







实时了解业内动态,论文是最好的桥梁,专栏精选论文重点解读热点论文,围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。当然最重要的是订阅“鲁班模锤”。
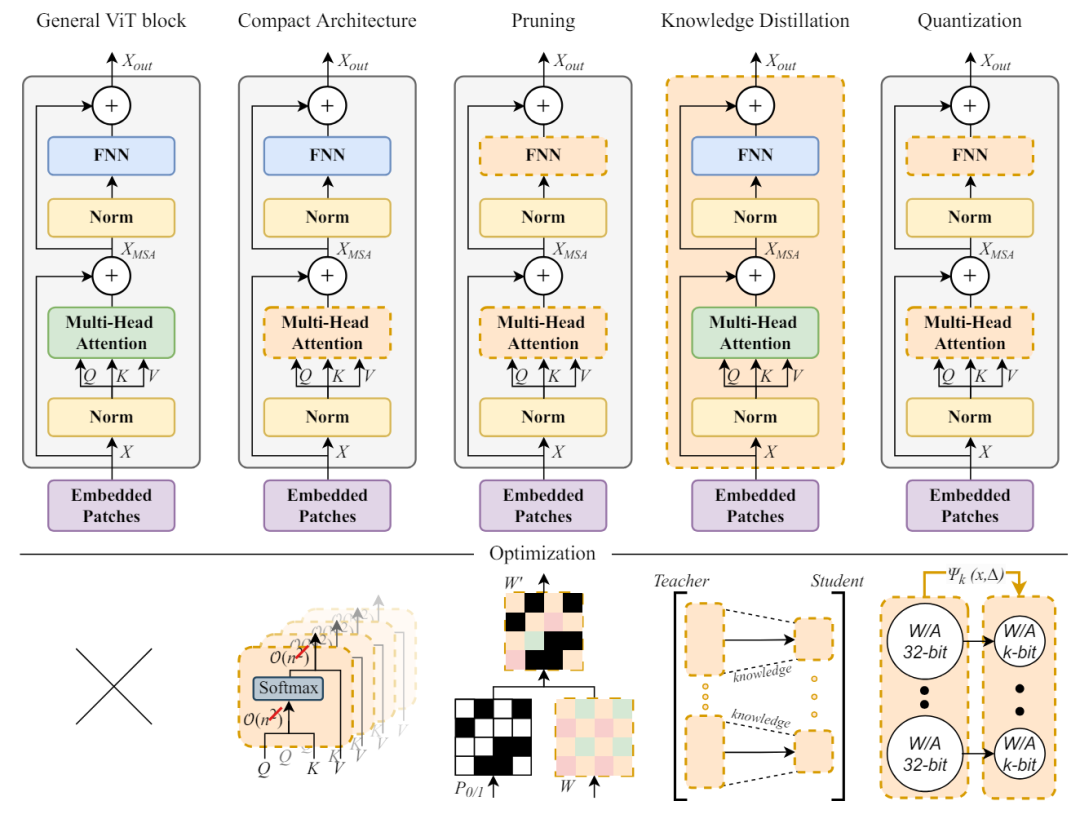
知识蒸馏是一种技术,在这种技术中,较小的模型从更大、更复杂的模型中学习以复制其性能,从而在保持预测准确性的同时实现高效部署。视觉转换器(ViT)的知识蒸馏 (KD)技术可分为两种主要类型:同态KD 和异态KD。

知识蒸馏
知识蒸馏是一种技术,旨在将一个庞大而复杂的模型(教师模型)压缩成一个更小、更简单的模型(学生模型),同时在一定程度上保留教师模型的表现。知识蒸馏并不是一种新方法,它是由Critstian Bucilua等人在 2006年的这篇论文中提出的。
LLM蒸馏将大型生成模型定位为“教师”,将较小的模型定位为“学生”。学生模型可以是简单的模型,如逻辑回归,也可以是基础模型,如BERT。在最基本的蒸馏版本中,数据科学家从未标记的数据开始,并要求LLM对其进行标记。然后,数据科学家使用合成标记的数据来训练“学生”模型,该模型将反映“教师”模型在原始数据集定义的任务中的表现。

logits是模型在应用softmax获得实际概率之前的原始输出。大模型的最终输出是一个向量,里面是所有候选Token的概率,加起来是100%。这个概率是最终的输出(logits)经过softmax归一化得到的。上图是有标签的蒸馏,也有无标签的蒸馏。
在基于反应的知识蒸馏中,教师模型的输出用作学生模型的软标签。学生模型经过训练,可以预测教师迷行的软标签,而不是实际的标签。这样学生就可以从老师的知识中学习,而无需访问老师的参数或架构。使用这种方法,知识蒸馏可以白盒 KD和黑盒 KD。
在黑盒KD中,只有教师模型的提示和响应可用,方法适用于logits无法获取的模型。而在白盒KD中,使用的是教师模型生成的logits,它适用于生成logits的开源模型。
知识蒸馏能够成功的原因在于损失函数。而损失函数包含3个核心组件:教师输出的logits、学生输出的logits和Temperature<在使用大模型的时候,温度代表则发散度和随机度>。
大白话而言:教师模型生成logits,学生模型也生成logits。任何两个类的 logit都无法比较,因此用softmax规范化logit之后,再来对比两个输出的概率分布。目的还是为了减少教师模型和学生模型的概率分布差异,让学生模型的行为更像教师模型。
这里不得不提到Kullback-Leibler散度损失(或 KL 散度损失)是计算任意两个概率分布之间差异的一种方法。以下公式描述了 KD 损失:
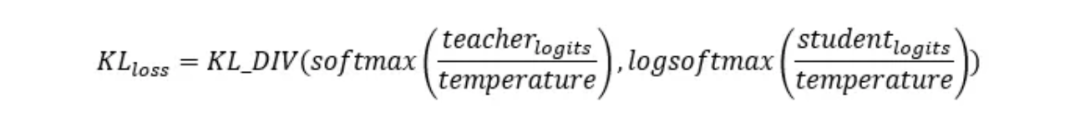

同态KD
Homomorphic KDs
同态KD可进一步分为logit级KD、Patch(小图块)级KD、模块级KD和功能级的KD。
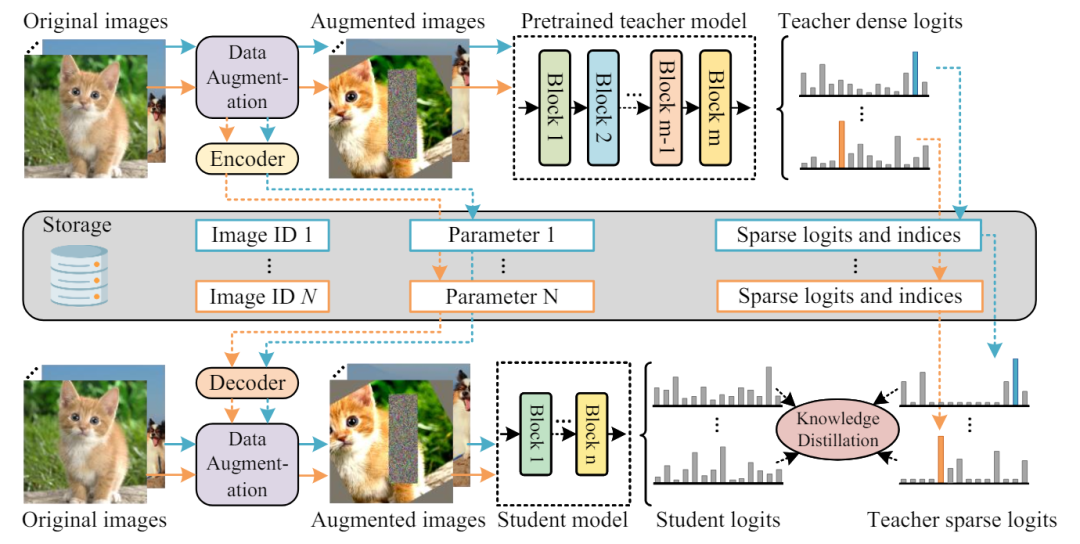
TinyViT基于logit级别,在预训练期间应用蒸馏技术,其中来自大型教师模型的logits预先存储在硬件中,从而在将知识传输到缩小的学生转换器时实现内存和计算效率。
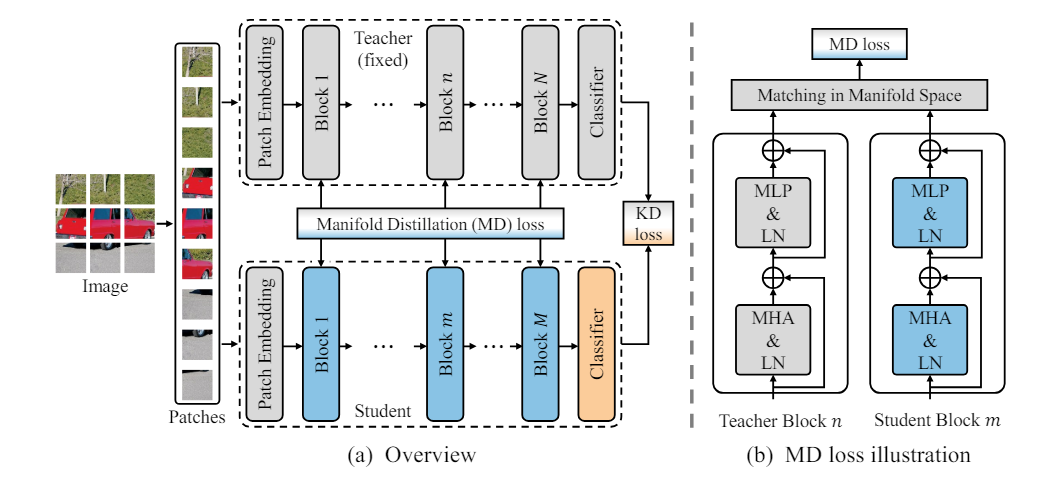
像DeiT-Tiny这样的Patch级技术训练一个小型学生模型,以匹配Patch级结构上的预训练教师模型,然后在计算流形蒸馏损失时,主要是通过比较和匹配选定的教师模型和学生模型层之间的特征关系来实现的。
假设教师模型通过卷积神经网络(CNN)提取了图像的特征,在高维空间中形成了一定的结构。学生模型是基于Transformer的模型,可能无法直接理解卷积提取的特征结构。通过引入流形蒸馏损失,学生模型可以学习如何在其Transformer的特征空间中重现或近似教师模型在卷积层中的特征结构,从而更有效地学习和迁移知识。
m2mKD方法的核心思想是通过元模型M孵化出一系列教师模型,然后通过替换和比较不同层的教师-学生模型对来进行知识蒸馏。这种方法可以帮助学生模型从多个教师模型中学习,进而提升其性能和泛化能力。
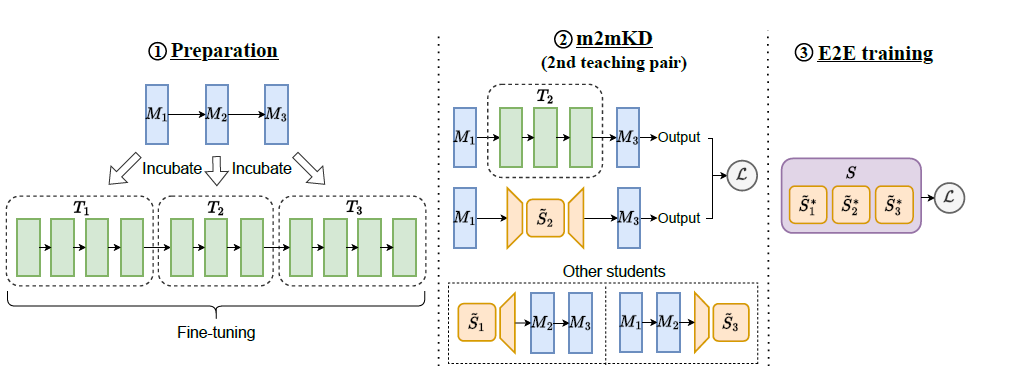
MiniViT演示的特征级KD方法结合了连续变压器模块的权重。
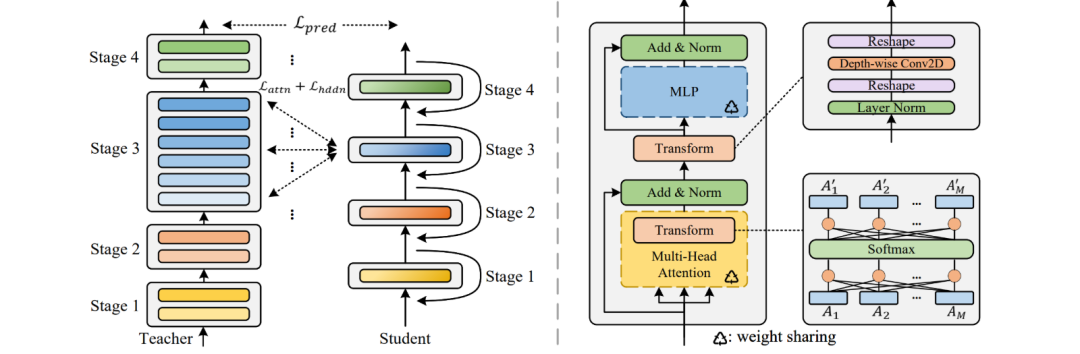
MiniViT的知识蒸馏通过将教师模型(Teacher Model)的知识传递给学生模型(Student Model)来实现模型压缩,从而在保持高性能的同时,降低计算和存储成本。该框架将模型分为多个阶段(Stage 1到Stage 4),每个阶段包含若干个Transformer层。通过设计有效的损失函数(预测损失、注意力损失和隐藏层损失),学生模型能够学习到教师模型的知识。
具体的知识蒸馏过程包括初始化、训练、损失计算、反向传播和迭代步骤。在这个过程中,学生模型逐步调整参数,使其输出接近教师模型。此外,MiniViT的详细Transformer块结构通过多头注意力、多层感知机、添加与归一化层等组件的权重共享和增加参数多样性,进一步优化了模型压缩效果。总之,MiniViT通过配置阶段数量和共享权重,实现了高效的模型压缩,并通过知识蒸馏技术,确保压缩后的模型在性能上接近原始大型模型。

异形KD
Heteromorphic KDs
这种方法主要涉及在具有不同架构的模型之间转移知识。例如,DearKD 提出了一种新颖的两阶段框架,它脱离了传统的ViT架构方法。
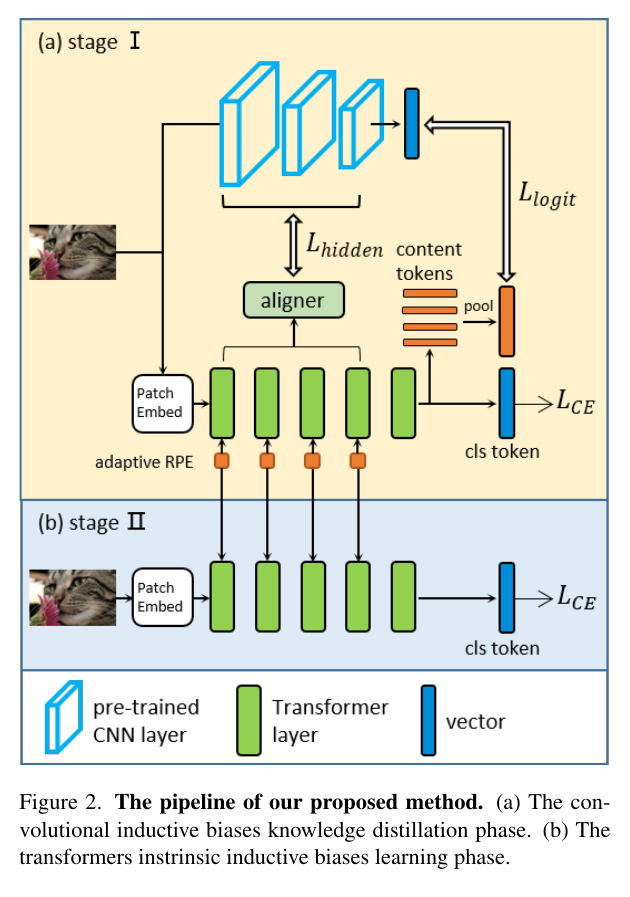
在第一阶段,他们使用普通的KD策略将CNN特征转移到ViT学生模型。在随后的阶段,如果真实样本有限,则它们会引入保持边界的发散内损失以增强该过程。
类似地,CiT 提出了一种异形KD策略,其中知识从多位老师模型转移,从而提高了ViT学生模型的性能。
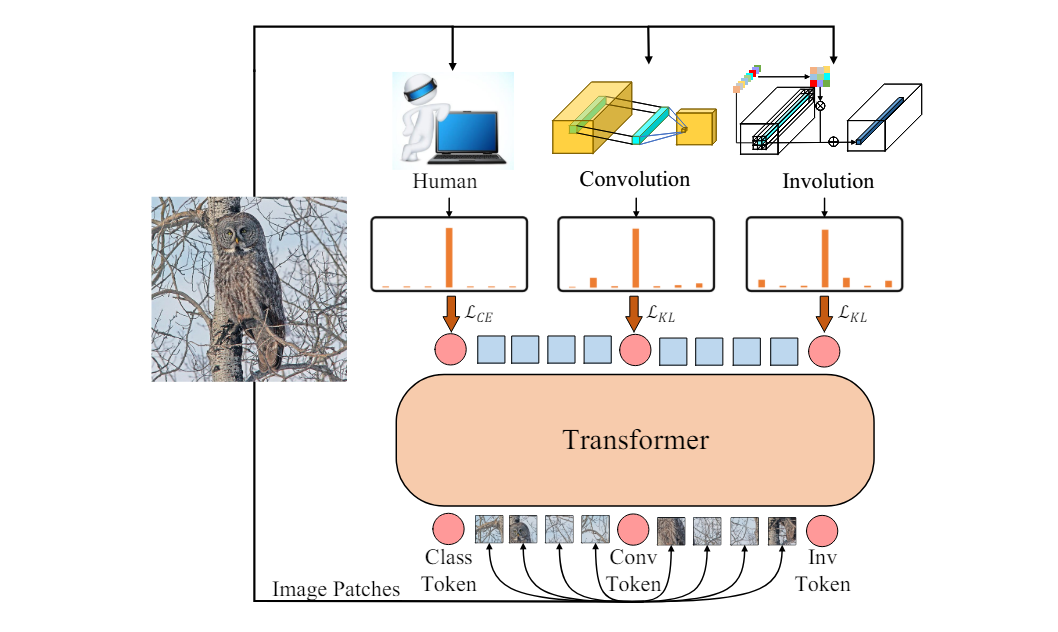
CivT模型不仅继承了ViT的Transformer架构,还通过引入Conv token和Inv token来扩展其能力,使其能够从卷积模型和逆(内)卷积模型中学习特定的图像类别描述信息,从而提升其在图像分类和理解任务中的性能和表现。


















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









