






今天最大的瓜莫过于:斯坦福 Llama3-V PK 清华 MiniCPM-Llama3-V-2.5,详细证据:
https://github.com/OpenBMB/MiniCPM-V/issues/196
吃瓜之余,来看一下多模态大模型架构演变!
一篇优秀的论文综述了多模态AI架构——包含了一个全面的分类法和对任意到任意模态模型发展的分析。
📌 综合分类法:首次明确识别并分类四种广泛的多模态架构类型(A型、B型、C型、D型),有助于简化对模型架构的理解和选择。
📌 比较分析:对每种架构类型的优势和劣势进行了详细审查,考虑了训练数据、计算需求、可扩展性和模态整合。
📌 任意到任意模态模型:突出了构建任意到任意模态模型所涉及的主要架构类型,有助于模型的选择和发展。
综合分类法
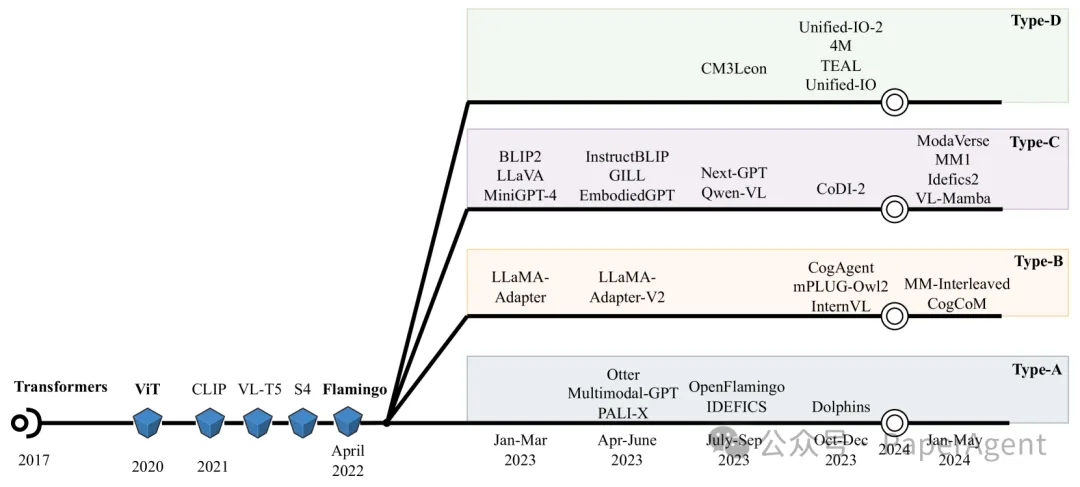
按四种提出的架构类型分组的多模态模型发展时间线
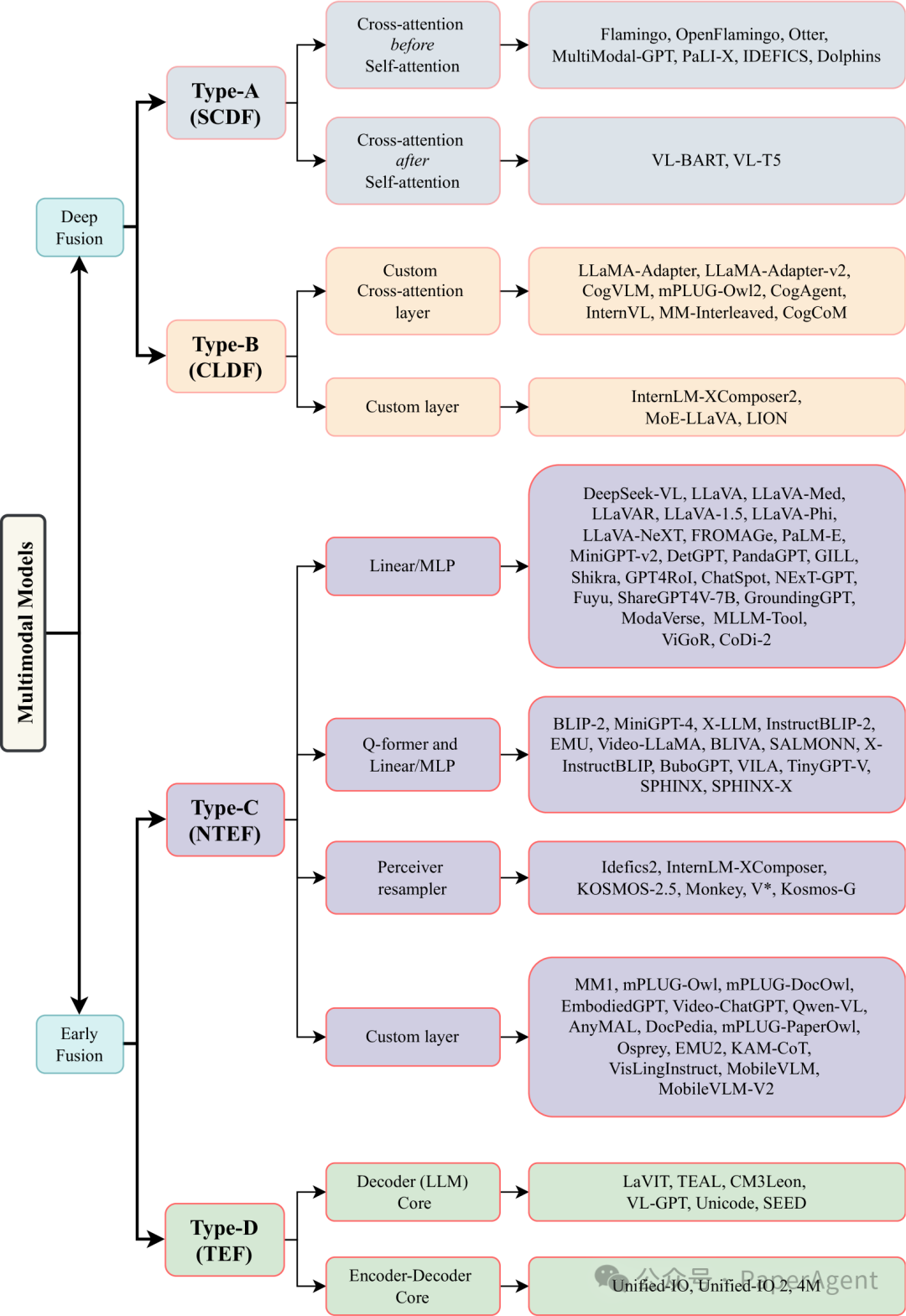
多模态模型架构的分类。四种不同类型的多模态架构及其子类型被概述。各种模型被系统地分类到类型和子类型中。深度融合:类型A和类型B在模型的内部层融合多模态输入。早期融合:类型C和类型D在输入阶段促进融合。类型A使用标准的交叉注意力机制,而类型B则利用定制设计的交叉注意力或专门的层。类型C是一种非标记化的多模态模型架构,而类型D则采用输入标记化(离散标记)。SCDF:基于标准交叉注意力的深度融合。CLDF:基于定制层的深度融合。NTEF:非标记化的早期融合。TEF:标记化的早期融合。
比较分析
- Type-A (SCDF:Standard Cross-Attention based Deep Fusion) - 标准交叉注意力深度融合:使用标准的交叉注意力层在模型的内部层进行多模态输入的深度融合。这种类型可能在自注意力层之前或之后添加交叉注意力层。
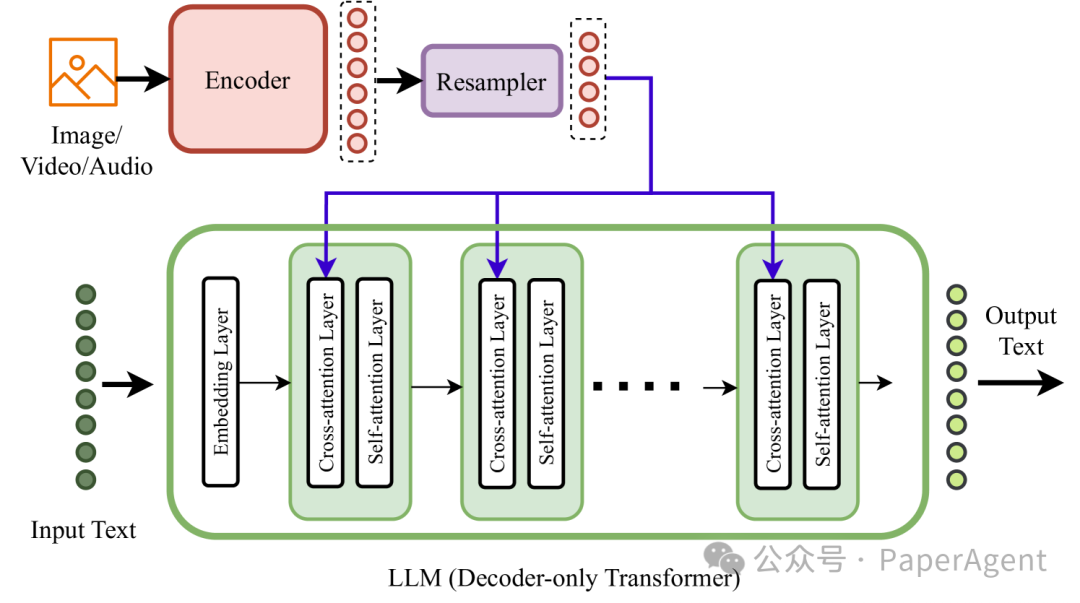
类型A多模态模型架构。 输入模态通过使用标准交叉注意力层深入融合到LLM的内部层。交叉注意力可以添加在自注意力层之前或之后。模态特定的编码器处理不同的输入模态。使用重采样器来输出固定数量的模态(视觉/音频/视频)标记,给定输入时变量数量的输入标记。
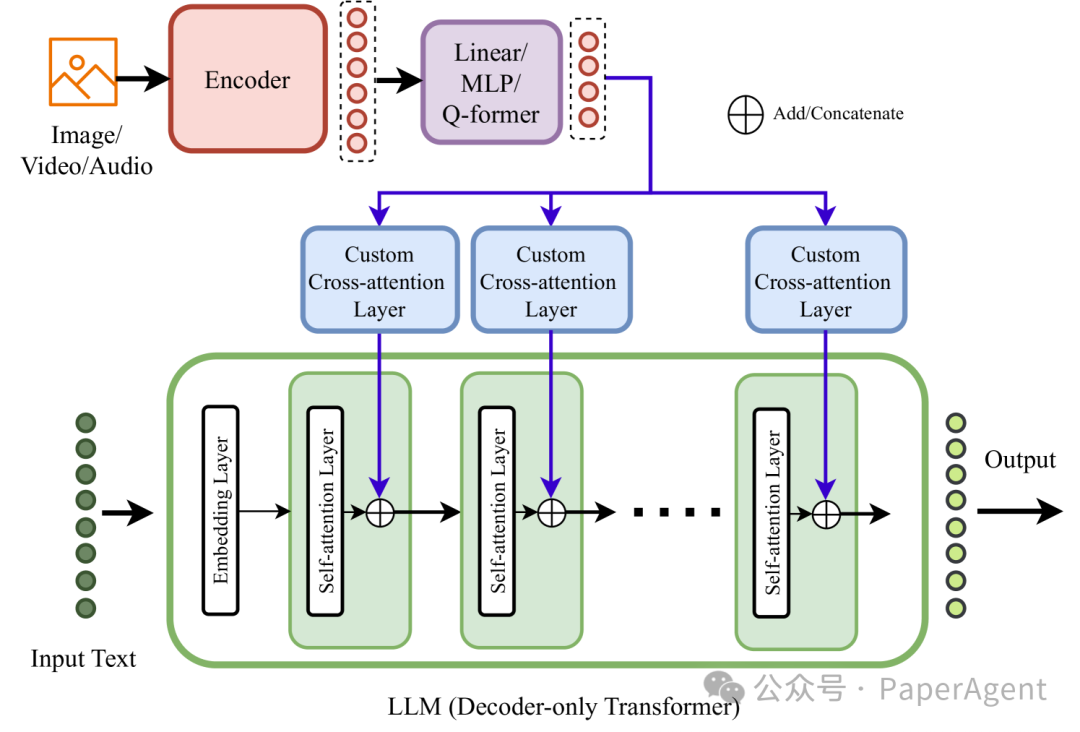
- Type-B (CLDF:Custom Layer based Deep Fusion) - 自定义层深度融合:使用定制设计的层(例如自定义交叉注意力层或其他特定层)在模型的内部层进行多模态输入的深度融合。
类型B多模态模型架构。 输入模态通过使用定制设计的层深入融合到LLM的内部层。定制交叉注意力层或其他定制层用于模态融合。线性层/多层感知器/Q-former被用来将不同模态与解码层对齐。
- Type-C (NTEF:Non-Tokenized Early Fusion) - 非标记化早期融合:在模型的输入阶段进行多模态输入的早期融合,使用模态特定的编码器,但不涉及模型内部层的深度融合。这种类型可能使用线性层/MLP、Q-former、Perceiver resampler或自定义可学习层来连接编码器输出和LLM。
类型C多模态模型架构。(非标记化的)输入模态直接输入到模型的输入端,而不是其内部层,从而实现早期融合。不同类型的模块被用来将模态编码器的输出连接到LLM(模型),例如线性层/多层感知器、Q-former和线性层/多层感知器、Perceiver重采样器、定制的可学习层。
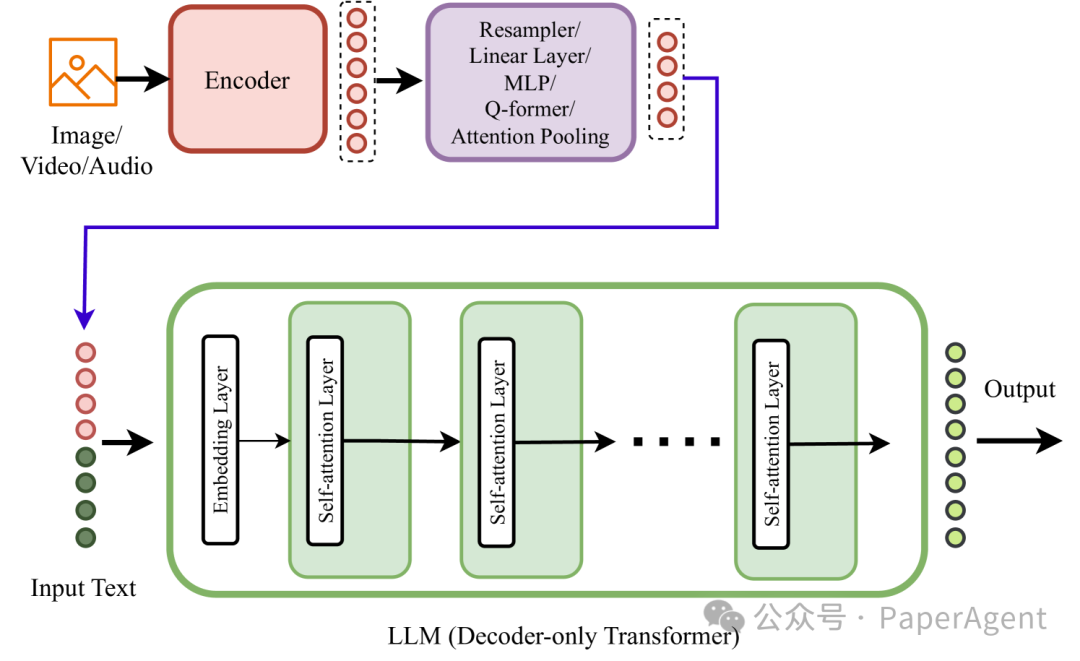
- Type-D (TEF:Tokenized Early Fusion ) - 标记化早期融合:与Type-C类似,在输入阶段进行早期融合,但使用标记化技术(如tokenizers)来处理模态。
类型D多模态模型架构。 标记化的输入模态直接输入到模型的输入端。在这个架构中,使用仅解码器变换器或编码器-解码器风格的变换器作为多模态变换器。
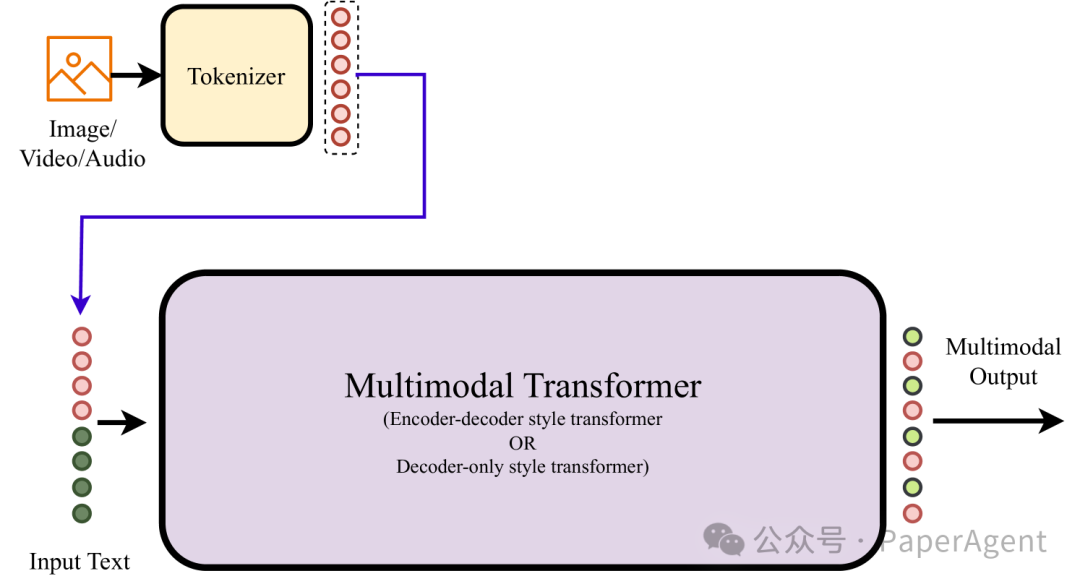
任意到任意模态模型
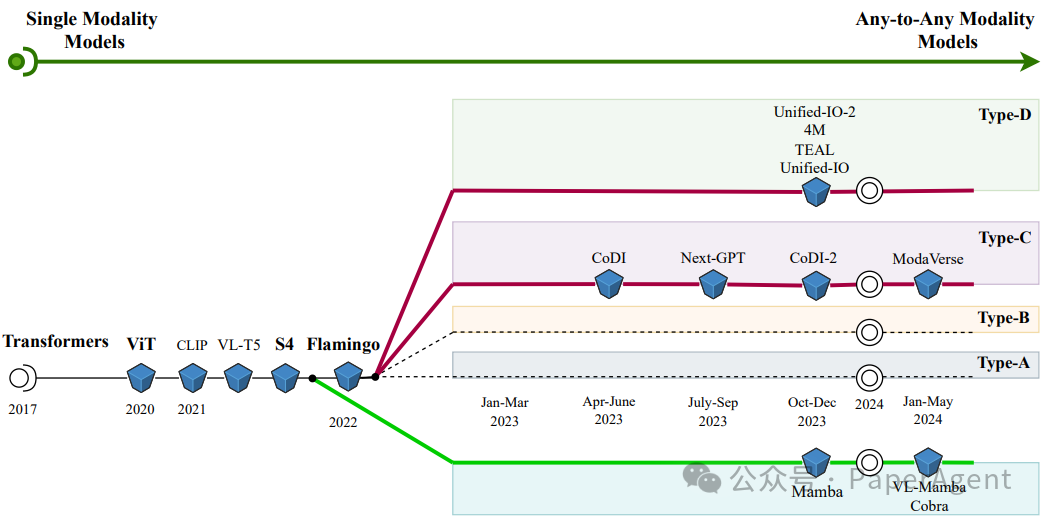
任意到任意多模态模型的发展时间线。 从单一模态模型(左侧)到任意到任意模态模型(右侧)的演变过程被描绘出来。图中注明了属于C型和D型的任意到任意多模态模型。底部的绿线展示了非基于变换器的模型(如SSM,状态空间模型)的另一条发展时间线。Mamba是一个语言模型。VL-mamba和Cobra是视觉-语言模型。
https://arxiv.org/pdf/2405.17927
The Evolution of Multimodal Model Architectures
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









