






本文使用 Dify v0.10.0+ 和 RAGFlow v0.12.0+ 版本(源码运行)。Dify 中的 RAG 一直被诟病,现在 Dify 提供了外部知识库 API,这样就可以连接到 Dify 之外的知识库并从中检索知识。第一个问题是 API 规范,包括接口格式、输入和输出参数等。第二个问题是哪些外部知识库支持该 API 呢?理论上讲只要支持 API 规范都是可行的。目前,官网有介绍如何使用 AWS Bedrock 知识库的。本文重点介绍 Dify 连接 RAGFlow 外部知识库。Dify通过API调用RAGFlow外部知识库:https://z0yrmerhgi8.feishu.cn/wiki/DrUqwbIXmicVI4kzYzJcQesGnee
一.Dify 连接 RAGFlow 操作
1.添加外部知识库 API
输入 Name,API Endpoint 和 API Key,如下所示:
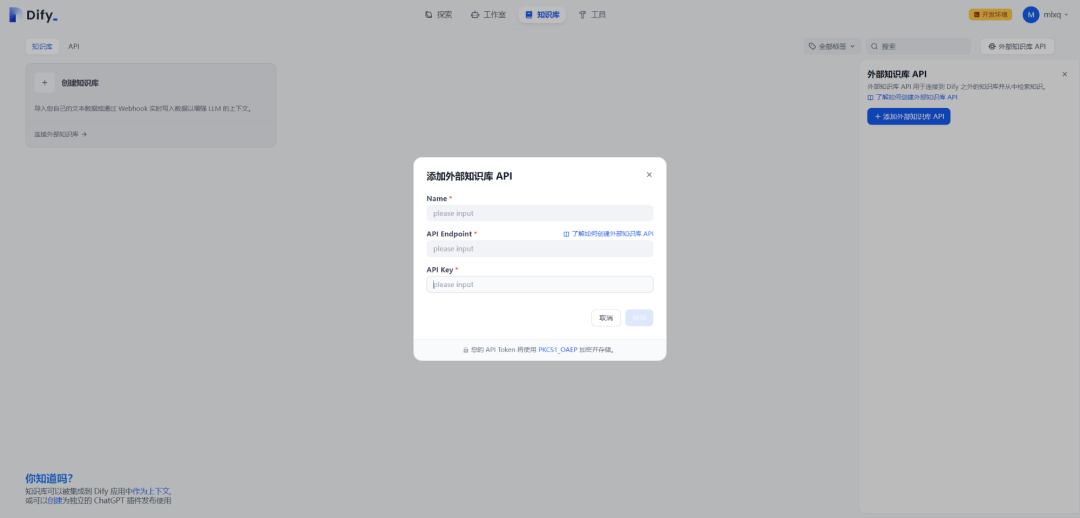
(1)Name:中英文均可。
(2)API Endpoint:http://127.0.0.1/api/v1/dify
(3)API Key:XXX
2.添加外部知识库接口
主要调用/datasets/external-knowledge-api 的 POST 接口,如下所示:
(1)Payload 内容
{
"name": "外部知识库",
"settings": {
"endpoint": "http://127.0.0.1:9380/api/v1/dify/retrieval",
"api_key": "ragflow-XXX"
}
}
(2)Response 结果
{
"id": "22ae908a-8f54-49dc-be77-4ff8991efbb6",
"tenant_id": "7bdb51d6-f390-4b23-a59e-9cdbe2e93136",
"name": "\u5916\u90e8\u77e5\u8bc6\u5e93",
"description": "",
"settings": {
"endpoint": "http://127.0.0.1:9380/api/v1/dify/retrieval",
"api_key": "ragflow-MwYmU3Zjg2OGY4YjExZWZiZGU1MDAxNT"
},
"dataset_bindings": [],
"created_by": "ebbf25be-ec85-4d68-9dd2-5bc2ee2855e4",
"created_at": "2024-10-22T01:41:04"
}
3.连接外部知识库
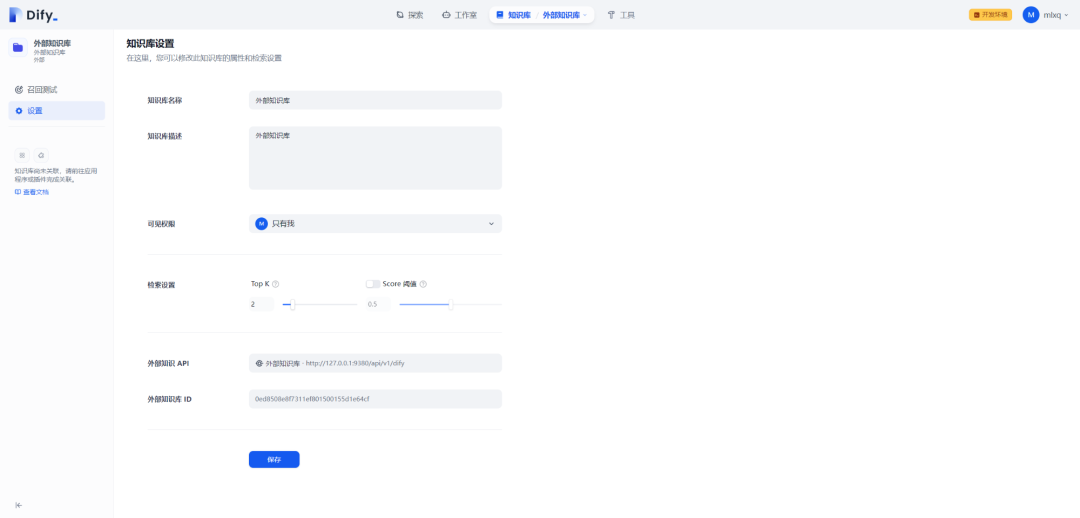
填写外部知识库名字、描述、API 和 ID 等信息,并且设置召回参数,如下所示:
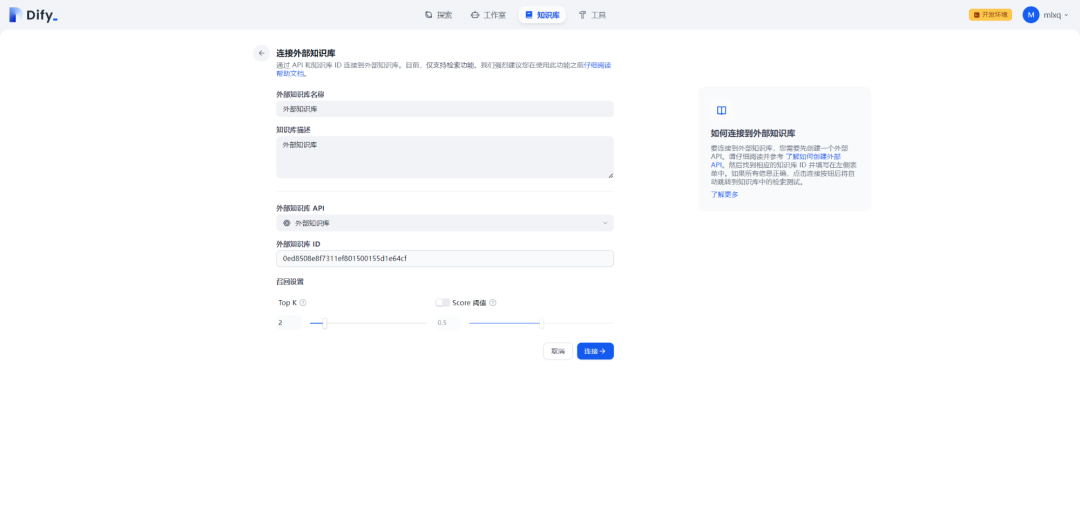
(1)外部知识库名字:外部知识库
(2)外部知识库描述:外部知识库
(3)外部知识库 API:外部知识库
(4)外部知识库 ID:XXX
(5)召回设置 Top K:默认 2
(6)召回设置 Score 阈值:默认 0.5
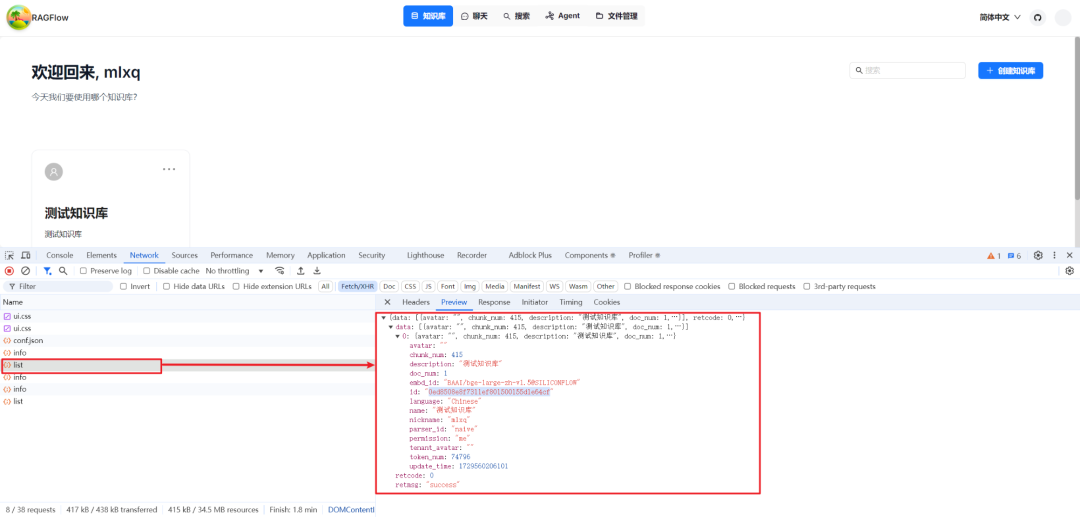
没找到外部知识库 ID 在哪里看,直接看的 list 接口的 Response 的 id,如下所示:
4.知识库设置
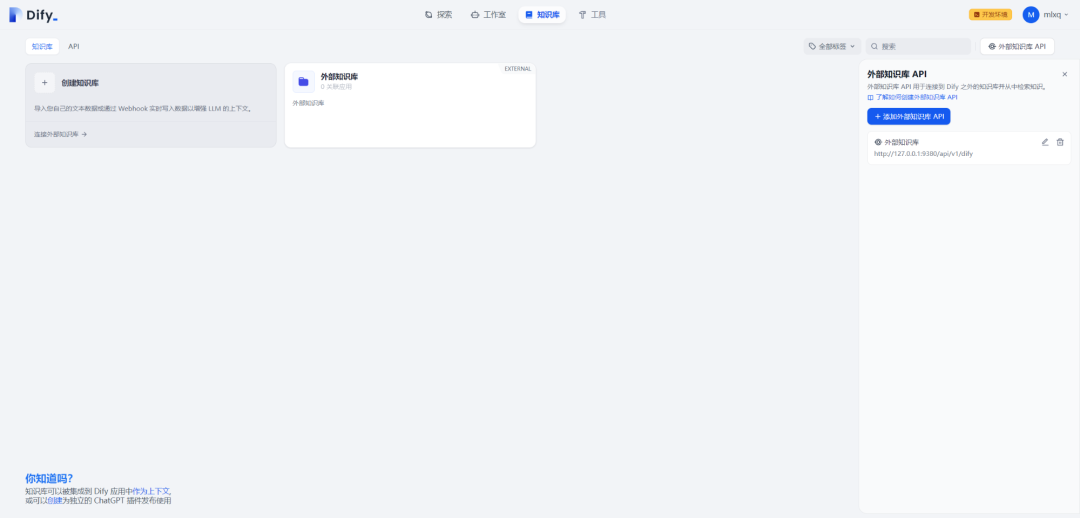
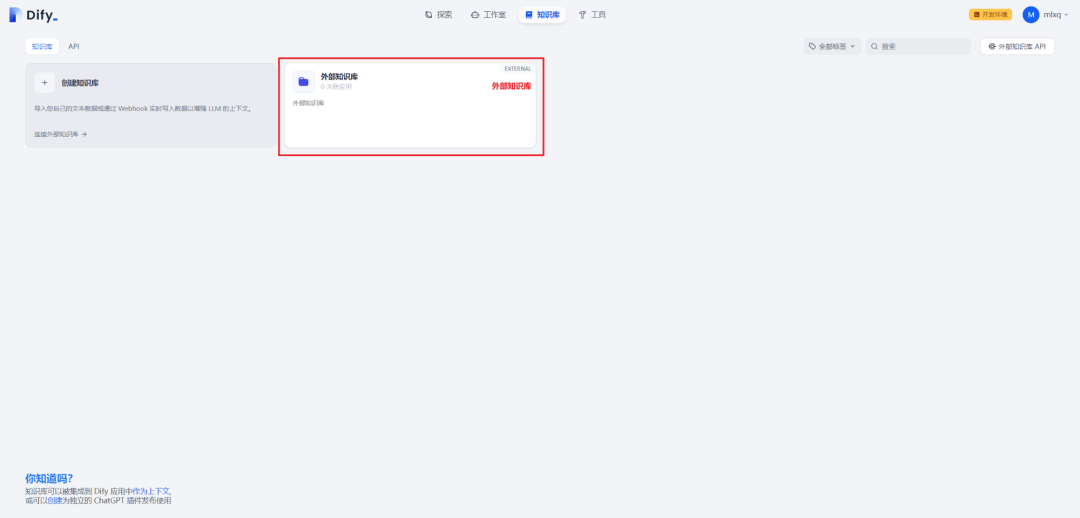
在知识库页面可看到外部知识库,如下所示:
在知识库设置页面,可以对外部知识库进行信息修改,如下所示:
二.测试 RAGFlow 接口
1.使用 Postman 测试
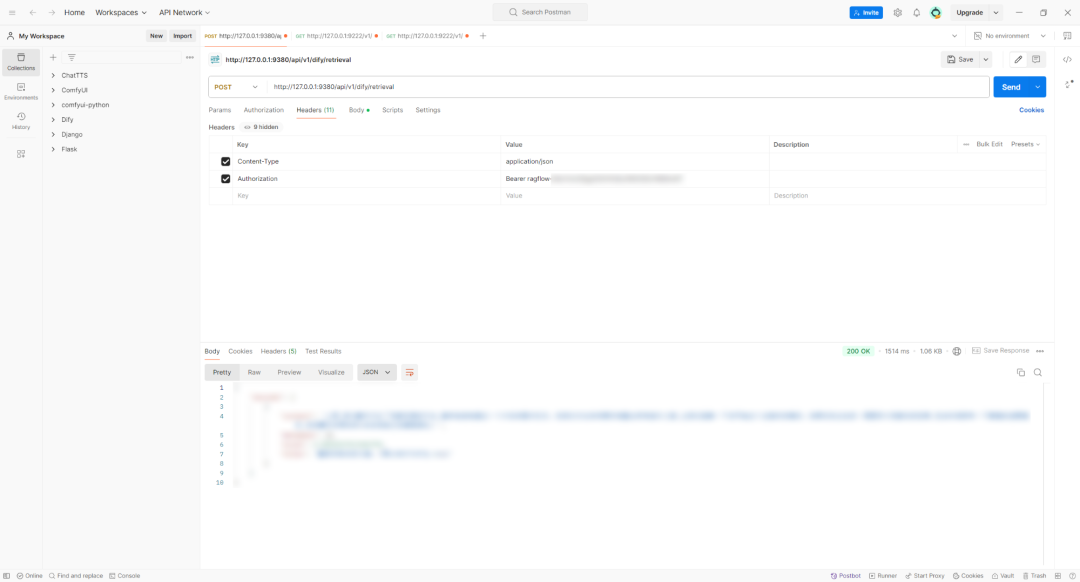
设置 Headers,如下所示:
设置 Body(raw+JSON),如下所示:
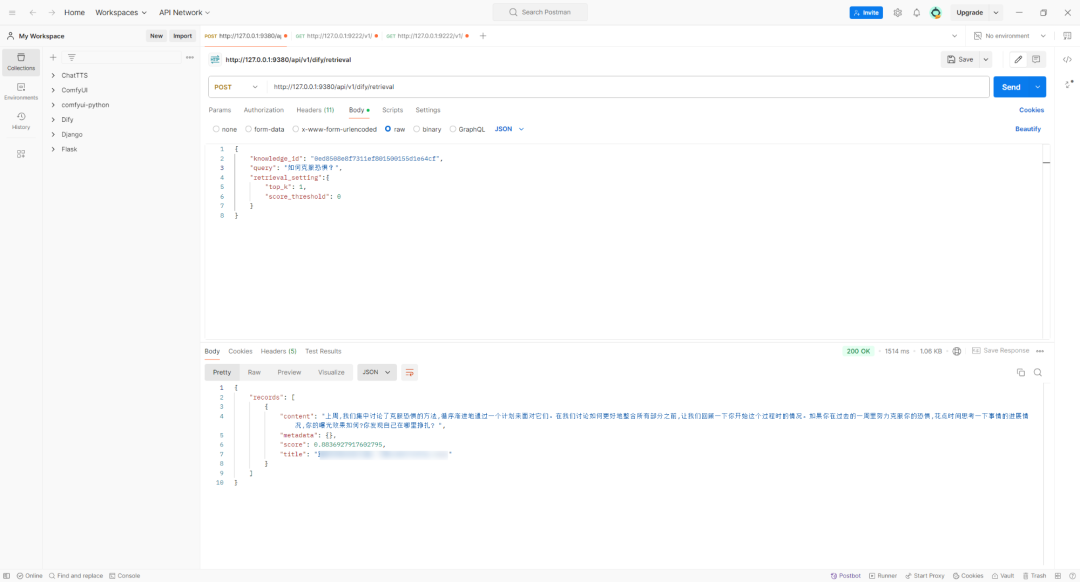
{
"knowledge_id": "0ed8508e8f7311ef801500155d1e64cf",
"query": "如何克服恐惧?",
"retrieval_setting":{
"top_k": 1,
"score_threshold": 0
}
}
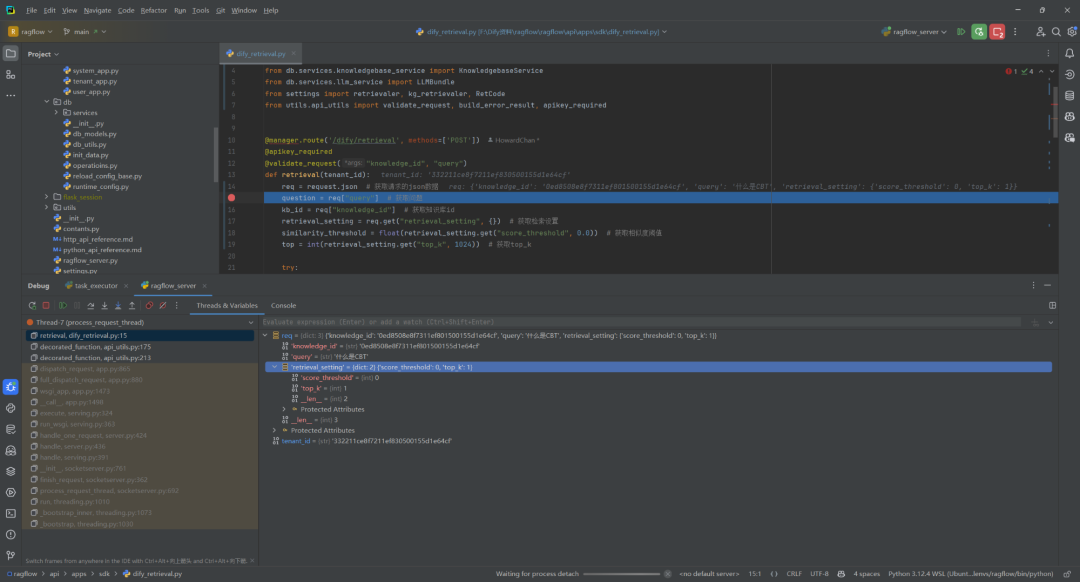
2.调试接口
通过 Debug 可看到 Request 的参数,如下所示:
三.Dify 使用外部知识库召回测试
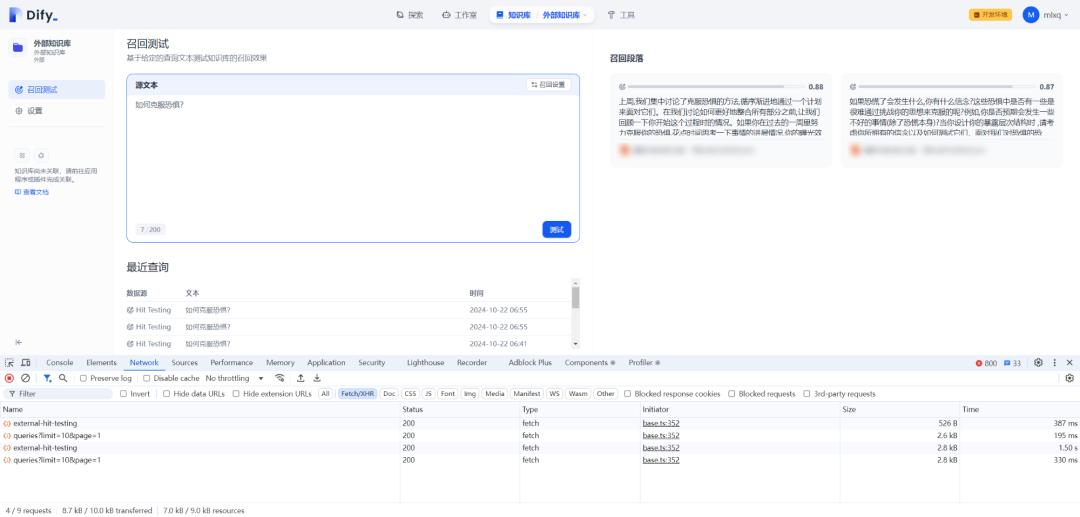
1.召回测试
理想过程是输入、测试和输出,如下所示:
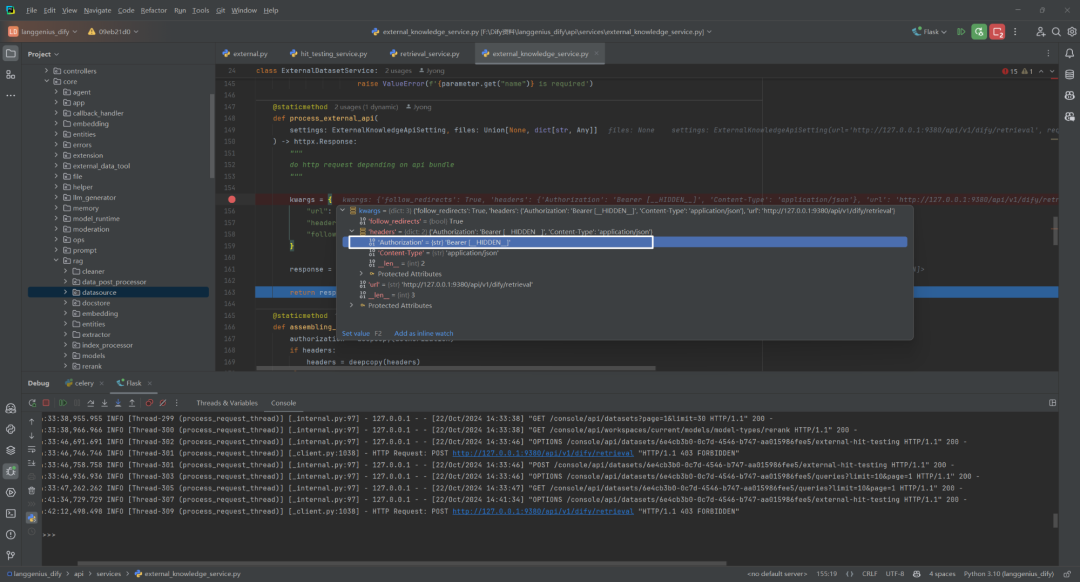
2.接口 403 原因
但在召回测试接口 /datasets//external-hit-testing 时候发现 403。看了下发现 Authorization 内容为 Bearer [__HIDDEN__],如下所示:
顺便看了下前端代码,如下所示:
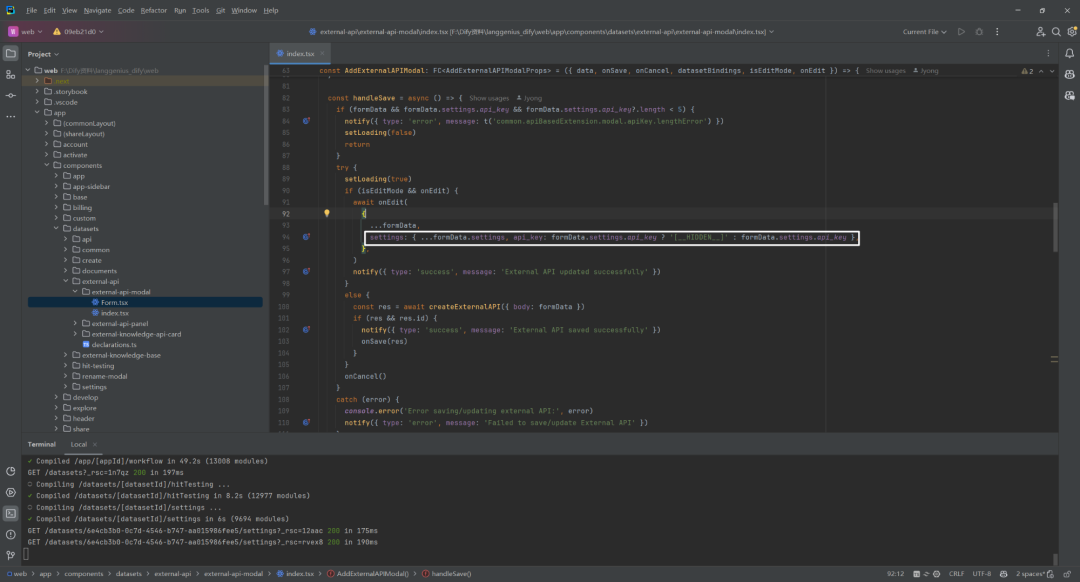
在 external_knowledge_apis 数据库表的 settings 字段就是存储的 Bearer [__HIDDEN__]。推测 Bearer [__HIDDEN__] 的目的主要是为了 隐藏敏感信息,即 API 请求中的 身份验证令牌(API key 或 Token)。这是为了防止在公开或共享的场景下泄露机密的 API 密钥,确保安全性。[__HIDDEN__] 只是一个占位符,实际的 API 密钥会替换该部分。
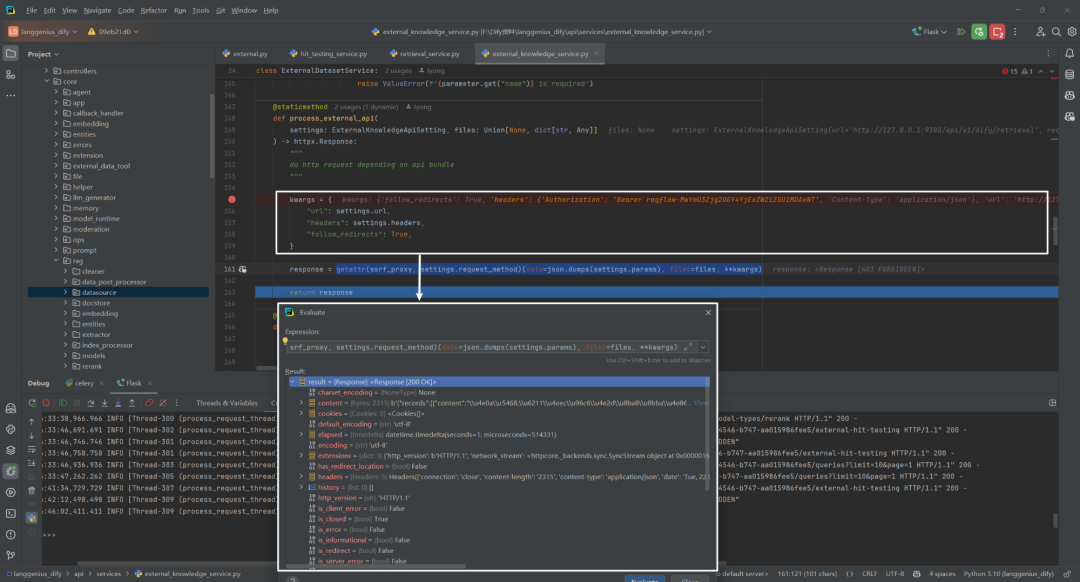
为了明证推测,通过 [__HIDDEN__] 在 Dify 源码中进行了检索,如下所示:
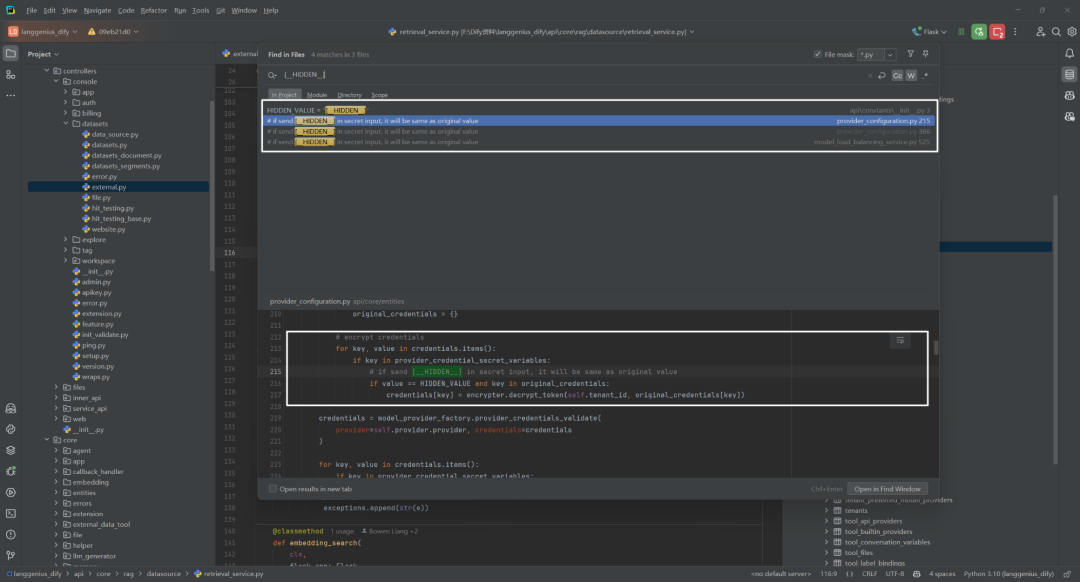
这段代码的主要目的是 加密和解密凭据,并处理隐藏的凭据([__HIDDEN__])在输入时保持不变的情况。如下所示:
# encrypt credentials
for key, value in credentials.items():
if key in provider_credential_secret_variables:
# if send [__HIDDEN__] in secret input, it will be same as original value
if value == HIDDEN_VALUE and key in original_credentials:
credentials[key] = encrypter.decrypt_token(self.tenant_id, original_credentials[key])
因此,应该是在调用外部知识库检索的时候,这个部分还没完善。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









