






 加州大学圣地亚哥分校的研究团队开发了SnapATAC2,一款基于Rust和Python的高效数据分析工具,采用无矩阵拉普拉斯映射算法处理大规模单细胞数据,显著提升计算效率。SnapATAC2在多组学数据分析中表现出色,推动基因调控机制研究和新发现的发展。
加州大学圣地亚哥分校的研究团队开发了SnapATAC2,一款基于Rust和Python的高效数据分析工具,采用无矩阵拉普拉斯映射算法处理大规模单细胞数据,显著提升计算效率。SnapATAC2在多组学数据分析中表现出色,推动基因调控机制研究和新发现的发展。
在当今的生物医学研究中,单细胞组学特别是单细胞表观遗传学技术的迅速发展,正逐步重塑我们对于生物体内复杂的基因调控机制的理解。这些技术的进步,为研究者提供了洞察细胞层面上基因表达和调控的新视角,揭示了细胞间的细微差异和复杂交互。但是,单细胞测序数据的海量增长给研究者带来了挑战,即如何有效处理和分析这些庞大、高维的数据集以提炼出有价值的生物学信息。
传统数据分析方法在计算效率和捕获细胞多样性方面存在局限,难以满足当前研究的需求。比如,PCA虽高效,但只能捕捉线性关系,不足以全面反映细胞多样性。而基于深度学习的降维方法虽然在捕捉细胞多样性方面更为精确,但计算量巨大,不易应用于大规模数据集。
针对这一问题,2024年1月8日,加州大学圣地亚哥分校的任兵教授团队在Nature Methods杂志发表了题为A fast, scalable and versatile tool for analysis of single-cell omics data的研究论文,开发了一款名为SnapATAC2的创新软件工具。
SnapATAC2是一个基于Rust和Python的高效数据分析包,采用先进的非线性降维算法,专为单细胞表观遗传学和多组学数据优化。该工具的核心创新在于采用的无矩阵拉普拉斯映射算法,能高效将庞大的单细胞组学数据集转化为易于管理和解析的低维形式,同时保留关键的细胞间关系和生物学特性。

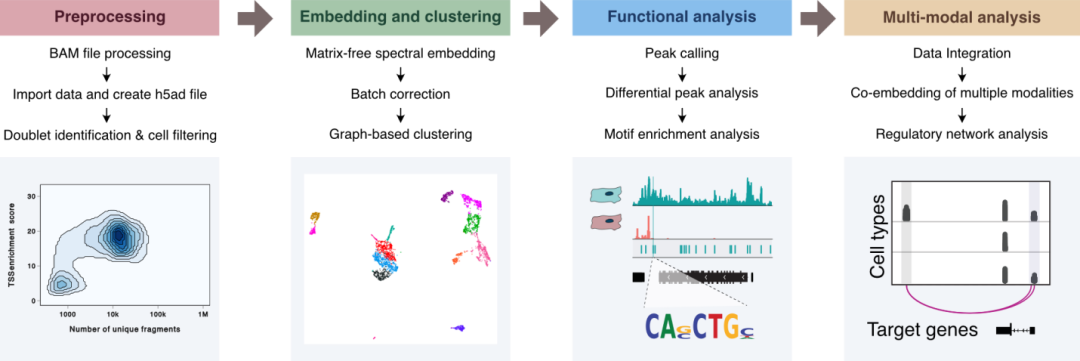 SnapATAC2通过解决传统拉普拉斯映射算法在处理大规模单细胞数据时的内存和运算时间问题,显著提高了计算效率和内存管理能力。这一特点使得研究者能在保证数据质量和精确度的前提下,处理百万级甚至更多细胞的数据。在当前单细胞研究领域快速发展的背景下,这一能力显得尤为重要。
SnapATAC2通过解决传统拉普拉斯映射算法在处理大规模单细胞数据时的内存和运算时间问题,显著提高了计算效率和内存管理能力。这一特点使得研究者能在保证数据质量和精确度的前提下,处理百万级甚至更多细胞的数据。在当前单细胞研究领域快速发展的背景下,这一能力显得尤为重要。
SnapATAC2在速度、可扩展性和精确度方面超越现有方法,在包括ATAC-seq、RNA-seq、单细胞Hi-C和单细胞多组学数据集在内的多种单细胞组学数据集上表现出色。
此外,它提供了一个全面的分析框架,涵盖从原始数据处理到高级分析的各个阶段,包括预处理、降维/聚类、功能富集分析和多模态组学分析。
其用户友好的设计和与单细胞分析生态系统中其他软件工具的良好兼容性,使其成为一个极具价值的工具,适用于广泛的生物学研究和临床应用。
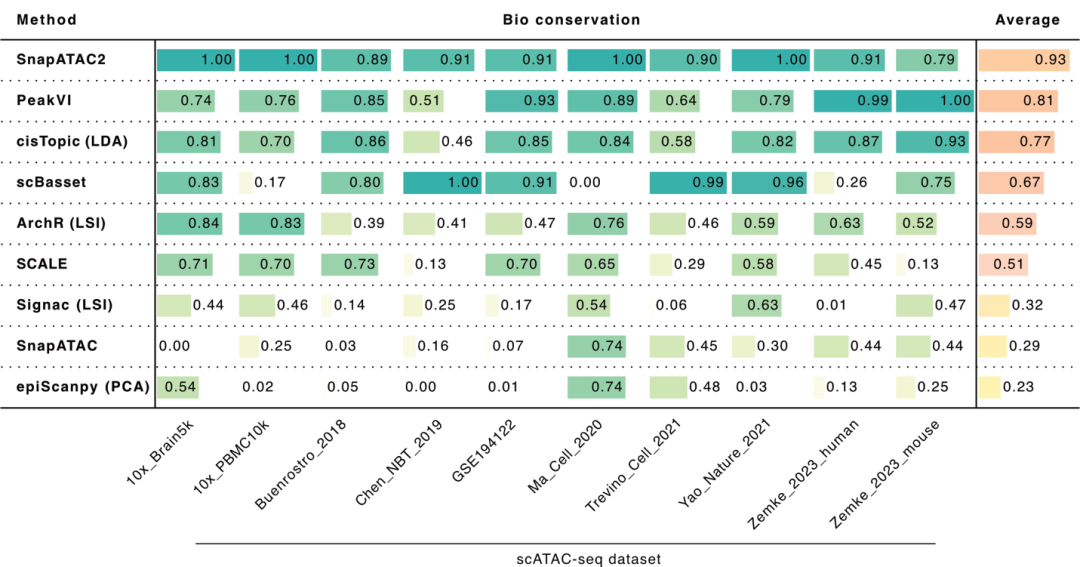 SnapATAC2将大规模、高维的单细胞组学数据有效转化为更易管理的低维表示,极大地推动了细胞层面上基因调控机制的研究,有助于开启新的生物学发现,并为未来单细胞多组学数据分析提供重要的技术支持,为生物医学研究开辟更广阔的可能性。
SnapATAC2将大规模、高维的单细胞组学数据有效转化为更易管理的低维表示,极大地推动了细胞层面上基因调控机制的研究,有助于开启新的生物学发现,并为未来单细胞多组学数据分析提供重要的技术支持,为生物医学研究开辟更广阔的可能性。
随着SnapATAC2的不断发展和优化,它预期将成为该领域的一款通用工具,为解决复杂生物学问题提供强有力的支持。
本研究的第一作者是加州大学圣地亚哥分校的博士后张垲,现任西湖大学特聘研究员。作为通讯作者的任兵教授也来自加州大学圣地亚哥分校。
张垲博士于2023年底加盟西湖大学。他长期致力于研究基因转录调控网络,并在Cell、Nature Methods、Nature Immunology、Nature Communications、Science Advances等知名学术期刊上以第一作者身份发表了多篇原创性研究论文。张垲的实验室专注于基因转录调控研究,运用计算生物学和机器学习等跨学科手段探索细胞分化、衰老及疾病的表观遗传学机制。实验室致力于开发创新的生物信息学和机器学习方法,系统构建转录调控的计算模型,并从基因调控角度解释非编码基因变异与疾病的关联。
张垲课题组积极招募表观遗传学、基因组学、生物信息学等方向的博士后,欢迎有志之士加入,共同探索生物学的深层次奥秘。
原文链接:https://www.nature.com/articles/s41592-023-02139-9
高颜值免费 SCI 在线绘图(点击图片直达)
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|















































 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









