







 本文介绍了在大数据时代,如何利用并行计算应对处理效率挑战。重点讲述了Python的multiprocessing库,包括进程、线程、全局解释器锁GIL、进程池、管道与队列、锁和共享内存等内容,提供了实战示例,展示了如何通过多进程实现并行计算,提升程序执行效率。
本文介绍了在大数据时代,如何利用并行计算应对处理效率挑战。重点讲述了Python的multiprocessing库,包括进程、线程、全局解释器锁GIL、进程池、管道与队列、锁和共享内存等内容,提供了实战示例,展示了如何通过多进程实现并行计算,提升程序执行效率。
一、大数据时代的现状
当前我们正处于大数据时代,每天我们会通过手机、电脑等设备不断的将自己的数据传到互联网上。据统计,YouTube上每分钟就会增加500多小时的视频,面对如此海量的数据,如何高效的存储与处理它们就成了当前最大的挑战。
但在这个对硬件要求越来越高的时代,CPU却似乎并不这么给力了。自2013年以来,处理器频率的增长速度逐渐放缓了,目前CPU的频率主要分布在34GHz。这个也是可以理解的,毕竟摩尔定律都生效了50年了,如果它老人家还如此给力,那我们以后就只要静等处理器频率提升,什么计算问题在未来那都不是话下了。实际上CPU与频率是于能耗密切相关的,我们之前可以通过加电压来提升频率,但当能耗太大,散热问题就无法解决了,所以频率就逐渐稳定下来了,而Intel与AMD等大制造商也将目标转向了多核芯片,目前普通桌面PC也达到了48核。
二、面对挑战的方法
咱们有了多核CPU,以及大量计算设备,那我们怎么来用它们应对大数据时代的挑战了。那就要提到下面的方法了。
2.1 并行计算
并行(parallelism)是指程序运行时的状态,如果在同时刻有多个“工作单位”运行,则所运行的程序处于并行状态。图一是并行程序的示例,开始并行后,程序从主线程分出许多小的线程并同步执行,此时每个线程在各个独立的CPU进行运行,在所有线程都运行完成之后,它们会重新合并为主线程,而运行结果也会进行合并,并交给主线程继续处理。
图片
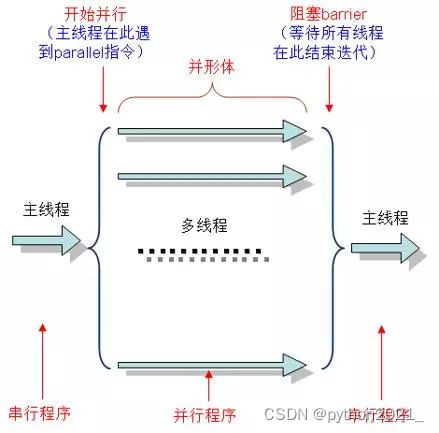
图一、多线程并行
图二是一个多线程的任务(沿线为线程时间),但它不是并行任务。这是因为task1与task2总是不在同一时刻执行,这个情况下单核CPU完全可以同时执行task1与task2。方法是在task1不执行的时候立即将CPU资源给task2用,task2空闲的时候CPU给task1用,这样通过时间窗调整任务,即可实现多线程程序,但task1与task2并没有同时执行过,所以不能称为并行。我们可以称它为并发(concurrency)程序,这个程序一定意义上提升了单个CPU的使用率,所以效率也相对较高。
图片
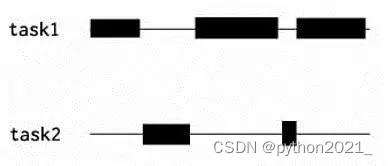
图二、多线程并发
并行编程模型:
数据并行(Data Parallel)模型:将相同的操作同时作用于不同数据,只需要简单地指明执行什么并行操作以及并行操作对象。该模型反映在图一中即是,并行同时在主线程中拿取数据进行处理,并线程执行相同的操作,然后计算完成后合并结果。各个并行线程在执行时互不干扰。
消息传递(Message Passing)模型:各个并行执行部分之间传递消息,相互通讯。消息传递模型的并行线程在执行时会传递数据,可能一个线程运行到一半的时候,它所占用的数据或处理结果就要交给另一个线程处理,这样,在设计并行程序时会给我们带来一定麻烦。该模型一般是分布式内存并行计算机所采用方法,但是也可以适用于共享式内存的并行计算机。
什么时候用并行计算:
多核CPU——计算密集型任务。尽量使用并行计算,可以提高任务执行效率。计算密集型任务会持续地将CPU占满,此时有越多CPU来分担任务,计算速度就会越快,这种情况才是并行程序的用武之地。
单核CPU——计算密集型任务。此时的任务已经把CPU资源100%消耗了,就没必要使用并行计算,毕竟硬件障碍摆在那里。
单核CPU——I/O密集型任务。I/O密集型任务在任务执行时需要经常调用磁盘、屏幕、键盘等外设,由于调用外设时CPU会空闲,所以CPU的利用率并不高,此时使用多线程程序,只是便于人机交互。计算效率提升不大。
多核CPU——I/O密集型任务。同单核CPU——I/O密集型任务。
2.2 改用GPU处理计算密集型程序
GPU即图形处理器核心(Graphics Processing Unit),它是显卡的心脏,显卡上还有显存,GPU与显存类似与CPU与内存。
GPU与CPU有不同的设计目标,CPU需要处理所有的计算指令,所以它的单元设计得相当复杂;而GPU主要为了图形“渲染”而设计,渲染即进行数据的列处理,所以GPU天生就会为了更快速地执行复杂算术运算和几何运算的。
GPU相比与CPU有如下优势:
强大的浮点数计算速度。
大量的计算核心,可以进行大型并行计算。一个普通的GPU也有数千个计算核心。
强大的数据吞吐量,GPU的吞吐量是CPU的数十倍,这意味着GPU有适合的处理大数据。
GPU目前在处理深度学习上用得十分多,英伟达(NVIDIA)目前也花大精力去开发适合深度学习的GPU。现在上百层的神经网络已经很常见了,面对如此庞大的计算量,CPU可能需要运算几天,而GPU却可以在几小时内算完,这个差距已经足够别人比我们多打几个比赛,多发几篇论文了。
2.3 分布式计算
说到分布式计算,我们就先说下下Google的3篇论文,原文可以直接点链接去下载:
GFS(The Google File System) :解决数据存储的问题。采用N多台廉价的电脑,使用冗余的方式,来取得读写速度与数据安全并存的结果。
MapReduce(Simplified Data Processing on Large Clusters) :函数式编程,把所有的操作都分成两类,map与reduce,map用来将数据分成多份,分开处理,reduce将处理后的结果进行归并,得到最终的结果。
BigTable(Bigtable: A Distributed Storage System for Structured Data) :在分布式系统上存储结构化数据的一个解决方案,解决了巨大的Table的管理、负载均衡的问题.
Google在2003~2006年发表了这三篇论文之后,一时之间引起了轰动,但是Google并没有将MapReduce开源。在这种情况下Hadoop就出现了,Doug Cutting在Google的3篇论文的理论基础上开发了Hadoop,此后Hadoop不断走向成熟,目前Facebook、IBM、ImageShack等知名公司都在使用Hadoop运行他们的程序。
分布式计算的优势:
可以集成诸多低配的计算机(成千上万台)进行高并发的储存与计算,从而达到与超级计算机媲美的处理能力。
三、用python写并行程序
在介绍如何使用python写并行程序之前,我们需要先补充几个概念,分别是进程、线程与全局解释器锁(Global Interpreter Lock, GIL)。
3.1 进程与线程
进程(process):
在面向线程设计的系统(如当代多数操作系统、Linux 2.6及更新的版本)中,进程本身不是基本运行单位,而是线程的容器。
进程拥有自己独立的内存空间,所属线程可以访问进程的空间。
程序本身只是指令、数据及其组织形式的描述,进程才是程序的真正运行实例。例如,Visual Studio开发环境就是利用一个进程编辑源文件,并利用另一个进程完成编译工作的应用程序。
线程(threading):
线程有自己的一组CPU指令、寄存器与私有数据区,线程的数据可以与同一进程的线程共享。
当前的操作系统是面向线程的,即以线程为基本运行单位,并按线程分配CPU。
进程与线程有两个主要的不同点,其一是进程包含线程,线程使用进程的内存空间,当然线程也有自己的私有空间,但容量小;其二是进程有各自独立的内存空间,互不干扰,而线程是共享内存空间。
图三展示了进程、线程与CPU之间的关系。在图三中,进程一与进程二都含有3个线程,CPU会按照线程来分配任务,如图中4个CPU同时执行前4个线程,后两个标红线程处于等待状态,在CPU运行完当前线程时,等待的线程会被唤醒并进入CPU执行。通常,进程含有的线程数越多,则它占用CPU的时间会越长。
图片
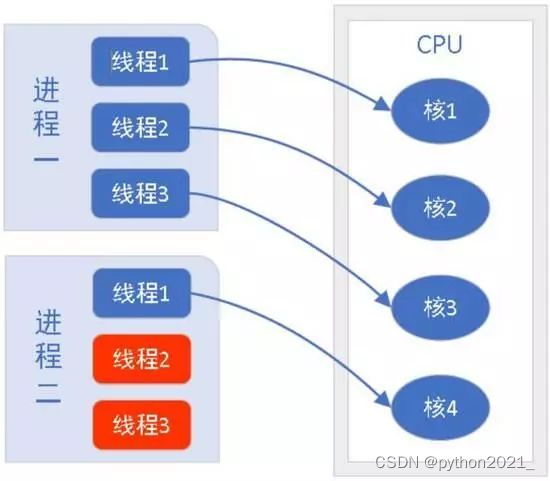
图三、进程、线程与CPU关系
3.2 全局解释器锁GIL:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









