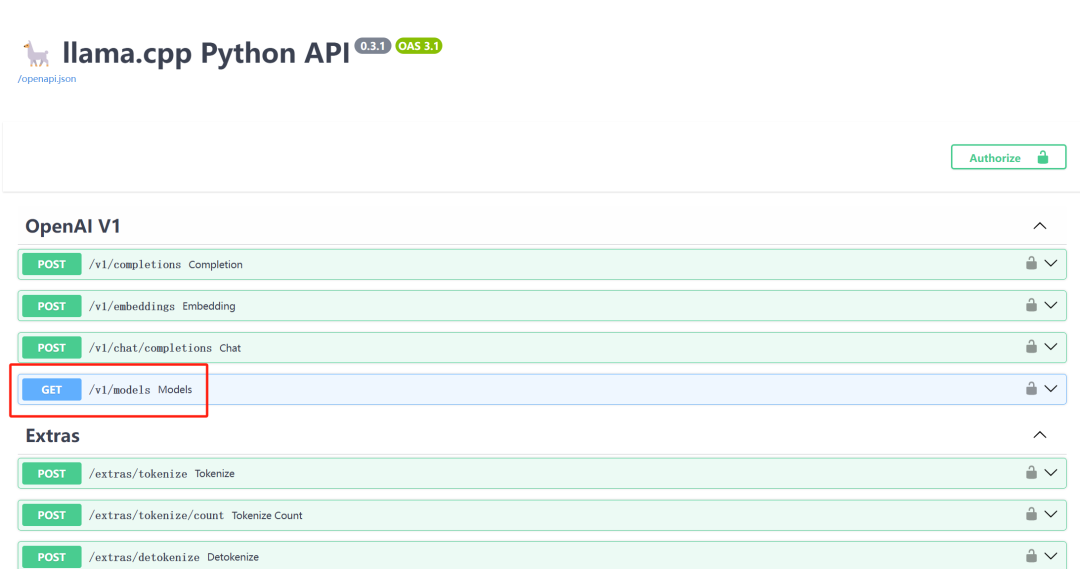
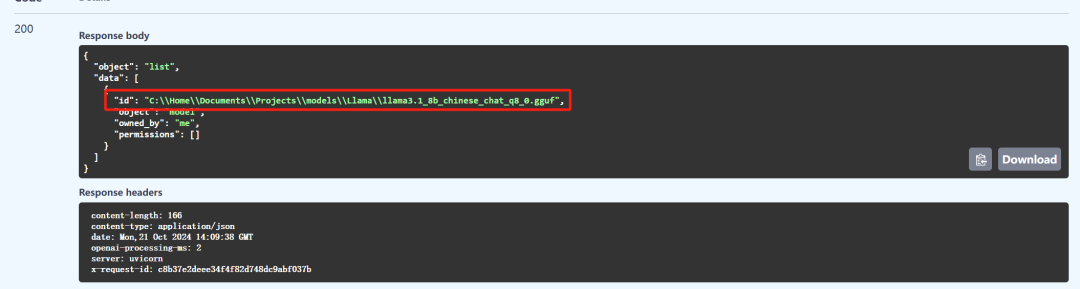
/v1/models GET 方法会返回当前可用的模型 ID:
现在我们就可以使用 OpenAI 的本地平替了:
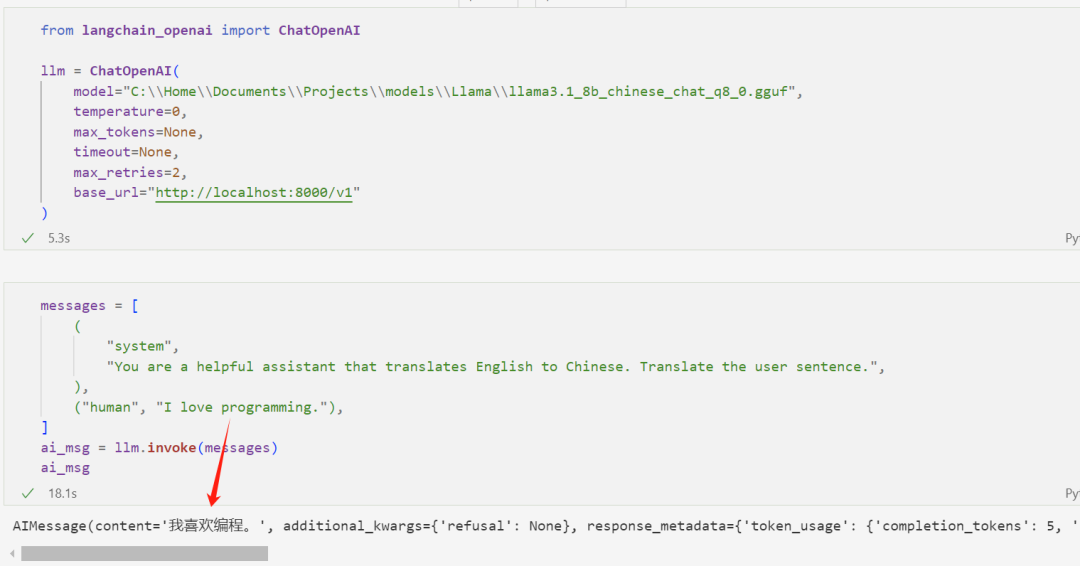
如上图所示,模型能够将英文翻译成中文。注意,我仅指定了模型服务的 base_url,而不用指定 api_key。
理论上,LangChain 官方关于使用 OpenAI 的操作都能使用 Llama.Cpp + 合适的开源模型来替代。
如果你不想单独启动一个 llama.cpp 服务的话,你也可以直接在 LangChain 中使用本地 LLM。
为了开始并使用下面显示的所有功能,我们建议使用已针对工具调用进行微调的模型。我这里使用的是 NousResearch/Hermes-3-Llama-3.1-8B。
首先我们需要初始化模型对象:
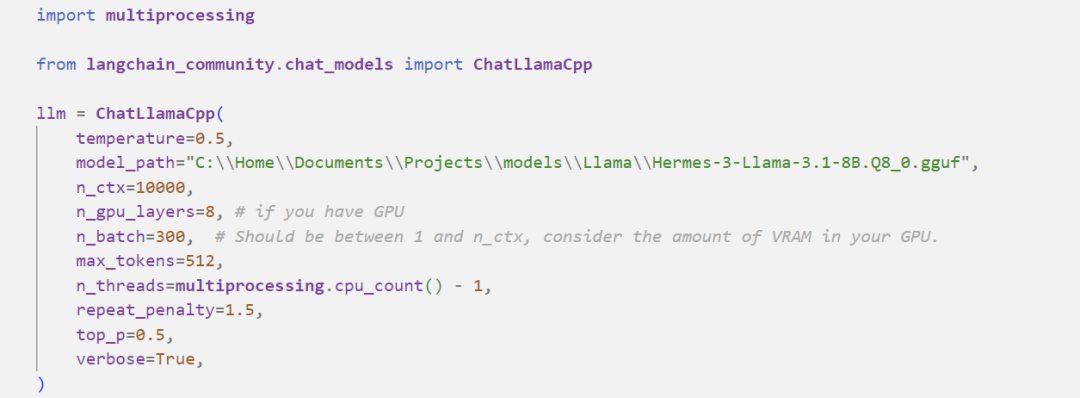
然后我们就可以调用模型:
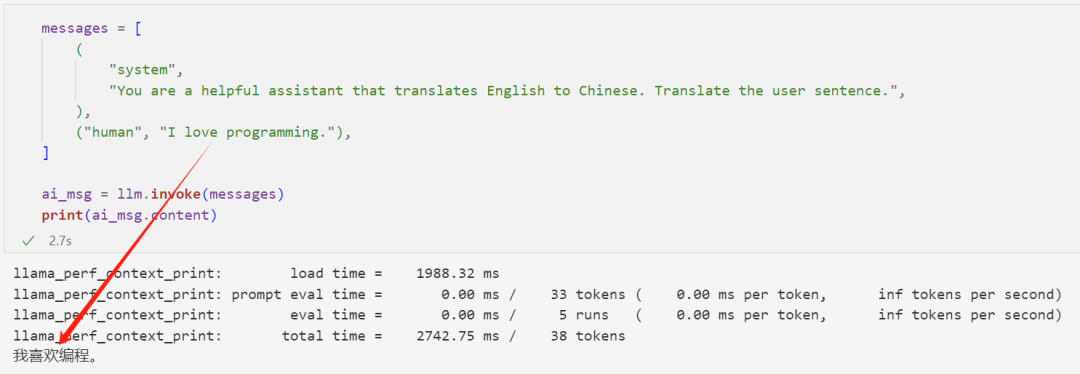
翻译正确。
我们也可以将模型和提示模板链接起来:

如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









