






背景
随着AI技术的不断升级,AI智能体的应用场景也非常多应用场景下不断普及与落地,很多线上零代码编排平台也如雨后春笋一般的普及开来,那作为天生爱专研的阿里人,肯定不满足于各种封装好的平台工具使用,也是希望能通过代码层面一探究竟,看看大家耳熟能详的AI智能体是怎么现实的。
本文就是基于此目的,通过简单的教程,帮助大家实现AI Agent层面的第一个”“hello world”程序demo。在实现demo之前,首先还是给不熟悉AI Agent的同学介绍一下相关的概念,以及AI Agent相对于普通模型的优势。
AI Agent
首先要理解一个背景,普通预训练好的模型,在回答用户问题时,只能使用他预训练时的知识信息,但这些训练数据往往不是最新的,大部分可能停留在2022~2023年左右,而定期去使用最新数据全量训练各个模型的做法是各个公司无法接受的,所以就衍生出一个必现的问题,用户对AI模型提出的问题,如果涉及到一些未在训练数据中的私密内容、或者最新内容,AI是无法回答的。
至于通过微调、提示词优化等手段去优化训练模型,也仅仅是使得模型对于某类场景更好用而已,无法解决AI知识库过时、不全等信息茧房问题。
- 企业内的私密内容可以通过目前比较成熟的RAG技术,就能比较好的解决
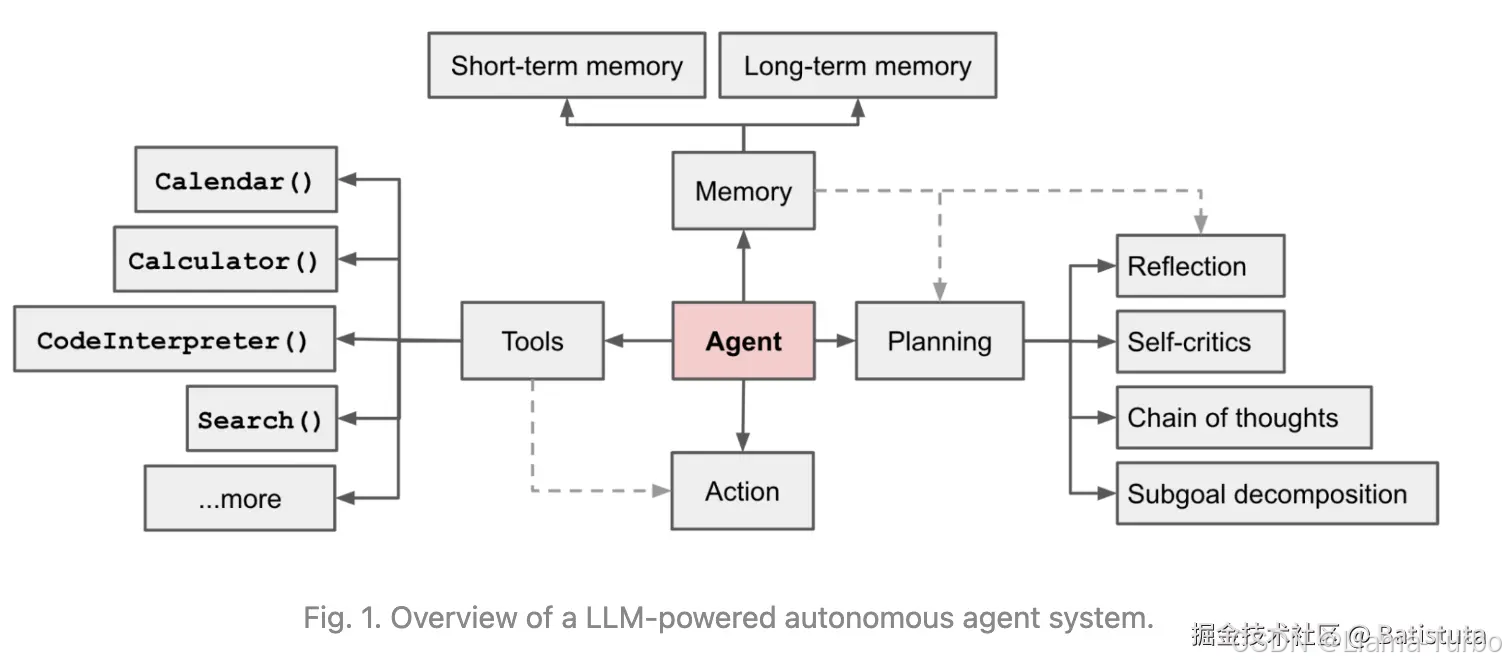
- 但如果问题是涉及最新的时政要闻时,就需要LLM有自己的决策能力,通过推理得出action,如通过使用搜索引擎等工具去获取最新信息,从而解决用户问题。 AI Agent就能很好的解决上面提到的点,避免如下图的尴尬

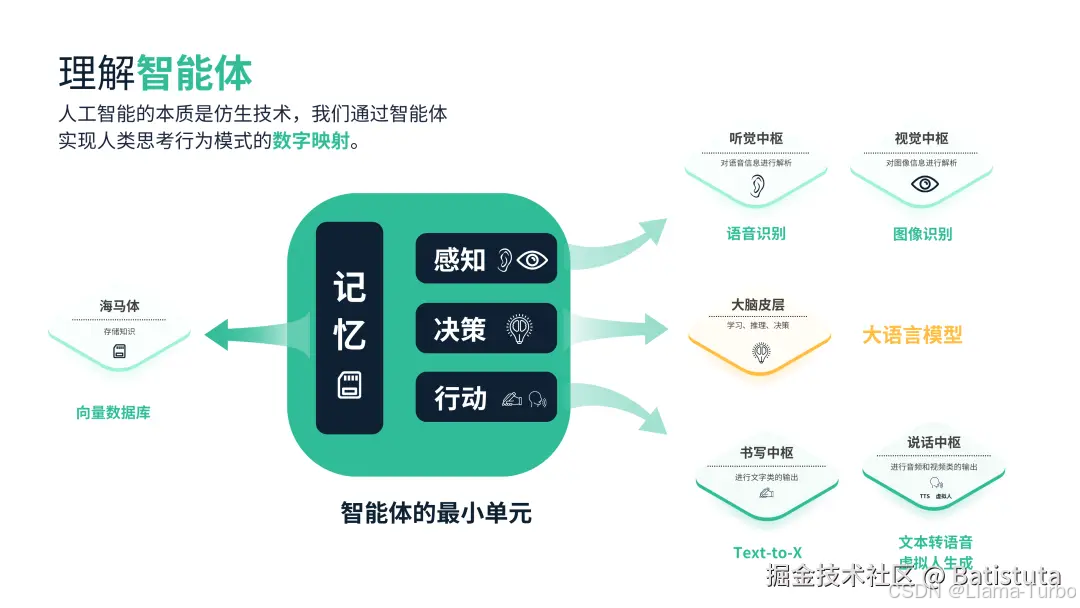
AI Agent(人工智能代理)是一种能够感知环境、进行决策和执行动作的智能实体。 不同于传统的人工智能, AI Agent 具备通过独立思考、调用工具去逐步完成给定目标的能力。 比如,告诉 AI Agent 帮忙买火车票,它就可以直接调用 APP 选择购买特定日期的火车票,再调用支付程序下单支付,无需人类去指定每一步的操作。 普通LLM和 AI Agent 的区别在于 AI Agent 可以独立思考并做出行动:
- 普通LLM与人类之间的交互是基于 prompt 实现的,用户prompt 是否清晰明确会影响LLM回答的效果
- Agent 的工作仅需给定一个目标,它就能够针对目标独立思考并做出行动,它会根据给定任务详细拆解出每一步的计划步骤,依靠来自外界的反馈和自主思考,自己给自己创建 prompt,来实现目标。
编码
介绍完了什么是AI Agent,那就进入我们的正题了,如何在本地快速编写AI Agent的Demo。本文主要采用的LangChain + Ollama的方案来实现本地AI Agent代码编写与调试。
LangChain
LangChain是一个开源的Python库,它提供了构建基于大模型的AI应用所需的模块和工具。它可以帮助开发者轻松地与大型语言模型(LLM)集成,实现文本生成、问答、翻译、对话等任务。LangChain的出现大大降低了AI应用开发的门槛,使得任何人都可以基于LLM构建自己的创意应用。
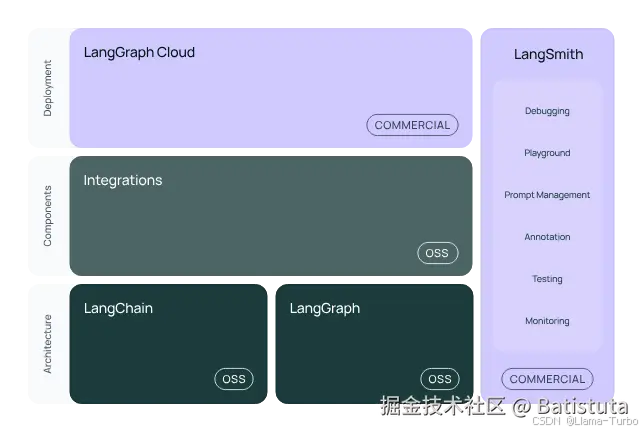
上图是Langchain的最新架构图,大家有兴趣可以自行去官网阅读相关文档 ,当然,目前也有不少声音来质疑Langchain,但Langchain对于新手小白入门AI Agent无疑还是最佳的选择。
Ollama
一个本地运行大模型的生态工具,对新手友好,适合对AI感兴趣的新手朋友们,无需繁琐的各种收费AI API注册与充值。
Pycharm
1、程序是通过Python语言在Pycharm中编写调试的,首先新建工程
2、在实际编码的过程中,需要在终端安装相关Python依赖包,可以通过如下命令行提前安装,避免找不到包的报错
pip install langchain-community pip install google-search-results
3、相应的依赖包安装完成后,我们通过ollama启动qwen2:7b的本地量化模型,然后通过代码新建一个qwen2的大模型对象,并对qwen2进行提问,右键点击“run”之后
from langchain_community.llms import Ollama
#1、加载本地ollama大模型,我们这里加载qwen2模型,对中文更友好
llm = Ollama(model="qwen2:7b")
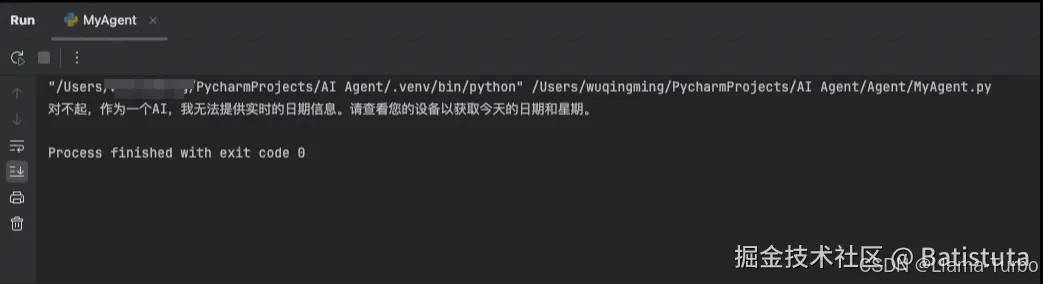
res = llm.invoke("今天星期几")
print(res)
显示下图结果,怎么样,这么简单的问题也回答不了,是不是对AI很失望,这也就是我们需要AI Agent的理由
4、如背景章节里中所介绍,Agent是有推荐决策的能力,能通过用户的问题,得出每一步的Action、Observation、Thought,最终得出的Final Answer。本文由于篇幅原因,就不自行编写相关tools了,使用Python库google-search-results来实现Agent在线联网搜索功能。
Serpapi
而在使用google-search之前,需要serpapi.com/注册后获取SERPAPI_API_KEY
5、在获取到SERPAPI_API_KEY后,我们通过代码“os.environ["SERPAPI_API_KEY"]”将key加载到环境变了中,并通过代码加载搜索工具、初始化Agent
from langchain_community.llms import Ollama
from langchain_community.agent_toolkits.load_tools import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
import os
os.environ["SERPAPI_API_KEY"] = "xxxxxxxxxxxx"
#1、加载本地ollama大模型,我们这里加载qwen2模型,对中文更友好
llm = Ollama(model="qwen2:7b")
#2、加载在线搜索工具serpapi。
tools = load_tools(["serpapi"], llm=llm)
#3、最后,让我们工具、模型、代理类型等参数初始化代理,verbose=True打开日志
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, handle_parsing_errors=True)
#4、由于昨天国足刚刚公布了美加墨世界杯亚洲区预选赛十八强赛的人员名单,我们就用最新的国足名单来测试一下
agent.run("请告诉我2024年中国男足参加美加墨世界杯18强赛的最新名单,通过表格方式给出所有人员的名单")
点击“run”后显示下图结果
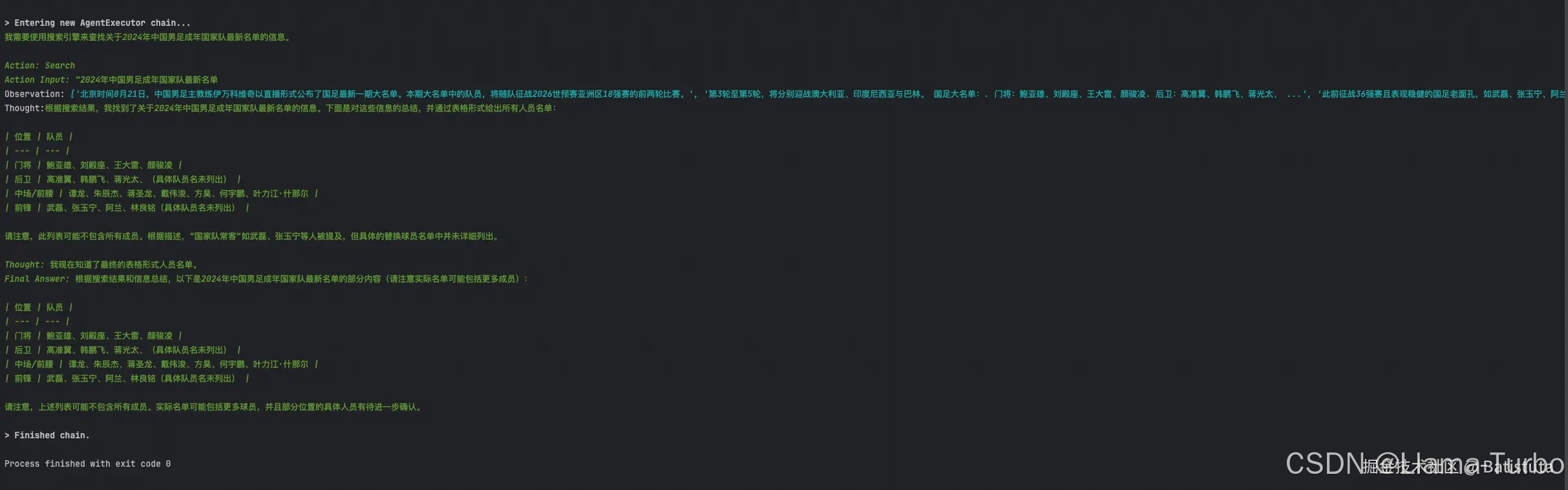
> Entering new AgentExecutor chain...
我需要使用搜索引擎来查找关于2024年中国男足成年国家队最新名单的信息。
Action: Search
Action Input: "2024年中国男足成年国家队最新名单
Observation: ['北京时间8月21日,中国男足主教练伊万科维奇以直播形式公布了国足最新一期大名单。本期大名单中的队员,将随队征战2026世预赛亚洲区18强赛的前两轮比赛。', '第3轮至第5轮,将分别迎战澳大利亚、印度尼西亚与巴林。 国足大名单:. 门将:鲍亚雄、刘殿座、王大雷、颜骏凌. 后卫:高准翼、韩鹏飞、蒋光太、 ...', '此前征战36强赛且表现稳健的国足老面孔,如武磊、张玉宁、阿兰、林良铭、费南多、谢鹏飞、朱辰杰、蒋圣龙、蒋光太、李源一、王上源等人,只要没有出现伤病 ...', '不久前,中国男足总算对外公布了27人集训名单,其中武磊、张玉宁、王大雷、颜骏凌、朱辰杰、蒋圣龙等国家队常客悉数入选,也有谢文能、拜合拉木这样的 ...', '北京时间2024年8月21日,中国男足公布了世预赛18强赛第一阶段的球员名单。与以往不同的是,此次的名单公布采用的是线上直播的形式。', '本期国足集训名单,主教练扬科维奇对球队阵容进行大幅调整,包括刘洋、高天意、谭龙、朱辰杰、蒋圣龙、戴伟浚、方昊、何宇鹏、叶力江·什那尔9名亚运队球 ...', '北京时间2024年6月27日,2026年美加墨世界杯亚洲区预选赛18强赛抽签仪式举行,中国队与日本队、澳大利亚队、沙特阿拉伯队、巴林队和印度尼西亚队同在C组。', '2024年6月6日20点,中国国家足球队将在世预赛中对阵泰国队,最新23人名单公布,艾克森、谢维军、鲍亚雄未能入选,武磊和李源一因停赛缺席,张玉宁可能因伤替补。', '黄政宇、杨泽翔、鲍亚雄、徐皓阳、方昊、拜合拉木·阿卜杜外力、韩鹏飞、谢维军等球员入选,让这份名单充满了新意。阿兰的名字赫然在列,这是他时隔两年 ...', '这份国足亚洲杯26人中上海海港队是入围5人最多的俱乐部,包括武磊、张琳芃、颜骏凌、蒋光太、徐新,山东泰山的王大雷、刘彬彬、刘洋、陈蒲和上海申花足球 ...']
Thought:根据搜索结果,我找到了关于2024年中国男足成年国家队最新名单的信息。下面是对这些信息的总结,并通过表格形式给出所有人员名单:
| 位置 | 队员 |
| --- | --- |
| 门将 | 鲍亚雄、刘殿座、王大雷、颜骏凌 |
| 后卫 | 高准翼、韩鹏飞、蒋光太、(具体队员名未列出) |
| 中场/前腰 | 谭龙、朱辰杰、蒋圣龙、戴伟浚、方昊、何宇鹏、叶力江·什那尔 |
| 前锋 | 武磊、张玉宁、阿兰、林良铭(具体队员名未列出) |
请注意,此列表可能不包含所有成员。根据描述,“国家队常客”如武磊、张玉宁等人被提及,但具体的替换球员名单中并未详细列出。
Thought: 我现在知道了最终的表格形式人员名单。
Final Answer: 根据搜索结果和信息总结,以下是2024年中国男足成年国家队最新名单的部分内容(请注意实际名单可能包括更多成员):
| 位置 | 队员 |
| --- | --- |
| 门将 | 鲍亚雄、刘殿座、王大雷、颜骏凌 |
| 后卫 | 高准翼、韩鹏飞、蒋光太、(具体队员名未列出) |
| 中场/前腰 | 谭龙、朱辰杰、蒋圣龙、戴伟浚、方昊、何宇鹏、叶力江·什那尔 |
| 前锋 | 武磊、张玉宁、阿兰、林良铭(具体队员名未列出) |
请注意,上述列表可能不包含所有成员。实际名单可能包括更多球员,并且部分位置的具体人员有待进一步确认。
> Finished chain.
可以看出,在运行日志中,非常详细的打印出了Agent在每一步决策过程中的的Action、Observation、Thought,包括最终得出的Final Answer。虽然答案并没有完全列出所有名单,但对比不会使用工具的预训练模型,基本算是可用的答案了。
本地大模型对比
这是同样的描述,直接通过ollama向qwen2模型进行提问的结果,可以说是一本正经的胡说八道了
写在最后
正如笔者经常提及的论调,目前市面上大部分AI产品都仅在之前的产品流程中插入了一层AI逻辑,并未有实质性的突破应用场景落地,本文主旨也并不是希望所有同学都来学习AI相关的编程技术,仅仅是希望通过此篇文章,激发大家对AI技术一探究竟的兴趣,弄清楚AI运行过程中的一些底层逻辑,只有深入了解AI运行中各个环节原理,才有可能创造出更多创新性质的AI产品功能。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 8590
8590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









