







跑通
代码使用的是 https://github.com/jadore801120/attention-is-all-you-need-pytorch,
commit-id 为: 132907d
各模块粗览
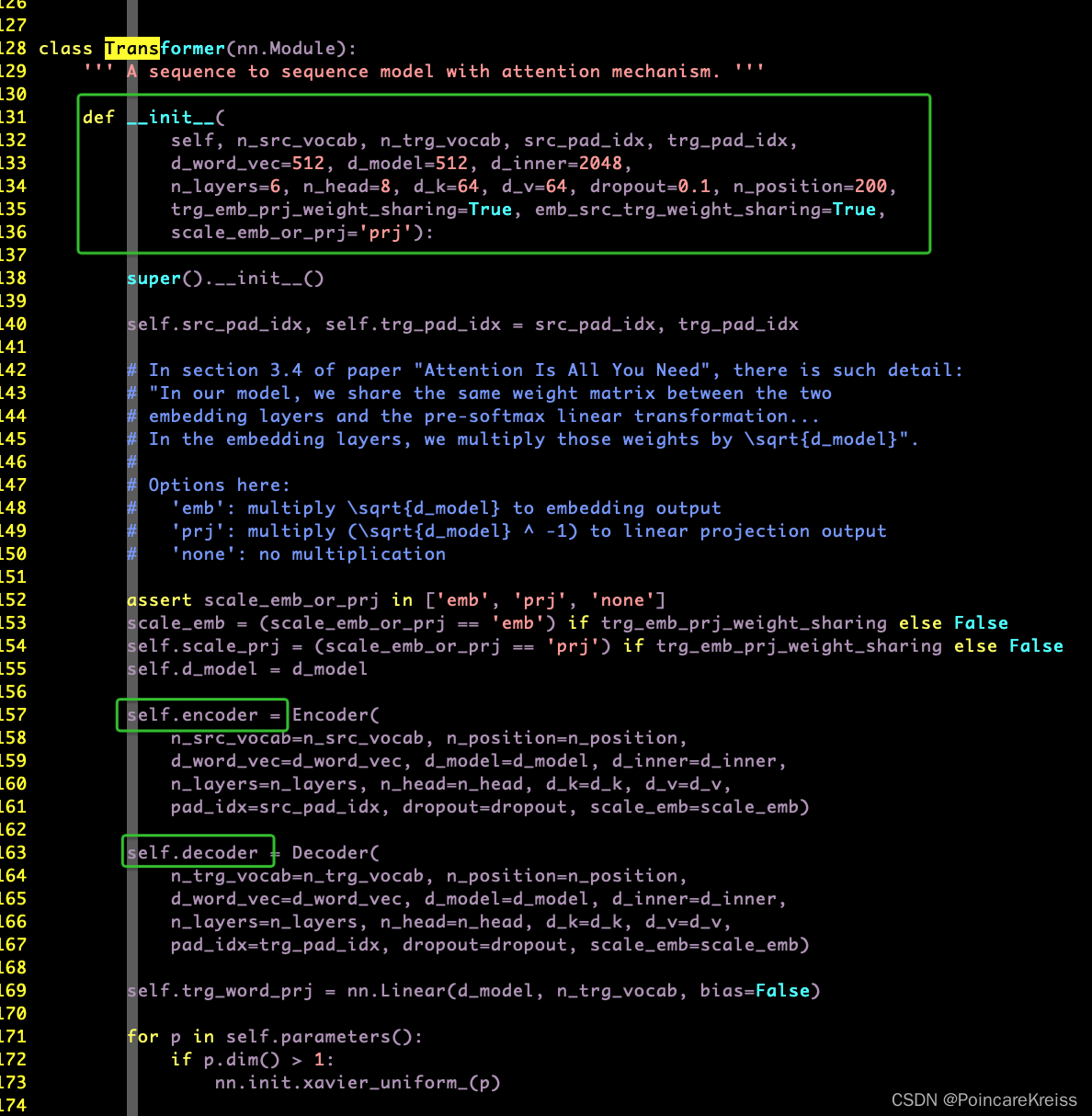
Transformer
主要包括一堆参数,
以及encoder和decoder
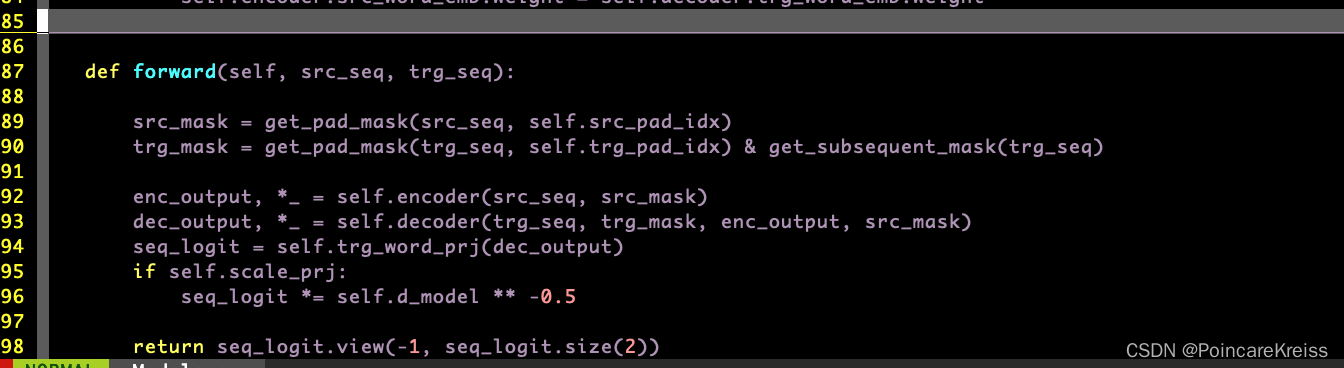
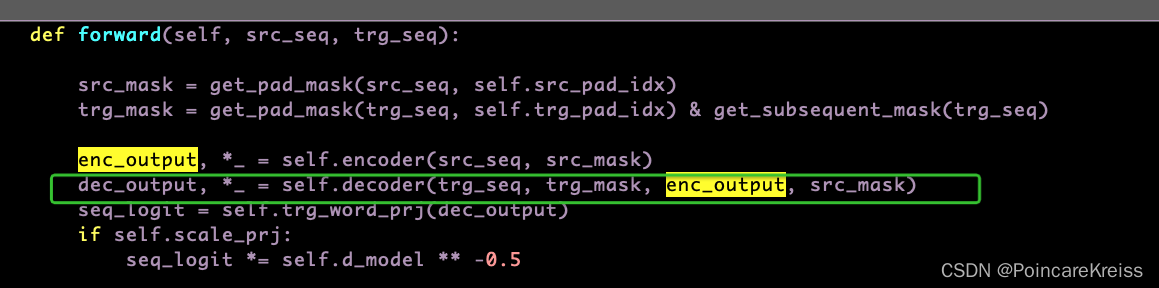
forward的时候主要做了如下操作.
- 先 pad_mask
- 过encoder
- 过decoder
- 输出logit
从train.py 我们可以看出, 模型的输出直接去做了loss
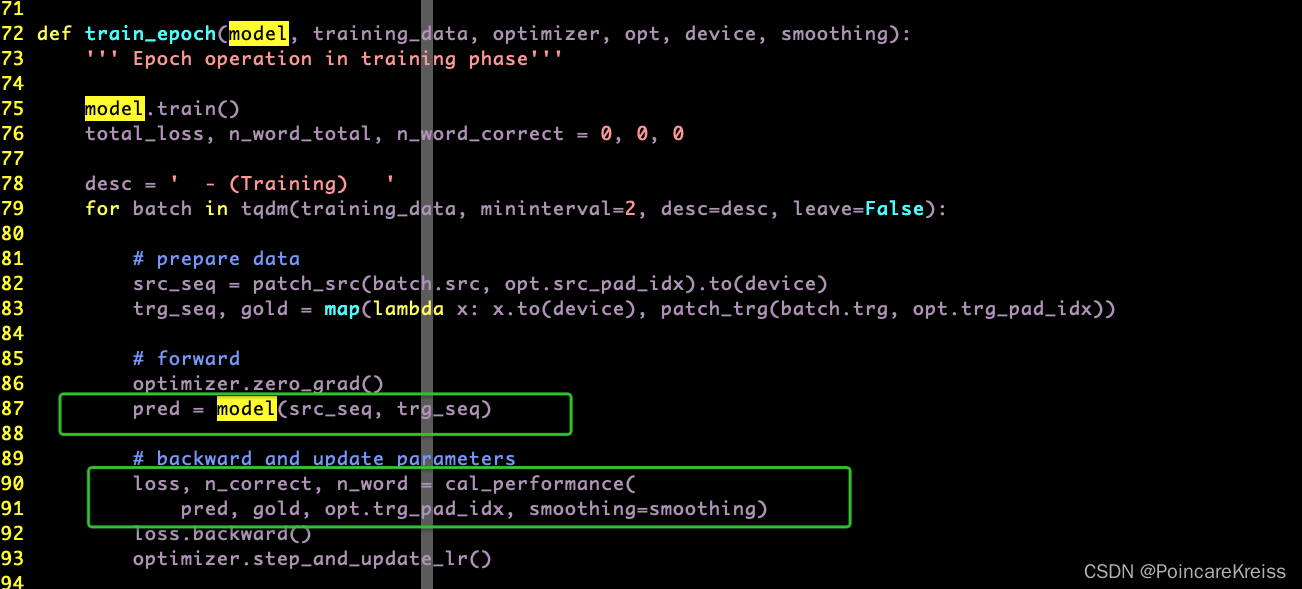
这里的Loss就是cross_entropy.
然后每个encoder其实是一堆EncoderLayer的,每个decoder其实也是一堆DecoderLayer的, 所以先大致看一下.
Encoder
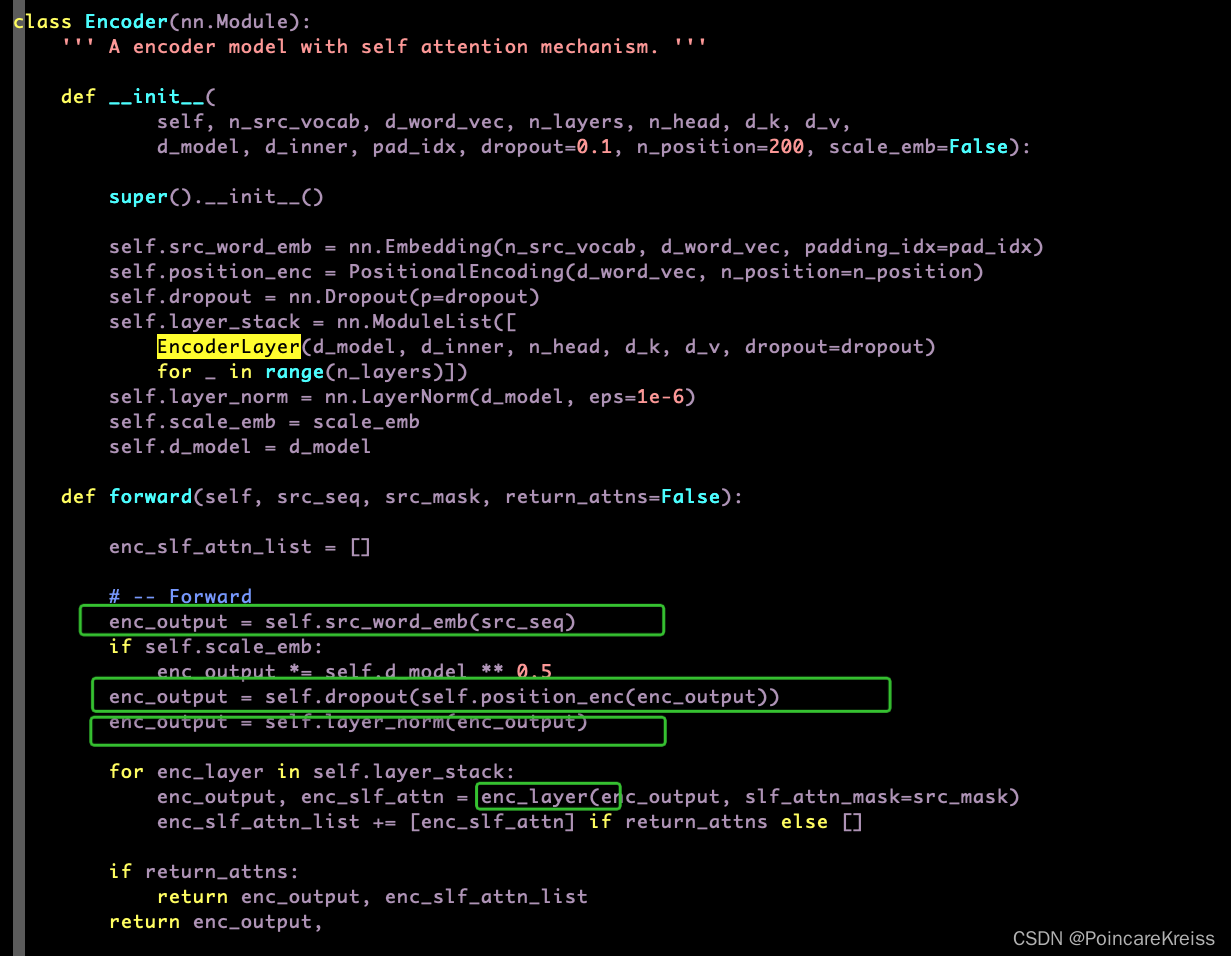
整体流程如下
- 输入 原始的src_seq, 得到word embeding, 叫做 enc_output
- 做position_encoder, 即位置编码.
- 做LayerNorm
- 过各个堆叠的encoder-layer, 每一个encoder-layer的输入都是上一层的输出.
- 返回最后一个encoder-layer的输出
什么是PositionEncoding
这个模块其实没有可以学习的参数. 这里的这个buffer的用法可以学习一下.
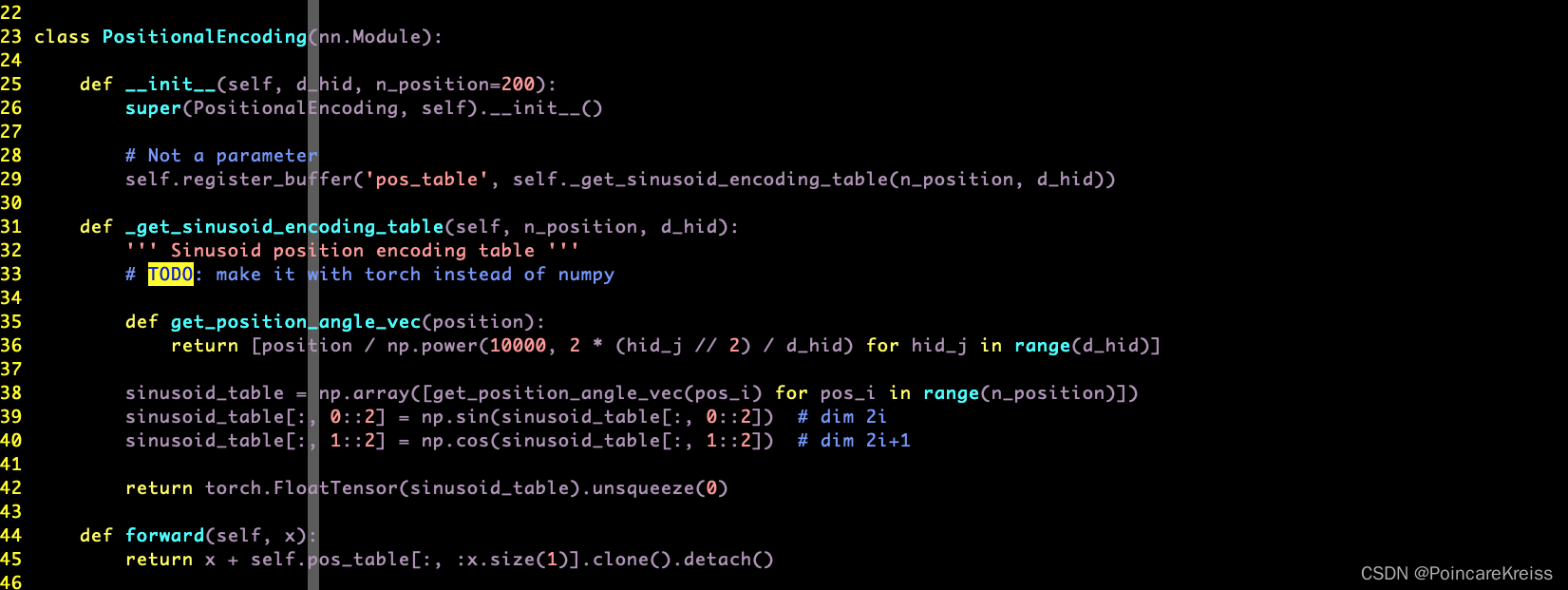
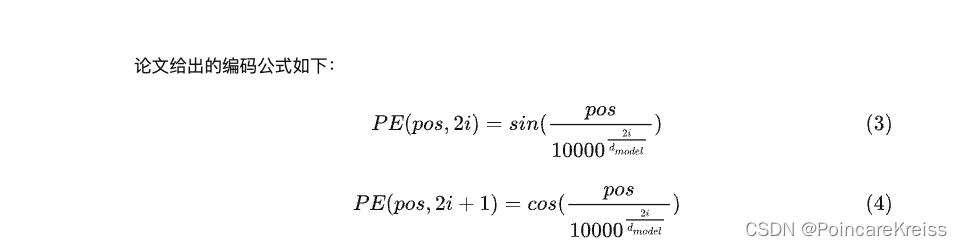
这里的这个实现还是挺简洁的. 一行就解决了.
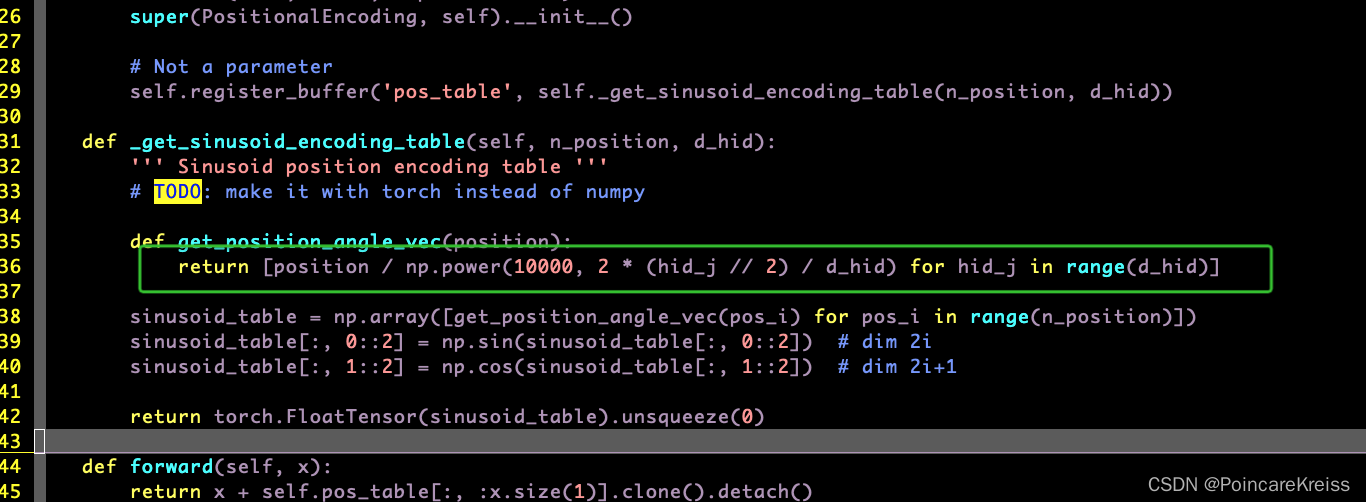
Decocer
Decoder的结构和encoder的结构几乎一样,
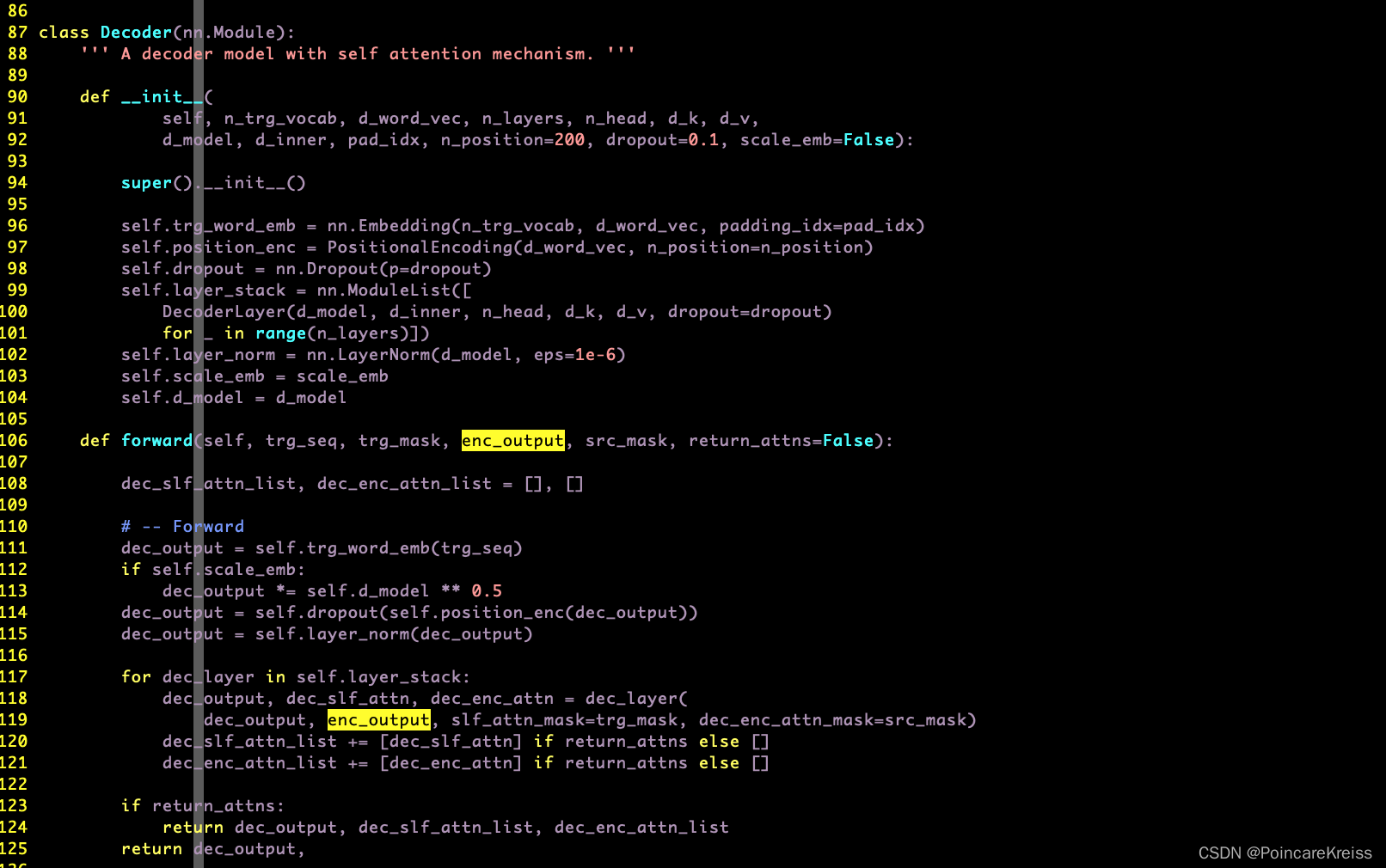
但是要注意的是, Decnoder的输入.
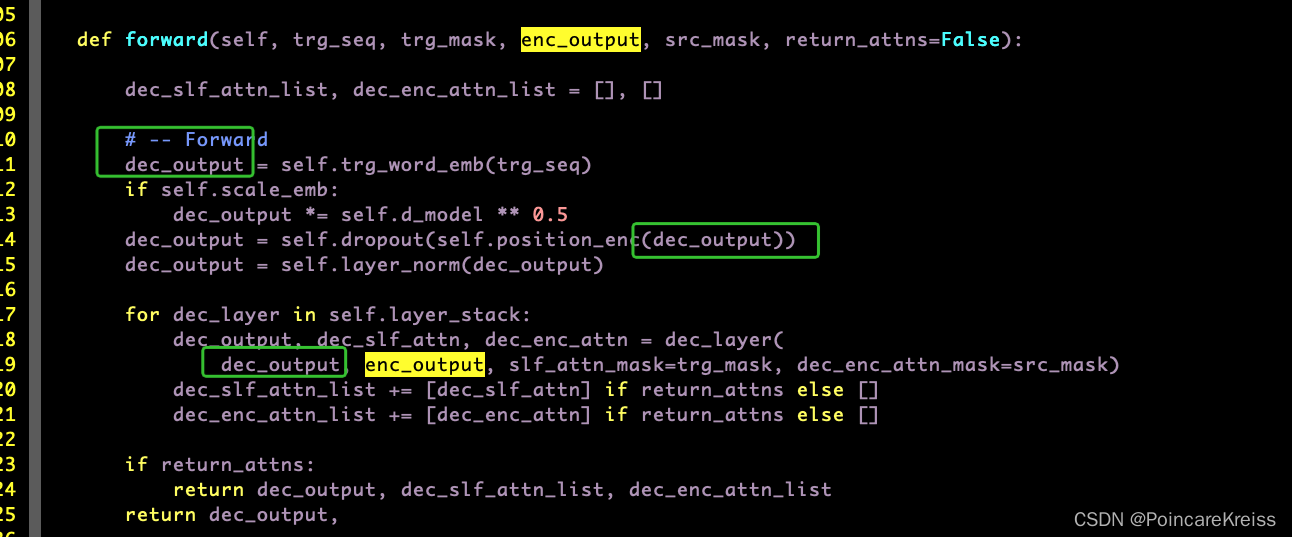
也就是说, Decoder中的positionEncoding是对groundtruth做的.
这里我有一个疑问, 推理的时候, 没有trg_seq 的时候具体是怎么做的呢?
推理时细节
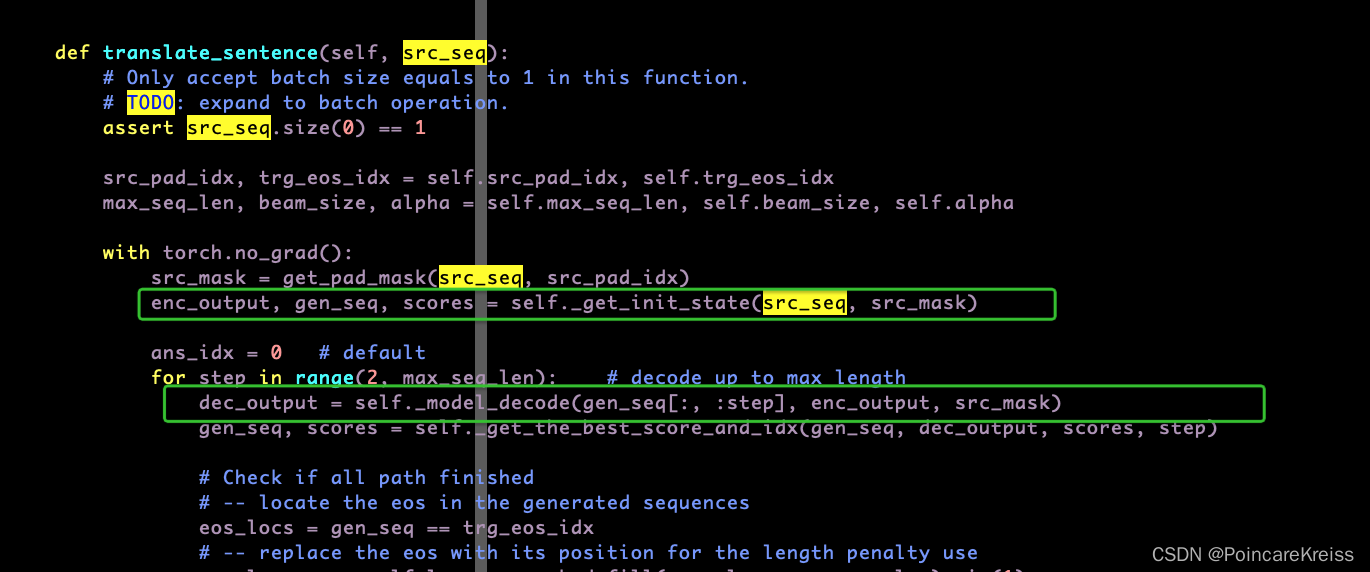
- 输入一个句子, 会先用encoder得到encoder_output.
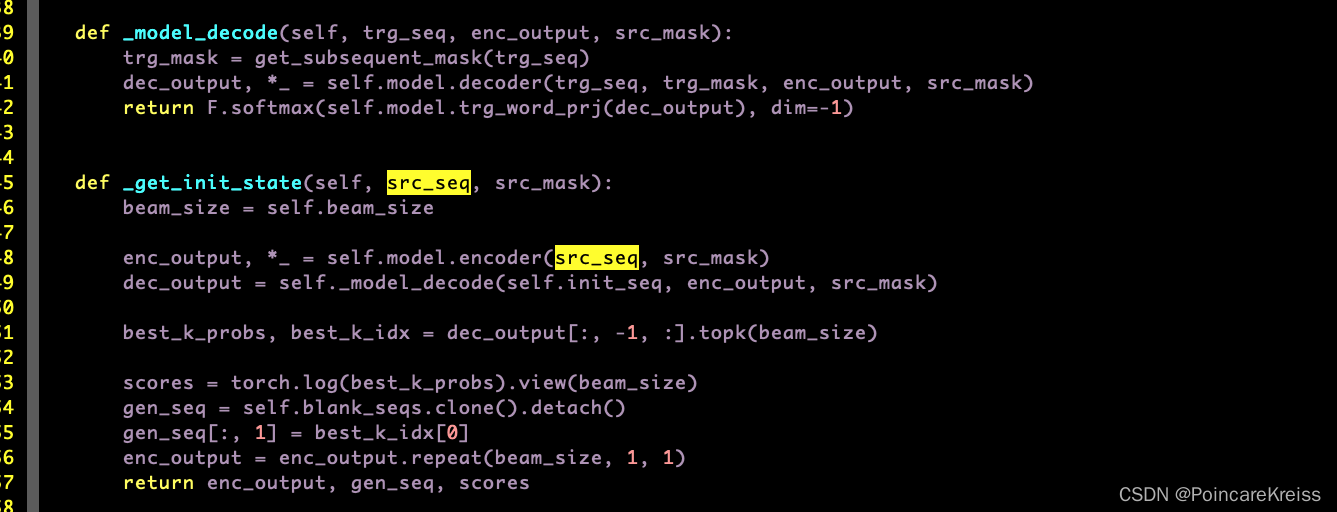
- 同时会有 init_seq 传进decoder里面
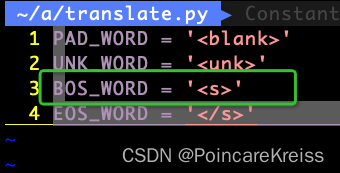
这里的init_seq 是

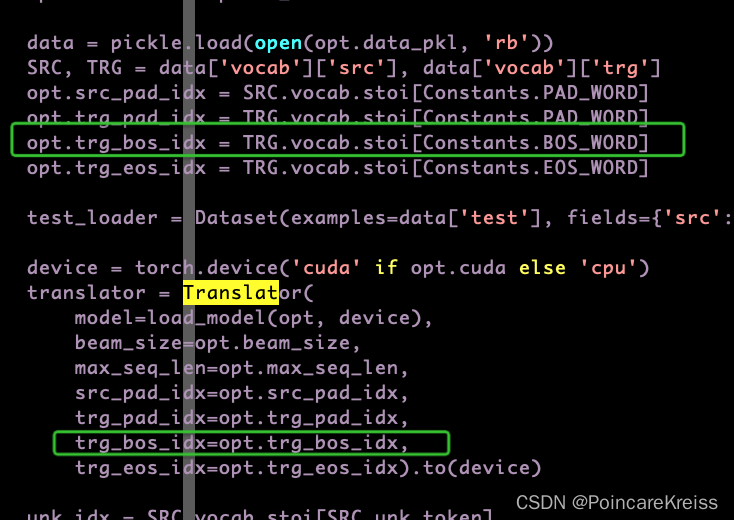
而 trg_box_idx 是一个常数. 即
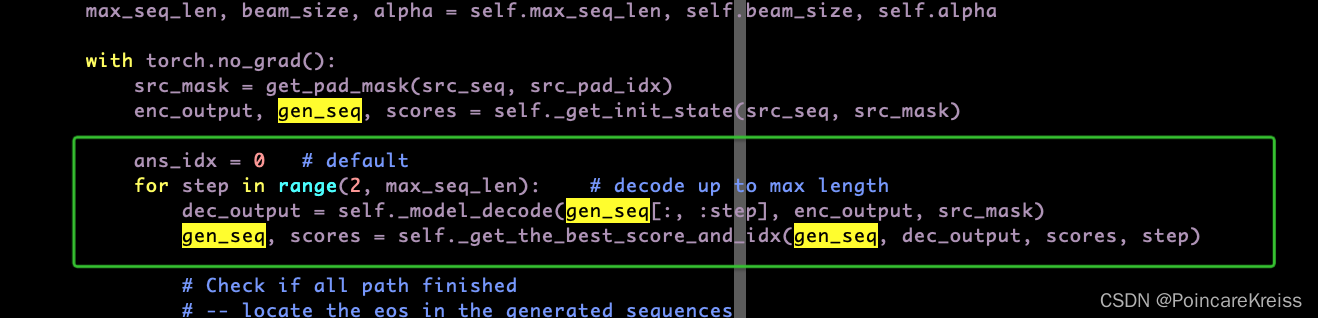
- 然后从第2个词开始, 循环作为decoder模块的输入传进去.
各模块细节
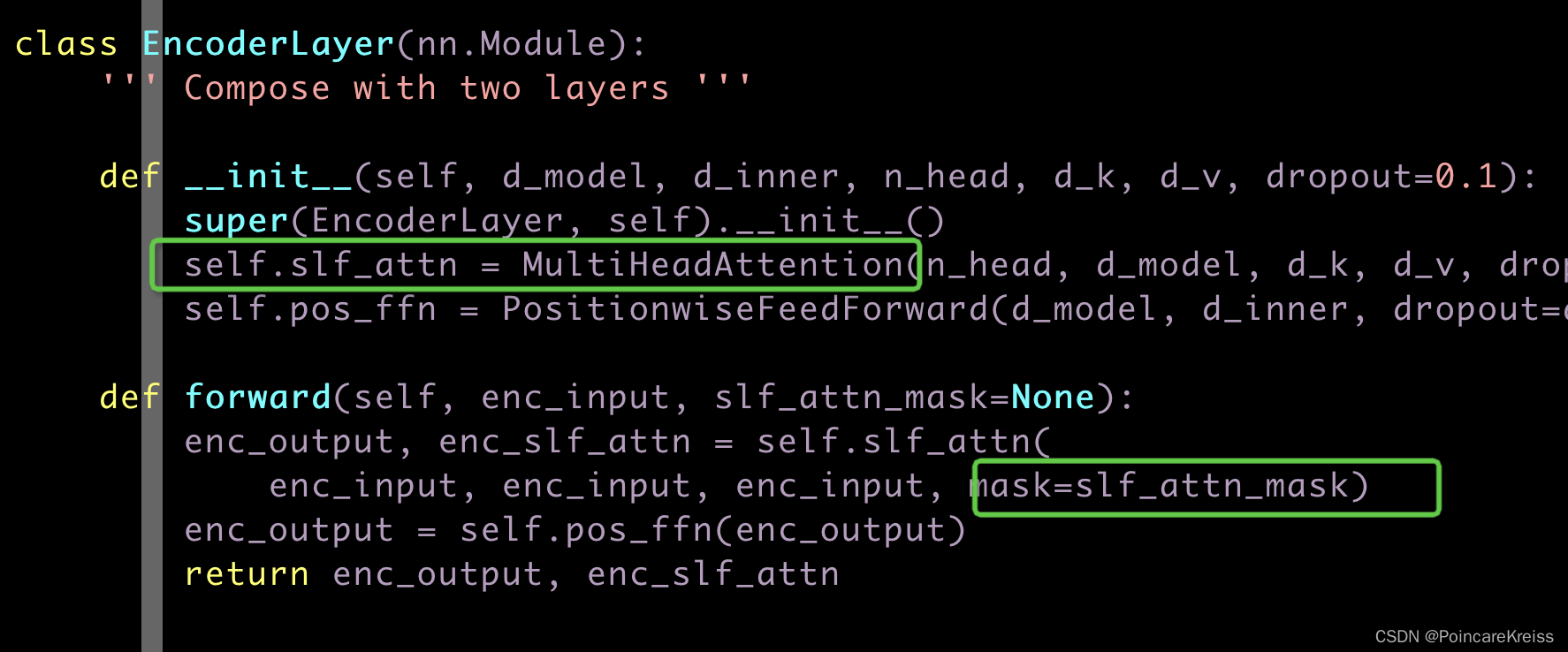
EncoderLayer

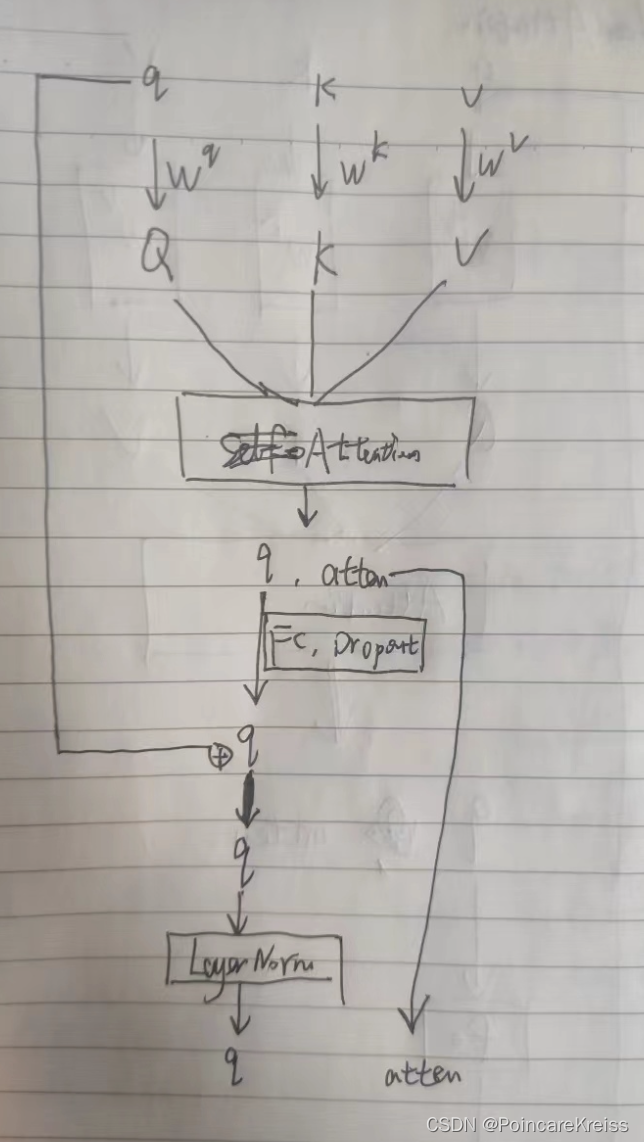
如图每个EncoderLayer包括了, self-attention, 以及 positionFFN.
这里的self-attention是MultiHeadAttention.
MultiHeadAttention
看MultiHeadAttention的操作的话,主要是经历了以下主要的几个操作
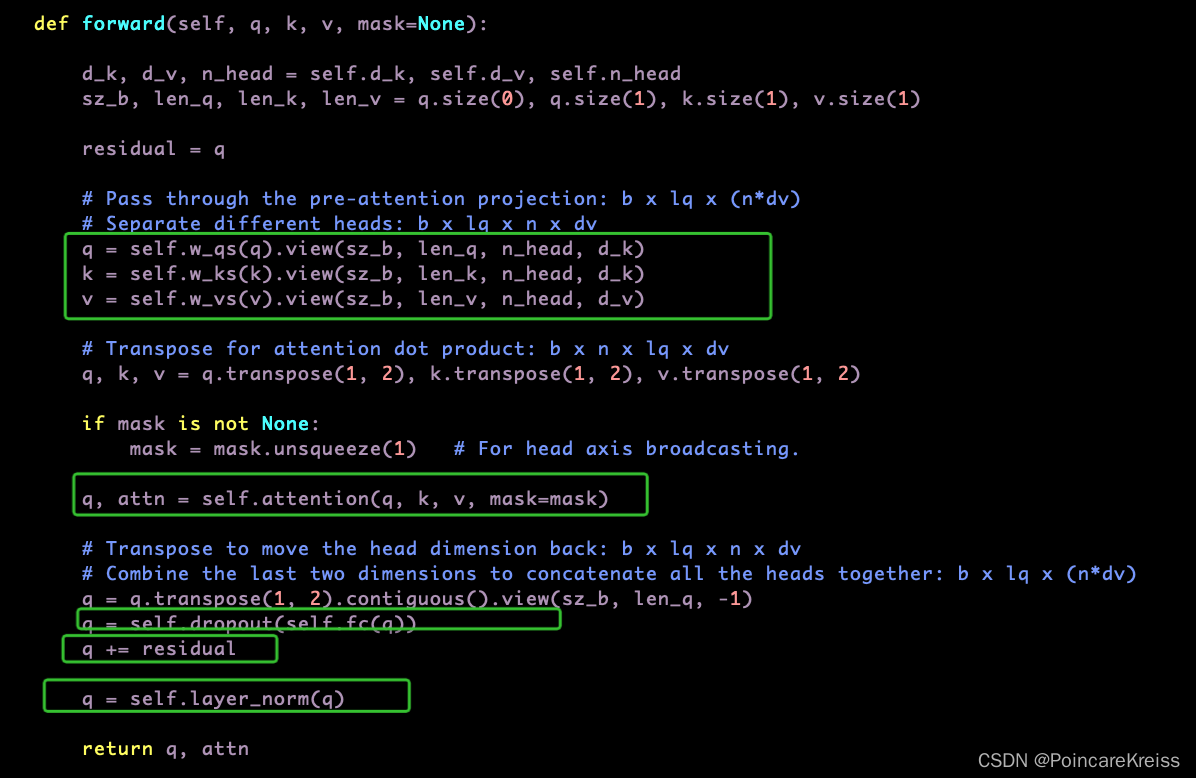
把这个图画成下面这个样子来理解:
Attention
这里的Attention其实就是这个公式
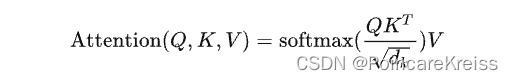
代码里面叫做 ScaledDotProductionAttention
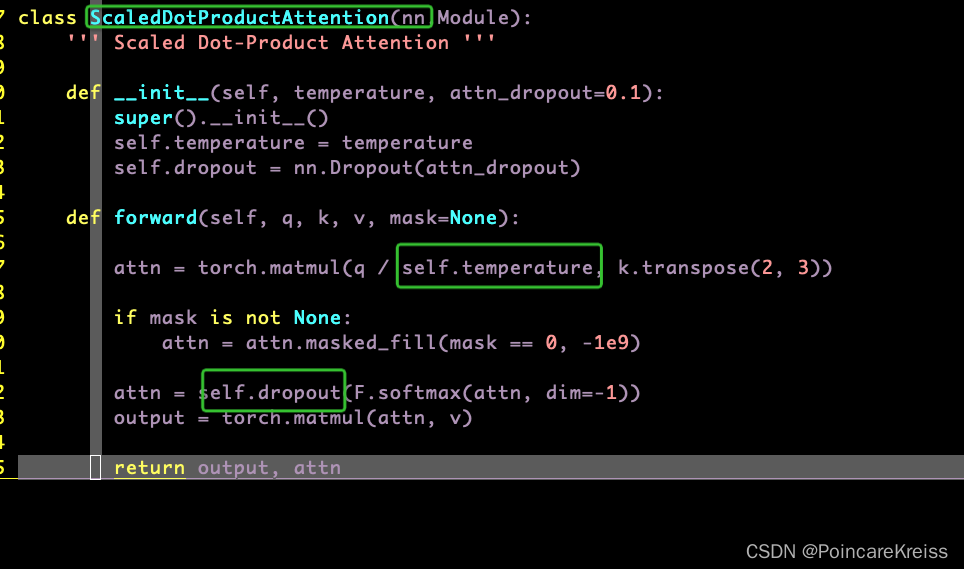
这里的temperature 是MultiHeadAttention的一个参数,
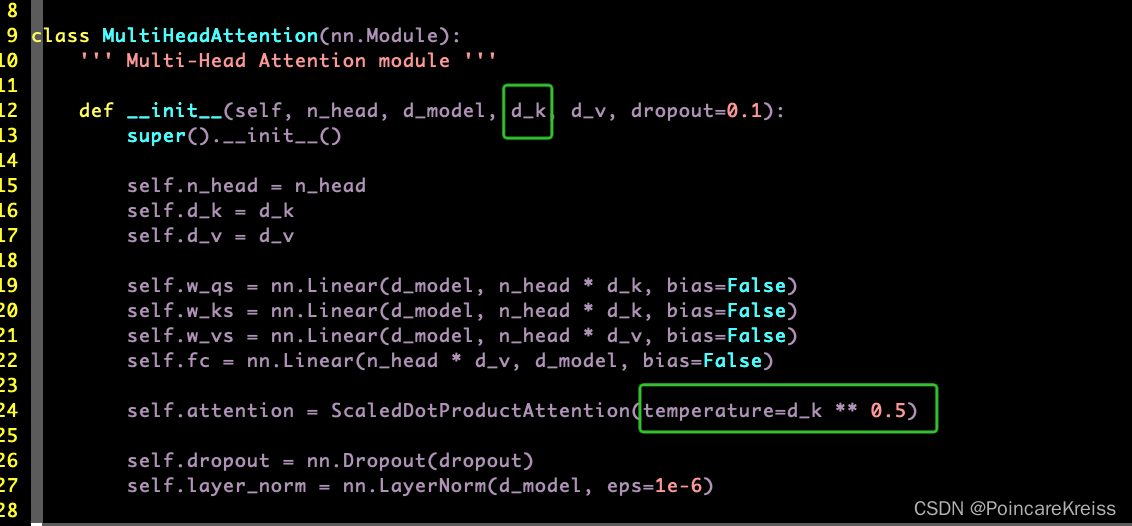
这里面需要注意的是, n_head这个参数,
在看知乎(https://zhuanlan.zhihu.com/p/48508221)上面的讲解时, 是这样的流程图
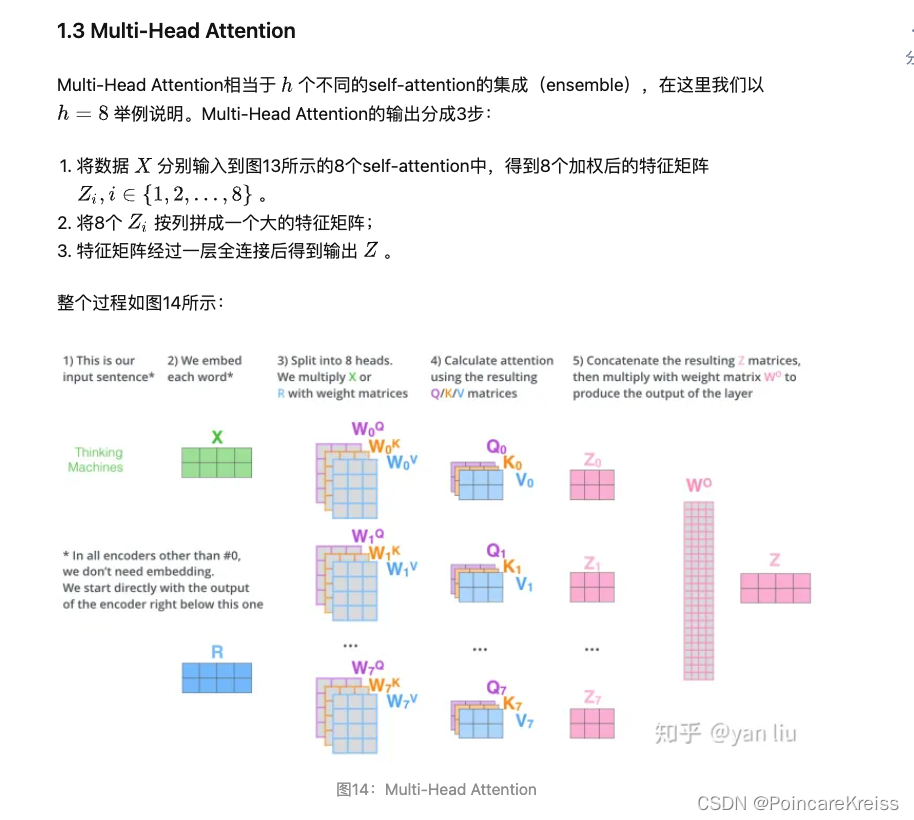
我理解其实是一样的, 一个是流程图解释,而一个是具体的实现方式.
PositionwiseFeedForward
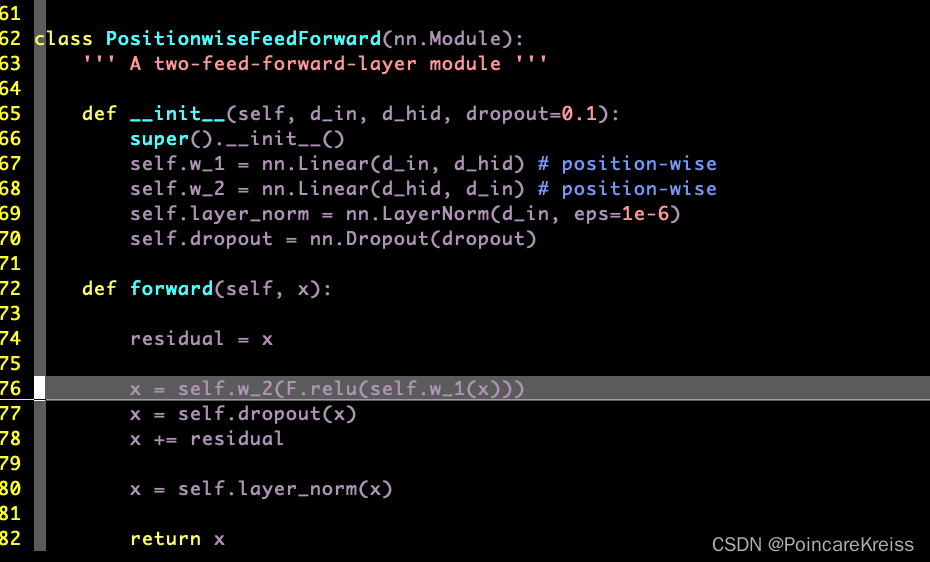
也就是经过了两个全连接层, 然后过一个droupout, 过残差, 然后再过layer_norm
至此,整个encoder 其实就是两个模块, 一个是self-attention, 一个是FFN.
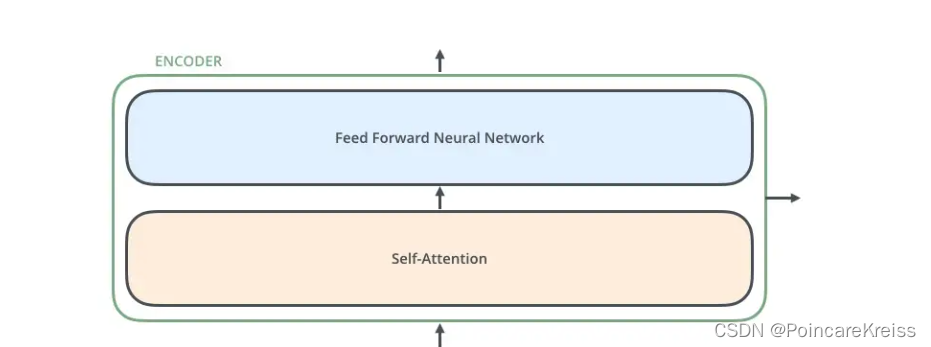
然后这里的self-attention,其实是Multi-Head-Attention.
DecoderLayer
decoder layer的模块其实和encoder的模块差不多,但是多了一个MultiHeadAttention, 这个叫encoder-decoder-attention.
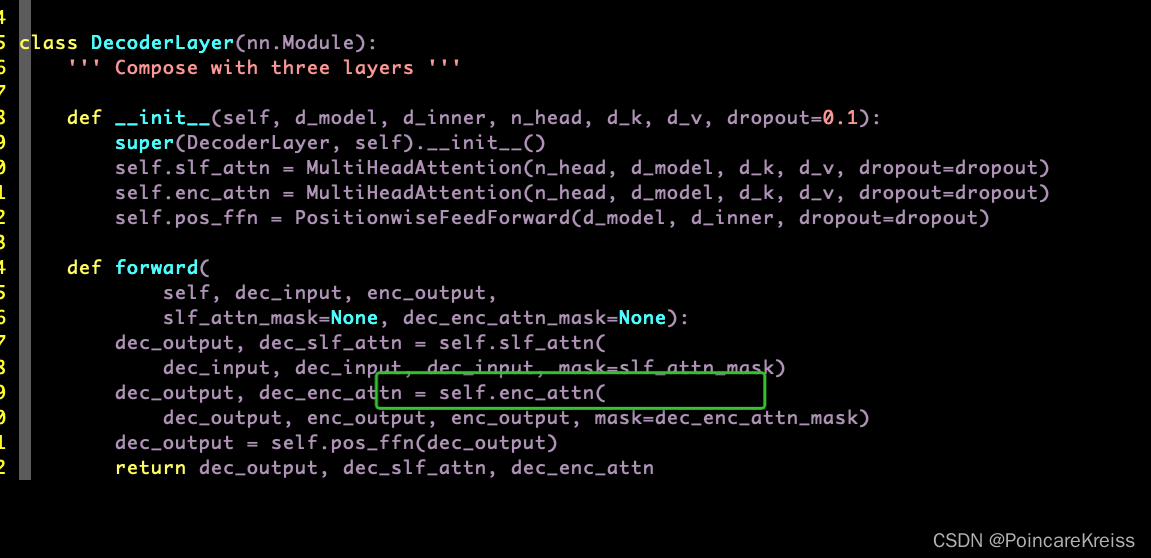
forward的时候, 会把dec_input 分三份输入 self_attion模块中,
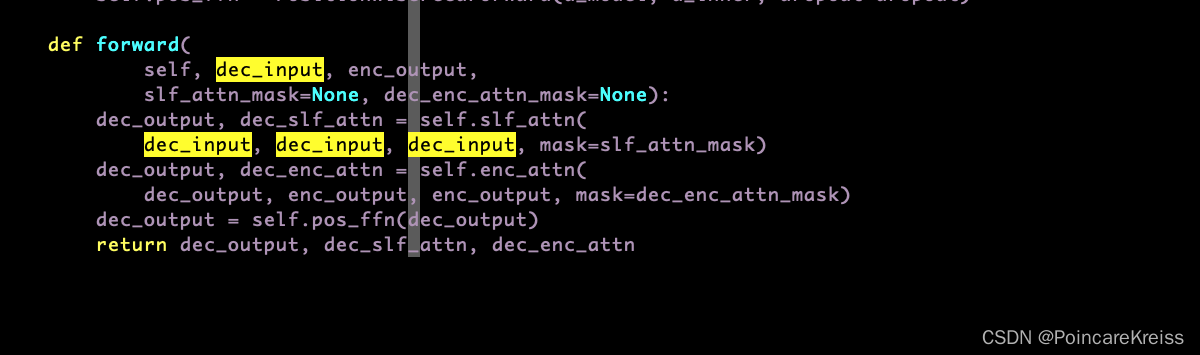
然后 encoder的output和上面的dec_output 作为encoder-decoder-attention的输入
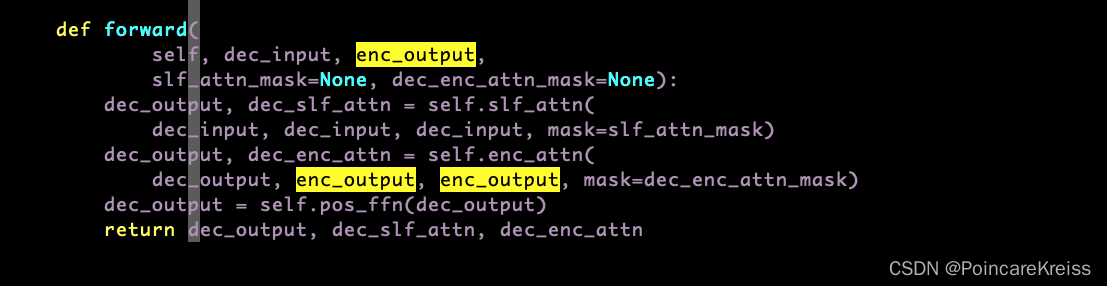
最终返回 三个东西. 分别是
dec_output, dec_slf_attn, dec_enc_attn.
其它补充
mask在encoder里如何起作用的
我们先追溯被用在了哪里
首先是这样传入encoder的

又是这样被传入每个encoder-layer的

又是这样在每个encoder-layer被使用的.
即在MultiHeadAttention中是

最终确定是在这里被使用的
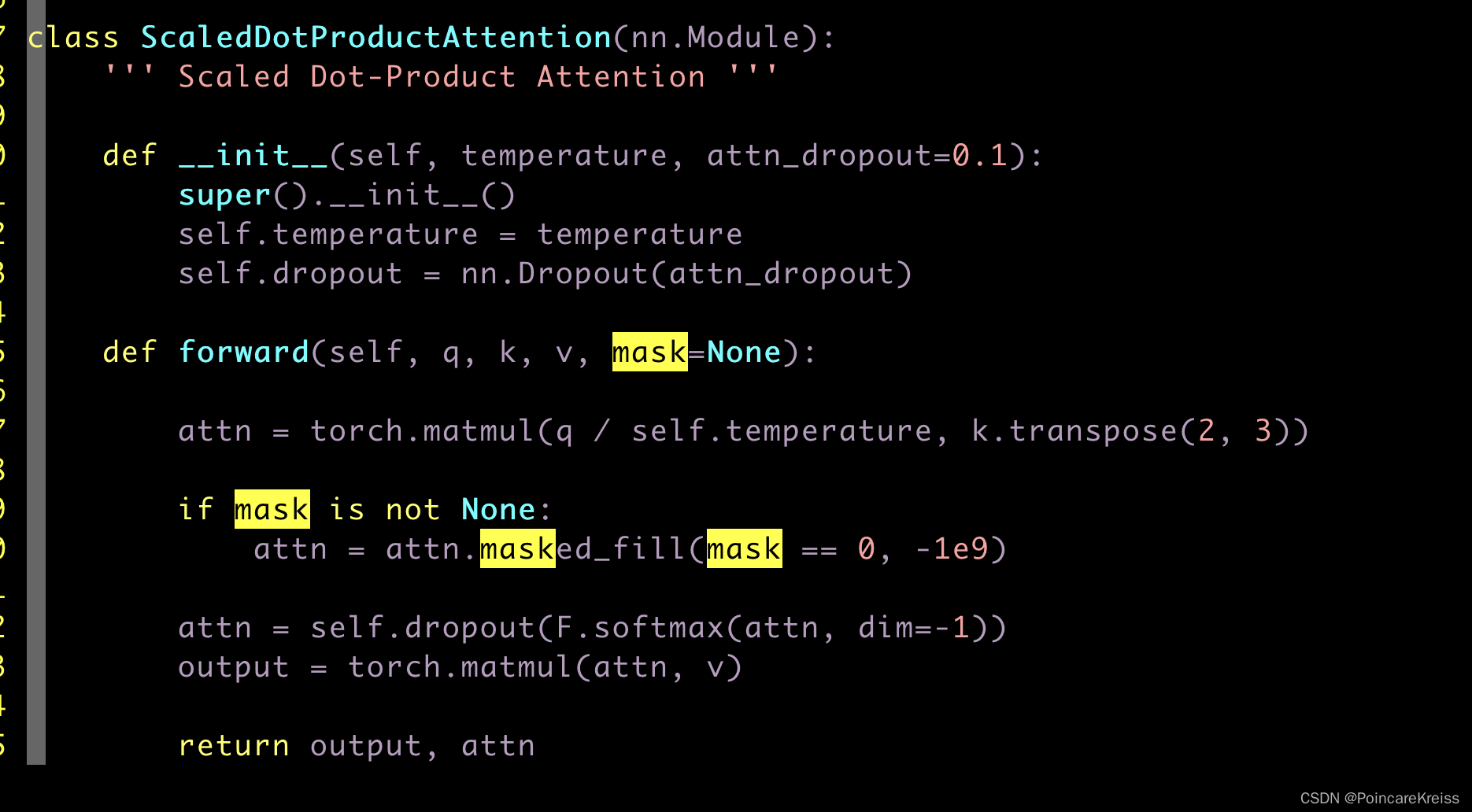
先来看一下 masked_fill如何使用, 它输入两个参数, 一个是mask, 一个是value,
也即是说, 在mask为1的那些地方, 把值改成value, 而mask为0的地方的值不改变.
即么上面的意思就是说在(mask0)的这些地方让attention的值变得非常地小, 而又经过了softmax之后, 也就是说这些mask0的地方的响应值为0. 或者说接近于0.
总结一句话就是, 传入的mask的作用. 会让其在值为mask=1的地方几乎不响应.














 6082
6082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









