








该论文发表于ECCV2022
题目:重新思考关键点表征方法:将关键点和人体姿态作为目标建模以进行多人姿态估计
Abstract
In keypoint estimation tasks such as human pose estimation,heatmap-based regression is the dominant approach despite possessing notable drawbacks: heatmaps intrinsically suffer from quantization error and require excessive computation to generate and post-process. Motivated to find a more efficient solution, we propose to model individual keypoints and sets of spatially related keypoints (i.e., poses) as objects within a dense single-stage anchor-based detection framework. Hence, we call our method KAPAO (pronounced “Ka-Pow”), for Keypoints And Poses As Objects. KAPAO is applied to the problem of single-stage multi-person human pose estimation by simultaneously detecting human pose and keypoint objects and fusing the detections to exploit the strengths of both object representations. In experiments we observe that KAPAO is faster and more accurate than previous methods, which suffer greatly from heatmap post-processing. The accuracy-speed trade-off is especially favourable in the practical setting when not using test-time augmentation.
源码: https://github.com/wmcnally/kapao.
在人体姿态估计这类关键点估计任务当中,基于热图回归的方法是目前最主要最热门的方法,尽管其受限于显著的缺陷:即热图本身受限于一种量化误差且其生成和后处理需要大量的计算开销。为了去找到一种更为有效的解决方案,本文提出了将单独关键点以及一组空间关联的关键点作为目标进行建模的方法,该方法使用了一种密集的单阶段基于锚的检测框架。因此,作者将该方法命名为KAPAO,将关键点和姿态作为目标。KAPAO适用于单阶段多人姿态估计问题,它通过同时检测人体姿态和关键点目标并且融合这些检测结果以同时运用两种目标表征能力。实验中,该方法比过往受限于热图后处理操作的方法速度更快更精确。
背景及问题(由热图方法的缺陷引入需要重新考虑关键点表征方法)
人体姿态估计任务的关键在于如何精确定位人体关键点。估计关键点位置的常用、通用方法为生成热图,即在关键点周围生成高斯概率分布,该方法因能够学习到空间位置信息、表征关键点不确定性(人工标注误差等)比直接回归(x,y)坐标点更具有泛化性和鲁棒性,精度也更高。
但是该方法面临两大缺点:
1.量化误差造成精度上限:使用热图表示,计算成本是图像分辨率的二次函数(坐标回归只需要计算GT坐标点损失,热图需要计算整张图像),因此,为了降低计算成本,标准策略都会进行下采样得到较小分辨率计算。而从较低分辨率的热图映射到原始图像中最终坐标的解码过程,这种分辨率的差距,就会造成量化误差。
(蓝色点表示GT ) 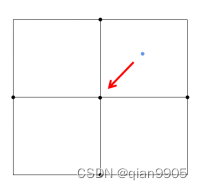
目前也有一些处理该量化误差的方法,比如用偏移向量场细化等方法。但这些方法只能减小误差,没办法打破这个上限。想要尽力打破这个上限,只能尽量使用更大分辨率热图。这些方法都会带来额外的计算开销和推理时间,降低推理速度。2.针对于多人姿态估计中,人物紧凑的情况,当两个人体关键点距离过近时,热图表征的概率分布会重合,导致重叠的热图会被认为为单个关键点以致识别不准,这种错误在自底向上方法中会导致关键点缺失错误使得分配不准,在自顶向下方法中导致定位偏差。由此提出如何有效表征关键点位置以打破热图表征缺陷带来的壁垒。
2.针对于多人姿态估计中,人物紧凑的情况,当两个人体关键点距离过近时,热图表征的概率分布会重合,导致重叠的热图会被认为为单个关键点以致识别不准,这种错误在自底向上方法中会导致关键点缺失错误使得分配不准,在自顶向下方法中导致定位偏差。
由此提出如何有效表征关键点位置以打破热图表征缺陷带来的壁垒。
做点(找出之前工作的缺陷,提出目标):
近年来,许多工作研究基于heatmap-free关键点检测的单阶段多人姿态估计方法。建立在这些前人的工作基础上,作者想要使用基于anchor的目标检测框架将关键点检测任务转换为目标检测任务的方法,将关键点位置作为Keypoints bounding box的中心点以规避热图表征。之前关于此方法的研究更适用于具有局部图像特征的关键点(如眼睛),但是在需要更多全局理解的关键点(如臀部)上表现较差。
因此,本文提出一种能够更有助于检测具有全局空间关系关键点的姿态对象表征方法。此外,该方法能同时检测关键点对象和姿态对象,同意了人的检测和关键点估计。
研究内容及方法:
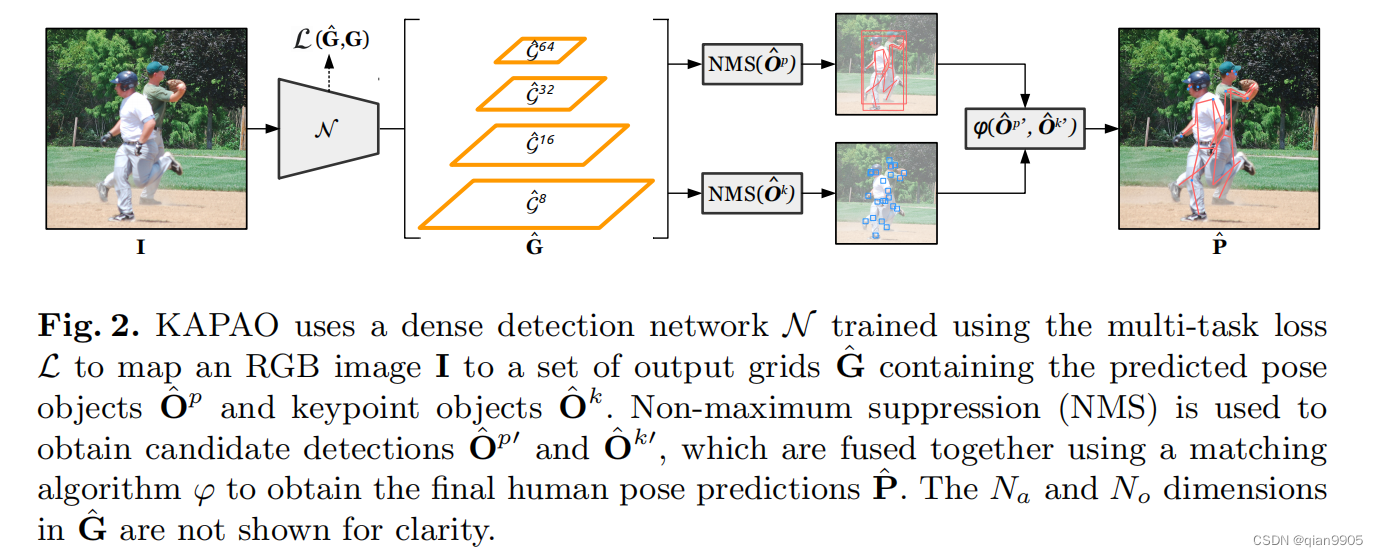
KAPAO使用一个密集检测网络同时预测一系列的关键点目标{
O
^
k
∈
O
^
k
\ \hat \mathcal O^{k}\in\hat O^{k}
O^k∈O^k }和一系列姿态目标{
O
^
p
∈
O
^
p
\ \hat \mathcal O^{p}\in\hat O^{p}
O^p∈O^p},将两者融合得到
O
^
=
O
^
k
⋃
O
^
p
\ \hat O = \hat O^{k}\bigcup\hat O^{p}
O^=O^k⋃O^p。关键点目标表示为以关键点坐标为中心的小BBOX,BBOX的尺寸为超参。姿态对象表征为一系列关键点的坐标以及一个人体目标检测框。
每种目标表征都有其独有的作用和优势。关键点目标专门用于检测具有很强局部特征的关键点,例如眼睛、耳朵、鼻子等。关键点目标没有携带任何关于人体和姿态的信息,如果直接将这些关键点目标用于多人姿态估计,就需要用自底向上的分组方法将他们解析分组到各个人体姿态。相比之下,姿态目标就能够更好地定位具有比较弱的局部特征的关键点因为他们能够让网络学习到一系列关键点之间的局部空间关系,这一点使得他们可以减轻直接进行多人姿态估计的难度即使不使用自底向上的关键点分组操作。【这一段思想特别重要】
认识到关键点目标实际上是姿态目标的子集,KAPAO网络以最小的计算开销使用一个单个的共享网络头以此同时检测两种类型的目标对象。在推理阶段,使用一种简单的基于公差的匹配算法融合关键点目标检测与人体姿态目标检测以达到更精确的人体姿态估计性能而不牺牲推理速度。
推理过程中,预测的中间边界框和关键点都会映射回原来的图像坐标中。
KAPAO的一个限制是姿态目标不包含单独的关键点置信度,因此,人体姿态预测就需要特定地区包含一系列由混合的关键点目标支持的关键点置信度。如果舍弃这个的话,关键点置信度就只能关键点目标诱导。另一限制就是训练时间长,并且GPU的存储能力需要满足一个大的input size(文中为1280)。
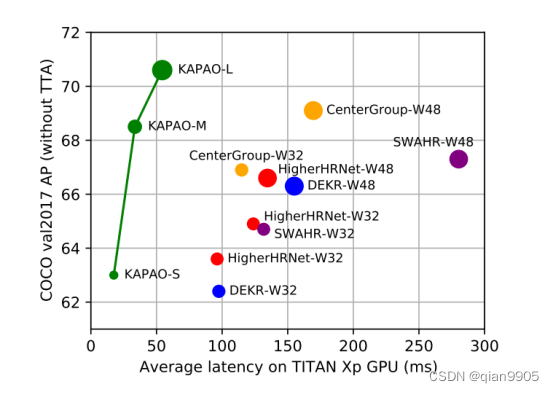
本文方法贡献更多在于其新的网络架构,即使在输入图像尺寸大的情况下也能够有比较快的推理速度。在单阶段方法当中,本文方法取得了SOTA精度,该框架在未来是个可以探索的方向。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









