







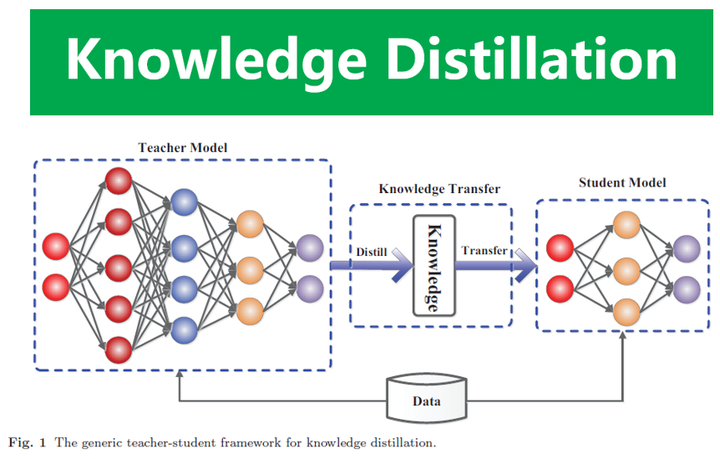
 知识蒸馏技术模仿教学过程,通过教师模型指导学生模型,实现模型压缩与加速。该技术源于2014年,通过使用教师模型的软目标和中间层表示作为训练信号,帮助学生模型在保持高性能的同时减小参数量。目前,研究已扩展到多种任务和信号,并面临匹配、可解释性和资源消耗等挑战。
知识蒸馏技术模仿教学过程,通过教师模型指导学生模型,实现模型压缩与加速。该技术源于2014年,通过使用教师模型的软目标和中间层表示作为训练信号,帮助学生模型在保持高性能的同时减小参数量。目前,研究已扩展到多种任务和信号,并面临匹配、可解释性和资源消耗等挑战。
知识蒸馏技术模仿教学过程,通过教师模型指导学生模型,实现模型压缩与加速。该技术源于2014年,通过使用教师模型的软目标和中间层表示作为训练信号,帮助学生模型在保持高性能的同时减小参数量。目前,研究已扩展到多种任务和信号,并面临匹配、可解释性和资源消耗等挑战。
知识蒸馏技术模仿教学过程,通过教师模型指导学生模型,实现模型压缩与加速。该技术源于2014年,通过使用教师模型的软目标和中间层表示作为训练信号,帮助学生模型在保持高性能的同时减小参数量。目前,研究已扩展到多种任务和信号,并面临匹配、可解释性和资源消耗等挑战。


 订阅专栏 解锁全文
订阅专栏 解锁全文
















06-06
 537
537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}