







博主前期有写过协同过滤协同过滤itembase增量计算Spark实现(一),其中已经较为基础的演示了基于欧拉距离求解相似度的过程,由于都是在一个JOB里,随着数据量的增长会出现计算耗时过长、OOM等现象,后期博主在推荐系统架构优化方面发现上述五个步骤在诸如看了还看,买了还买,相关搜索词,搜索最终购买等推荐模块存在着大量的相似,这些步骤的复用性太强,所以就开始考虑对算法模块按其计算步骤进行拆分,拆分之后的代码结构如下图:
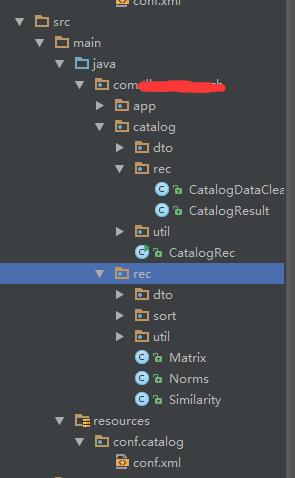
其中rec文件夹下为公用算法模块,主要包括norms,mastrix,similarity。后续求相似度得分的各种算法实现都可以在此模块下添加。
catalog文件夹为类目推荐模块,只里面只需要将原始数据dataclean成算法所需输入及算法结构组装成所需输出格式即可。
itembase协同过滤算法主要可以拆分成如下几个步骤:
1.数据清洗 dataclean
2.计算模 norms
3.生成共生矩阵 matrix
4.计算相似度 similarity
5.转化输出 output
下面演示架构调整之后itembase的计算过程:
数据清洗
如果可以从日志采集系统或者系统日志中得到如下基础数据,那恭喜已经迈出了成功的一大步,因为已经拥有了生产资料。
USERIF SKU REF
1000000148,374753033,2
1000000444,213854638,2
1000000444,250439018,2
1000000444,255468579,1
1000000518,160079966,2
1000000518,231416046,2
1000000518,236056060,2
1000000518,241393352,1
1000000518,242298041,1
1000000518,248723096,1
1000000533,216326552,2
1000000611,265955264,2
1000000665,212797458,2
1000000826,240917738,2
1000001161,229249059,2
......catalogDataClean
aggregateByKey(new ArrayList<Tuple2<Long, Float>>(), new
Function2<List<Tuple2<Long, Float>>, Tuple2<Long, Float>,
List<Tuple2<Long, Float>>>() {
@Override
public List<Tuple2<Long, Float>> call(List<Tuple2<Long, Float>> v1, Tuple2<Long, Float> v2) throws Exception {
if (0 != v2._1() && 0 != v2._2()) {
v1.add(v2);
}
return v1;
}
}, new Function2<List<Tuple2<Long, Float>>, List<Tuple2<Long, Float>>, List<Tuple2<Long, Float>>>() {
@Override
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









