






本系列为MIT Gilbert Strang教授的"数据分析、信号处理和机器学习中的矩阵方法"的学习笔记。
- Gilbert Strang & Sarah Hansen | Sprint 2018
- 18.065: Matrix Methods in Data Analysis, Signal Processing, and Machine Learning
- 视频网址: https://ocw.mit.edu/courses/18-065-matrix-methods-in-data-analysis-signal-processing-and-machine-learning-spring-2018/
- 关注 下面的公众号,回复“ 矩阵方法 ”,即可获取 本系列完整的pdf笔记文件~
内容在CSDN、知乎和微信公众号同步更新

- Markdown源文件暂未开源,如有需要可联系邮箱
- 笔记难免存在问题,欢迎联系邮箱指正
Lecture 0: Course Introduction
Lecture 1 The Column Space of A A A Contains All Vectors A x Ax Ax
Lecture 2 Multiplying and Factoring Matrices
Lecture 3 Orthonormal Columns in Q Q Q Give Q ′ Q = I Q'Q=I Q′Q=I
Lecture 4 Eigenvalues and Eigenvectors
Lecture 5 Positive Definite and Semidefinite Matrices
Lecture 6 Singular Value Decomposition (SVD)
Lecture 7 Eckart-Young: The Closest Rank k k k Matrix to A A A
Lecture 8 Norms of Vectors and Matrices
Lecture 9 Four Ways to Solve Least Squares Problems
Lecture 10 Survey of Difficulties with A x = b Ax=b Ax=b
Lecture 11 Minimizing ||x|| Subject to A x = b Ax=b Ax=b
Lecture 12 Computing Eigenvalues and Singular Values
Lecture 13 Randomized Matrix Multiplication
Lecture 14 Low Rank Changes in A A A and Its Inverse
Lecture 15 Matrices A ( t ) A(t) A(t) Depending on t t t, Derivative = d A / d t dA/dt dA/dt
Lecture 16 Derivatives of Inverse and Singular Values
Lecture 17 Rapidly Decreasing Singular Values
Lecture 18 Counting Parameters in SVD, LU, QR, Saddle Points
Lecture 19 Saddle Points Continued, Maxmin Principle
Lecture 20 Definitions and Inequalities
Lecture 21 Minimizing a Function Step by Step
Lecture 22 Gradient Descent: Downhill to a Minimum
Lecture 23 Accelerating Gradient Descent (Use Momentum)
Lecture 24 Linear Programming and Two-Person Games
Lecture 25 Stochastic Gradient Descent
Lecture 26 Structure of Neural Nets for Deep Learning
Lecture 27 Backpropagation: Find Partial Derivatives
Lecture 28 Computing in Class [No video available]
Lecture 29 Computing in Class (cont.) [No video available]
Lecture 30 Completing a Rank-One Matrix, Circulants!
Lecture 31 Eigenvectors of Circulant Matrices: Fourier Matrix
Lecture 32 ImageNet is a Convolutional Neural Network (CNN), The Convolution Rule
Lecture 33 Neural Nets and the Learning Function
Lecture 34 Distance Matrices, Procrustes Problem
Lecture 35 Finding Clusters in Graphs
Lecture 36 Alan Edelman and Julia Language
文章目录
Lecture 6 Singular Value Decomposition (SVD)
6.1 SVD的概念
-
奇异值 (Singular Values) VS 特征值 (Eigenvalues)
-
Singular Values 与 Eigenvalues 非常相似
-
但 A 的 Singular Values 适用于rectangular matrices! 且有两个 singular vectors
-
特征值、特征向量概念的局限:
❌ 仅适用于方阵:If A is Ax rectangular ⇒ \Rightarrow ⇒ ≠ λ x \not ={\lambda x} =λx ( m × n × n × 1 ) = ( m × 1 ) (m \times n \times n \times 1) = (m \times 1) (m×n×n×1)=(m×1)
❌ 即便A is square, 若A只是一个general而不是symmetric matrix ⇒ \Rightarrow ⇒ A可能会有complex eigenvalues, not orthogonal eigenvectors, etc.
🚩 ⇒ \Rightarrow ⇒ 特征值、特征向量存在局限,需要新的概念 ⇒ \Rightarrow ⇒ Singular Values
-
-
奇异值分解的概念
-
Compare with S = Q Λ Q T S = Q\Lambda Q^T S=QΛQT
▪ Q Q Q: Eigenvectors (仅一个)
▪ Λ \Lambda Λ: Eigenvalues
-
now A = U Σ V T A = U\Sigma V^T A=UΣVT
▪ U U U: Left Singular vectors in m dimensions
▪ V T V^T VT: Right Singular vectors in n dimensions
▪ Σ \Sigma Σ: Singular values
✅ S = [ σ 1 σ 2 . . . σ r . . . ] ∈ M × N S = \begin{bmatrix} \sigma_1 & & & &\\ & \sigma_2 & & &\\ & & ... & &\\ & & & \sigma_r & ... \end{bmatrix} \in M\times N S=⎣⎢⎢⎡σ1σ2...σr...⎦⎥⎥⎤∈M×N
-
6.2 What are U , V T U, V^T U,VT and Σ \Sigma Σ in A = U Σ V T A = U\Sigma V^T A=UΣVT?
-
The key: A T A A^T A ATA is a great matrix
-
A A A: M × N M\times N M×N
-
A T A^T AT: N × M N\times M N×M
-
A T A A^T A ATA: N × N N \times N N×N
-
and symmetric!!!
-
And: positive definite!
▪ All eigenvalues are > 0
-
-
Therefore, ∃ V \exists V ∃V, s.t.
-
A T A A^T A ATA = V Λ V T V \Lambda V^T VΛVT
▪ V V V: eigenvectors of A T A A^T A ATA ⇒ \Rightarrow ⇒ Orthogonal
▪ Λ \Lambda Λ: the eigenvalues of Λ \Lambda Λ ⇒ \Rightarrow ⇒ ≥ 0 \geq 0 ≥0
-
Note: A A T AA^T AAT is a different guy! ⇒ \Rightarrow ⇒ A A T = U Λ U T AA^T = U \Lambda U^T AAT=UΛUT
-
Looking for: A v 1 = σ 1 u 1 Av_1 = \sigma_1 u_1 Av1=σ1u1 ( A V = U Σ AV=U \Sigma AV=UΣ的第1列 ), A v 2 = σ 2 u 2 Av_2 = \sigma_2 u_2 Av2=σ2u2 ( A V = U Σ AV=U \Sigma AV=UΣ的第2列 ), …, A v r = σ r u r Av_r = \sigma_r u_r Avr=σrur ( A V = U Σ AV=U \Sigma AV=UΣ的第r列 )
🚩 Why stop at r (the rank)? 因为大于r时 σ r = 0 \sigma_r = 0 σr=0
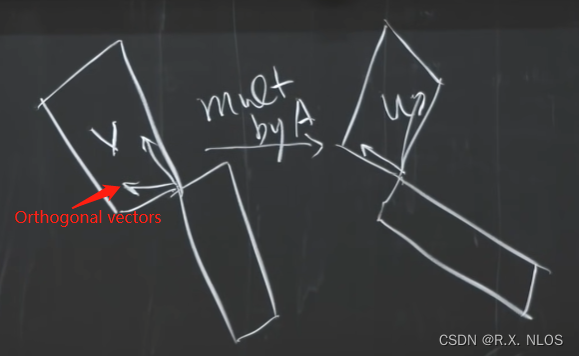
🚩 v i v_i vi: a bunch of orthogonal vectors v;
🚩 u i u_i ui: a bunch of orthogonal vectors u;
🚩 这样,即可 A [ v 1 , v 2 , . . . , v r ] = [ u 1 , u 2 , . . . , u r ] [ σ 1 σ 2 . . . σ r . . . ] A [v_1, v_2, ..., v_r] = [u_1, u_2, ..., u_r] \begin{bmatrix} \sigma_1 & & & &\\ & \sigma_2 & & &\\ & & ... & &\\ & & & \sigma_r & ... \end{bmatrix} A[v1,v2,...,vr]=[u1,u2,...,ur]⎣⎢⎢⎡σ1σ2...σr...⎦⎥⎥⎤ ⇒ \Rightarrow ⇒ A V = U Σ ⇒ A = U Σ V T AV = U \Sigma \Rightarrow A = U \Sigma V^T AV=UΣ⇒A=UΣVT (上述过程从vector-wise form变为了matrix form)
🚩 几何表示如下图
-
-
How to find the V V V, U U U, Σ \Sigma Σ above?
-
若 A = U Σ V T A = U\Sigma V^T A=UΣVT ⇒ \Rightarrow ⇒ A T A = V Σ T U T U Σ V T A^TA = V\Sigma^T U^T U \Sigma V^T ATA=VΣTUTUΣVT = V Σ T Σ V T V\Sigma^T \Sigma V^T VΣTΣVT
-
其中,已知 A T A A^T A ATA 是 positive definite matrix
-
Therefore: 如下取值满足上式
✅ V: the eigenvectors of A T A A^T A ATA
✅ ( Σ T Σ ) (\Sigma^T \Sigma) (ΣTΣ): the eigenvalues of Σ T Σ \Sigma^T \Sigma ΣTΣ ⇒ \Rightarrow ⇒ Σ T Σ \Sigma^T \Sigma ΣTΣ = [ σ 2 \sigma^2 σ2] ⇒ \Rightarrow ⇒ σ 2 \sigma^2 σ2: eigenvalues of A T A A^T A ATA
-
另一方面: A A T A A^T AAT = U Σ V T V Σ T U T U\Sigma V^T V \Sigma^T U^T UΣVTVΣTUT = U ( Σ Σ T ) U T U (\Sigma \Sigma^T) U^T U(ΣΣT)UT ⇒ \Rightarrow ⇒
✅ U: the eigenvectors of A A T A A^T AAT
-
最后一步:Given A A A ⇒ \Rightarrow ⇒ we can get V V V (and v i v_i vi) and σ \sigma σ ⇒ \Rightarrow ⇒ u i u_i ui should be u i = A v i σ r u_i = \frac{Av_i}{\sigma_r} ui=σrAvi
🚩 为什么根据 A A T A A^T AAT得到的 U U U 就是 u i = A v i σ r u_i = \frac{Av_i}{\sigma_r} ui=σrAvi
🚩 即,已知 V V V和 Σ \Sigma Σ满足 A T A = V Σ T Σ V T A^T A = V \Sigma^T \Sigma V^T ATA=VΣTΣVT , 求证 A = U Σ V T A=U\Sigma V^T A=UΣVT, 即 证明 U U U orthogonal , 即 证明 u i T u j = 0 u_i^T u_j = 0 uiTuj=0 ( i ≠ j ) (i \not ={j}) (i=j)
👉 毕竟,若考虑到 A A T A A^T AAT有多重根的情况,特征向量 u i u_i ui可以有无数个
🚩 ( A v i σ i ) T ( A v j σ j ) (\frac{Av_i}{\sigma_i})^T(\frac{Av_j}{\sigma_j}) (σiAvi)T(σjAvj) ⇒ \Rightarrow ⇒ 因为v are orthogonal vectors (eigenvectors of A T A A^T A ATA) ⇒ \Rightarrow ⇒ ( A v i σ i ) T ( A v j σ j ) = v i T A T A v j σ i σ j = v i T σ j 2 v j / ( σ 1 σ 2 ) (\frac{Av_i}{\sigma_i})^T(\frac{Av_j}{\sigma_j}) = \frac{v_i^T A^T A v_j}{\sigma_i\sigma_j} = v_i^T \sigma_j^2 v_j / (\sigma_1 \sigma_2) (σiAvi)T(σjAvj)=σiσjviTATAvj=viTσj2vj/(σ1σ2) = 0.
🚩 因此, A T A = V Σ T Σ V T A^T A = V \Sigma^T \Sigma V^T ATA=VΣTΣVT ⇒ \Rightarrow ⇒ A T A = V Σ T U T U Σ V T A^T A = V \Sigma^T U^T U \Sigma V^T ATA=VΣTUTUΣVT ⇒ \Rightarrow ⇒ A = U Σ V T A=U\Sigma V^T A=UΣVT
-
即, V V V, A V AV AV, U U U, U Σ U\Sigma UΣ 都是orthogonal的
-
-
SVD的计算
-
证明过程中的计算方法: A A A ⇒ \Rightarrow ⇒ A T A A^T A ATA ⇒ \Rightarrow ⇒ V , Σ V,\Sigma V,Σ ⇒ \Rightarrow ⇒ u = A v / σ u = Av/ \sigma u=Av/σ
❌ 缺点: A T A A^T A ATA too large, too expensive ; Its vulnerability to round off errors (condition numver) is squared
-
6.3 Eigenvalues的意义
- SVD的 geometry meaning
-
A = U Σ V A = U \Sigma V A=UΣV
-
U U U and V V V: orthogonal ⇒ \Rightarrow ⇒ rotation (也可能是reflection但not important)
-
Σ \Sigma Σ: diagonal ⇒ \Rightarrow ⇒ stretching
-
For A x = U Σ V T x Ax = U \Sigma V^T x Ax=UΣVTx, geometry meaning 如下图
▪ assume σ 1 ≥ σ 2 ≥ σ 3 ≥ . . . \sigma_1 \geq \sigma_2 \geq \sigma_3 \geq ... σ1≥σ2≥σ3≥...
▪ Every linear transformation can be factored into a rotation + a stretch + a different roration
▪ 什么时候两个rotation相等? A = Q Λ Q T A = Q \Lambda Q^T A=QΛQT 且 Λ > 0 \Lambda > 0 Λ>0 ⇒ \Rightarrow ⇒ A A A本身就是 Positive Definite Symmetric Matrix
-
-
关于不同维数下旋转角的个数问题
▪ For 2 × 2 2\times 2 2×2 Matrix A = [ a b c d ] A = \begin{bmatrix} a & b\\ c & d\\ \end{bmatrix} A=[acbd] ⇒ \Rightarrow ⇒ 受 4个参数控制 (rotation angle A , stretch 2 , and rotation angle 1 )
▪ For 3 × 3 3\times 3 3×3 Matrix A A A: Rotation parametres in 3D: Roll (barrel roll), pitch (up and down), yaw (side-to-side) ⇒ \Rightarrow ⇒ #parameters 3 + 3 + 3 = 9 3 + 3+ 3 = 9 3+3+3=9
▪ For 4 × 4 4\times 4 4×4 Matrix A A A: angles parameters in rotation ( 16 − 4 ) / 2 = 6 (16-4)/2 = 6 (16−4)/2=6
▪ 总参数量始终等于矩阵元素数
-
SVD 数据处理中的应用:
-
The most important pieces of the SVD
- A = ( m × r ) ( r × r ) ( r × n ) = [ u 1 , u 2 , . . . , u r ] [ σ 1 σ 2 . . . σ r ] [ v 1 T v 2 T . . . v r T ] A = (m\times r ) (r\times r )(r\times n) = [u_1, u_2, ..., u_r] \begin{bmatrix} \sigma_1 & & & \\ & \sigma_2 & & \\ & & ... & \\ & & & \sigma_r \end{bmatrix} \begin{bmatrix} v_1^T \\ v_2^T \\ ...\\ v_r^T \end{bmatrix} A=(m×r)(r×r)(r×n)=[u1,u2,...,ur]⎣⎢⎢⎡σ1σ2...σr⎦⎥⎥⎤⎣⎢⎢⎡v1Tv2T...vrT⎦⎥⎥⎤
- all σ i > 0 \sigma_i > 0 σi>0
- A = ( m × m ) ( m × n ) ( n × n ) = [ u 1 , u 2 , . . . , u m ] [ σ 1 0 σ 2 0 . . . 0 σ r 0 0 0 0 0 0 ] [ v 1 T v 2 T . . . v n T ] A = (m\times m ) (m\times n )(n\times n) = [u_1, u_2, ..., u_m] \begin{bmatrix} \sigma_1 & & & & 0\\ & \sigma_2 & & & 0\\ & & ... & & 0\\ & & & \sigma_r & 0 \\ 0 & 0 & 0 & 0 & 0 \end{bmatrix} \begin{bmatrix} v_1^T \\ v_2^T \\ ...\\ v_n^T \end{bmatrix} A=(m×m)(m×n)(n×n)=[u1,u2,...,um]⎣⎢⎢⎢⎢⎡σ10σ20...0σr000000⎦⎥⎥⎥⎥⎤⎣⎢⎢⎡v1Tv2T...vnT⎦⎥⎥⎤
- 上述两者是相等的 because of zero
-
Polar Decomosition of Matrix
- A = U Σ V T A = U\Sigma V^T A=UΣVT ⇒ \Rightarrow ⇒ A = U Σ U T U V T A = U\Sigma U^T U V^T A=UΣUTUVT ⇒ \Rightarrow ⇒ S = ( U Σ U T ) S = (U\Sigma U^T) S=(UΣUT) and Q = U V T Q = UV^T Q=UVT
-
数据处理:For a big matrix A A A with signal and noise
- Looking for the most import part in the matrix
- A = ( m × m ) ( m × n ) ( n × n ) = [ u 1 , u 2 , . . . , u m ] [ σ 1 0 σ 2 0 . . . 0 σ r 0 0 0 0 0 0 ] [ v 1 T v 2 T . . . v n T ] A = (m\times m ) (m\times n )(n\times n) = [u_1, u_2, ..., u_m] \begin{bmatrix} \sigma_1 & & & & 0\\ & \sigma_2 & & & 0\\ & & ... & & 0\\ & & & \sigma_r & 0 \\ 0 & 0 & 0 & 0 & 0 \end{bmatrix} \begin{bmatrix} v_1^T \\ v_2^T \\ ...\\ v_n^T \end{bmatrix} A=(m×m)(m×n)(n×n)=[u1,u2,...,um]⎣⎢⎢⎢⎢⎡σ10σ20...0σr000000⎦⎥⎥⎥⎥⎤⎣⎢⎢⎡v1Tv2T...vnT⎦⎥⎥⎤
- 最大的singular value σ 1 \sigma_1 σ1 对应的piece就是最重要的 ⇒ \Rightarrow ⇒ u 1 σ 1 v 1 T u_1 \sigma_1 v_1^T u1σ1v1T

















 1816
1816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}