







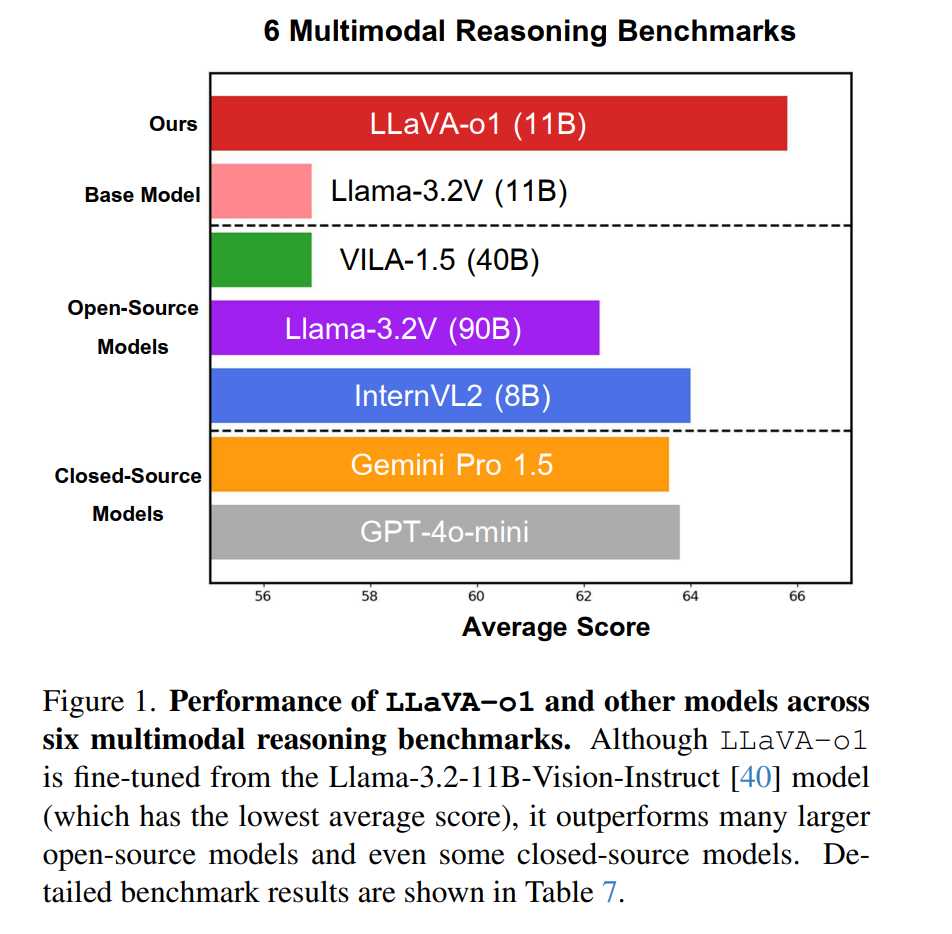
大型语言模型(LLMs)在推理能力上取得了显著进展,特别是在推理阶段通过扩展规模(如OpenAI的o1模型)体现了这一点。然而,当前的视觉语言模型(Vision-Language Models, VLMs)在进行系统化和结构化推理方面往往表现不足,尤其是在处理复杂的视觉问答任务时。在本研究中,我们提出了一种新颖的视觉语言模型 LLaVA-o1,该模型旨在实现自主的多阶段推理能力。与传统的链式思维(Chain-of-Thought)提示不同,LLaVA-o1能够独立执行一系列有序的阶段,包括摘要、视觉解释、逻辑推理以及结论生成。这种结构化的方法使得LLaVA-o1在推理密集型任务的精确性上实现了显著提升。
为实现这一目标,我们构建了 LLaVA-o1-100k 数据集,整合了来自多种视觉问答来源的样本,并提供了结构化推理标注。此外,我们提出了一种推理阶段级的束搜索(beam search)方法,用于在推理阶段实现高效的规模扩展。令人瞩目的是,仅使用10万条训练样本和简单但有效的推理扩展方法,LLaVA-o1不仅在多模态推理基准测试中超越了其基础模型 8.9% 的表现,还超越了包括 Gemini-1.5-pro、GPT-4o-mini 和 Llama-3.2-90B-Vision-Instruct 等更大规模甚至闭源的模型。
1. 引言
大型语言模型(LLMs),如 OpenAI 的 o1 [63],在系统化和深入推理方面展现了强大的能力,验证了推理阶段扩展对语言模型的有效性 [47]。然而,视觉能力对于使模型全面理解世界并扩展其认知能力同样重要 [6]。因此,开发一种能够集成语言与视觉,并支持高效、系统化和深度推理的多模态模型具有重要意义。
早期的开源视觉语言模型(VLMs)主要采用直接预测的方法 [21, 30, 32],即在接收到问题后直接生成简短的答案。这种直接响应范式的主要局限在于缺乏结构化的推理过程,使其在需要逻辑推理的任务中表现欠佳 [62]。最近的研究表明,结合链式思维(Chain-of-Thought, CoT)推理可以促进模型逐步推理,从而显著提升问答能力 [52]。然而,即使使用 CoT 推理,大多数 VLMs 在推理过程中仍然频繁地产生错误或幻觉式输出 [24, 31, 50]。
我们的研究发现,这些问题的主要原因在于现有 VLMs 推理过程的系统性和结构化不足。具体来说,系统性指的是模型不仅需要生成直接的推理链,还需要通过多阶段推理完成任务。结构化则指模型能够清晰地识别其当前所处的推理阶段,并理解每个阶段的主要任务。然而,现有的 VLMs 通常在响应时未能充分组织问题和现有信息,并且经常在推理过程中偏离逻辑路径,直接得出结论后再尝试为其辩解。由于语言模型以逐词生成响应,一旦引入错误的结论,模型通常沿着错误的推理路径继续下去。
OpenAI 的 o1 [63] 通过让模型独立进行系统化和结构化的语言推理,有效解决了这些问题。在此基础上,我们设计了 LLaVA-o1。尽管社区对 OpenAI o1 的机制进行了初步探索 [42, 54],该模型仍然是一个技术细节未知的“黑箱”。本研究展示了一种通过监督微调增强模型逐步推理能力的潜在方法。具体来说,LLaVA-o1 能够生成四个明确阶段:摘要、描述、推理和结论,每个阶段在推理过程中都有其独特的作用:
-
摘要:简要概述模型需要完成的任务。
-
描述:对图像中与问题相关的部分进行描述(如果存在图像)。
-
推理:对问题进行系统化和详细的分析。
-
结论:基于前述推理生成最终的简要答案。
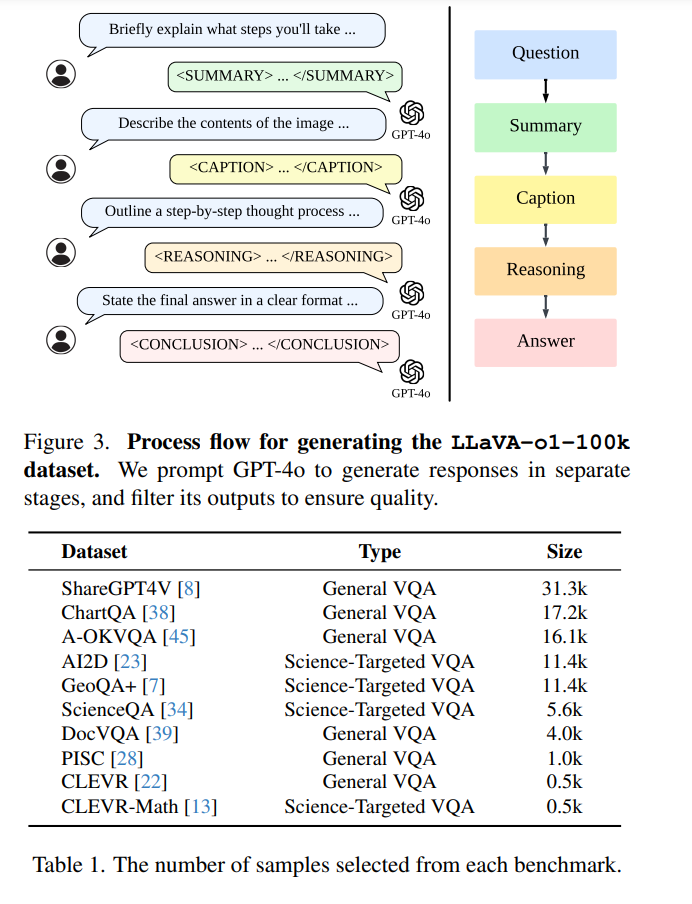
为了加强对 CoT 过程的理解,LLaVA-o1 在每个阶段添加了专用标签(如 <SUMMARY>...</SUMMARY>)来标记每个阶段的起点和终点。这种标注使模型在推理过程中保持清晰,与传统 CoT 推理允许模型自由思考不同,我们的方法促进了结构化思考,先组织问题和已知信息,再进行详细的推理过程,最后得出结论。为实现这一目标,我们利用 GPT-4o [3] 逐阶段生成响应,构建了 LLaVA-o1-100k 数据集,并通过监督微调对模型进行训练。
LLaVA-o1 的结构化推理还支持高效的推理阶段扩展。与传统的扩展方法(如最佳 N 采样 [4, 51] 和句子级束搜索 [16, 49])相比,LLaVA-o1 使用了一种新颖的阶段级束搜索方法,能够在每个推理阶段生成多个候选结果,并选择最佳结果继续生成过程。
我们在多个多模态推理基准上进行了实验,包括 MMStar [9]、MMBench [33]、MMVet [60]、MathVista [35]、AI2D [23] 和 HallusionBench [17],观察到 LLaVA-o1 的两个主要优势:
-
通过结构化推理使模型能够独立完成推理任务,在需要系统化分析的复杂推理任务中显著优于传统的 CoT 提示。
-
我们的阶段级束搜索方法具有可扩展性,能够提高性能的稳定性和可靠性,使其在复杂任务和场景中更有效地实现准确的结果。
主要贡献
-
我们提出了 LLaVA-o1,一种专为系统化推理设计的视觉语言模型,在需要结构化思考和推理的任务中表现出色。
-
我们展示了 LLaVA-o1 使用阶段级束搜索实现推理阶段扩展的能力,这意味着在增加计算资源的情况下,我们的方法性能可进一步提升,适用于更复杂的任务和场景。
-
通过在多个基准上的广泛实验,我们的方法表现出优于更大规模和闭源模型的性能,突显了 LLaVA-o1 在多模态推理中的有效性。

提出的方法
我们的 LLaVA-o1 模型通过渐进式、逐步推理流程提升视觉语言模型(Vision-Language Models, VLMs)的推理能力,同时支持高效的推理阶段扩展 [47]。通过结构化的思维方式,LLaVA-o1 实现了系统化且高效的推理流程,其推理框架在推理阶段扩展性上优于现有方法。此设计确保了在需要复杂推理的任务中,模型能够兼顾鲁棒性与准确性,从而区别于传统方法。图 1 展示了我们的推理过程框架。
2.1 通过结构化思维增强推理能力
在训练阶段,我们的目标是开发一个能够进行延伸推理链的视觉语言模型,使其能够进行系统化且深入的推理。
2.1.1 推理阶段
我们提出的 LLaVA-o1 模型将答案生成过程分解为四个结构化的推理阶段:
-
摘要阶段(Summary Stage):在初始阶段,LLaVA-o1 提供对问题的高层次总结解释,概述它要解决的问题的主要方面。
-
描述阶段(Caption Stage):如果问题涉及图像,LLaVA-o1 会对与问题相关的视觉元素进行简要描述,以帮助理解多模态输入。
-
推理阶段(Reasoning Stage):基于前述的摘要,LLaVA-o1 进行结构化的逻辑推理以得出初步答案。
-
结论阶段(Conclusion Stage):在最终阶段,LLaVA-o1 基于之前的推理合成答案。
在上述阶段中,结论阶段的输出是直接提供给用户的答案,而前三个阶段是模型内部的“隐藏阶段”,代表其推理过程。根据用户需求,结论阶段的输出可以适配为简洁或详细的答案。
模型在无需外部提示工程的情况下自主激活每个阶段。具体来说,我们为模型提供了四对专用标签:、、 和 。这些标签分别用于标记摘要、描述相关图像内容、进行推理以及生成最终答案。
在训练中,模型自主选择并激活这些标签,基于其自身的判断完成所有阶段。与 OpenAI o1 [63] 类似,所有阶段均在一次推理过程中完成。这种结构化的方法使模型能够独立管理推理过程,从而在复杂推理任务中表现出更强的适应性和性能。
2.1.2 数据准备与模型训练
由于现有的视觉问答(VQA)数据集缺乏训练 LLaVA-o1 所需的详细推理过程,我们整合了多个常用的 VQA 数据集,编制了一个包含 99k 图像问答对的新数据集(每对可能包括一个或多个轮次的问题)。如图 3 所示,由于目前没有能够直接生成系统化、结构化推理的多模态模型,我们使用 GPT-4o [3] 生成详细的推理过程,包括摘要、描述、推理和结论,并将这些数据整合到 LLaVA-o1-100k 数据集中(计划公开发布)。
我们整合了以下两类数据来源:
-
通用 VQA 数据集:包括 ShareGPT4V [8](多轮问答数据)、ChartQA [38](图表和图形解释)、A-OKVQA [45](超越可见内容的外部知识)、DocVQA [39](基于文档的问题)、PISC [28](社会关系理解)以及 CLEVR [22](物体属性、空间关系和计数任务)。
-
科学领域 VQA 数据集:包括 GeoQA+ [7](几何推理)、AI2D [23] 和 ScienceQA [34](科学问题),以及专注于视觉上下文算术分析的 CLEVR-Math [13]。
模型训练:我们使用 LLaVA-o1-100k 数据集对现有模型进行监督微调(SFT),以增强推理能力。本研究选用 Llama-3.2-11B-Vision-Instruct [40] 作为基础模型,在单节点 8 张 H100 GPU 上进行全参数微调。
2.2 使用阶段级束搜索实现高效推理扩展
在推理阶段,我们旨在进一步提升模型的推理能力。具体来说,我们利用 LLaVA-o1 的阶段输出特性,为推理阶段扩展提供理想的粒度。方法如下:
-
为第一阶段生成 N 个响应样本。
-
随机选择两个响应样本,并让模型判断哪一个更优,保留更优响应。
-
重复 N−1 次,保留最优响应。
-
对下一阶段生成 N 个响应,并重复步骤 2-4,直至完成所有阶段。
LLaVA-o1 的结构化输出设计使该方法成为可能,支持每个阶段的高效验证,从而验证结构化输出在改进推理阶段扩展中的有效性。如图 4 所示,展示了三种扩展方法的对比。
示例分析:在图 5 的示例中,当未应用推理阶段扩展时,尽管模型生成了正确的推理步骤,但未能在推理过程中得出明确答案,导致结论阶段的错误结果。相比之下,使用推理阶段扩展后,模型保留了通向最终答案的正确推理步骤,从而确保了答案的准确性。

与现有最先进视觉语言模型(VLMs)的比较
如表 7 所示,我们在六个需要高级推理能力的基准上,将 LLaVA-o1 与其他最先进的开源和闭源视觉语言模型(VLMs)进行了比较。这些基准包括 MMStar-R、MMBench-R、MMVet-R、MathVista、AI2D 和 HallusionBench。其中,MMStar-R、MMBench-R 和 MMVet-R 是从 MMStar、MMBench V1.1 和 MMVet 定制派生的基准,移除了仅需要粗略感知、细粒度感知和 OCR 的任务。这些过滤后的基准保留了需要复杂推理的任务。而 MathVista、AI2D 和 HallusionBench 本身专注于高级推理任务,因此保留了其中的所有任务。
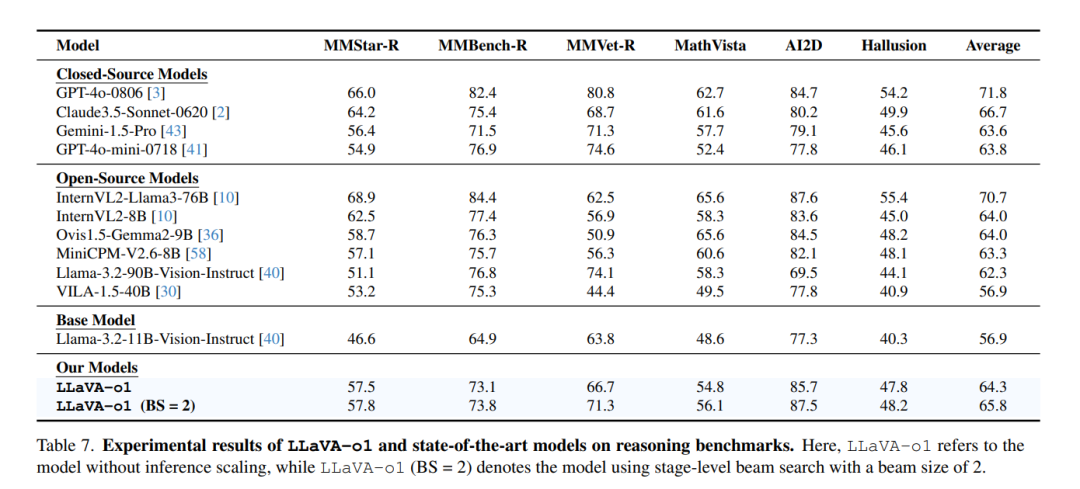
我们的结果显示,LLaVA-o1 在多个基准上持续超越了许多同等规模甚至更大规模的开源模型,例如:
-
InternVL2-8B [10]
-
Ovis1.5-Gemma2-9B [36]
-
MiniCPM-V2.6-8B [58]
-
Llama-3.2-90B-Vision-Instruct [40]
-
VILA-1.5-40B [30]
更值得注意的是,LLaVA-o1 甚至优于某些闭源模型,如 GPT-4o-mini [41] 和 Gemini-1.5-pro [43]。这进一步凸显了我们结构化推理方法的有效性。
这些对比结果验证了我们方法的优势,特别是在高度依赖推理能力的基准中,LLaVA-o1 表现出极具竞争力的能力,成为推理密集型 VLM 任务中的领先模型。
结论
本文提出了一种新型的视觉语言模型 LLaVA-o1,其能够在多个阶段内进行结构化、自主推理。通过引入四个明确的推理阶段(摘要、描述、推理 和 结论),LLaVA-o1 实现了系统化的推理流程。
我们的贡献包括以下两个主要方面:
-
创建了包含详细推理标注的 LLaVA-o1-100k 数据集,为系统化、结构化响应的训练提供支持。
-
提出了阶段级束搜索方法,实现了高效的推理阶段扩展。
总体而言,LLaVA-o1 为多模态推理任务中的 VLMs 树立了新的标准,提供了强大的性能和扩展性,尤其是在推理阶段扩展方面。本研究为未来关于 VLMs 结构化推理的研究铺平了道路,包括潜在的扩展方向,如引入外部验证器和通过强化学习进一步增强复杂的多模态推理能力。
程序员为什么要学大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









