








论文地址:https://arxiv.org/abs/1711.11586
代码地址:
目录
1、存在的问题
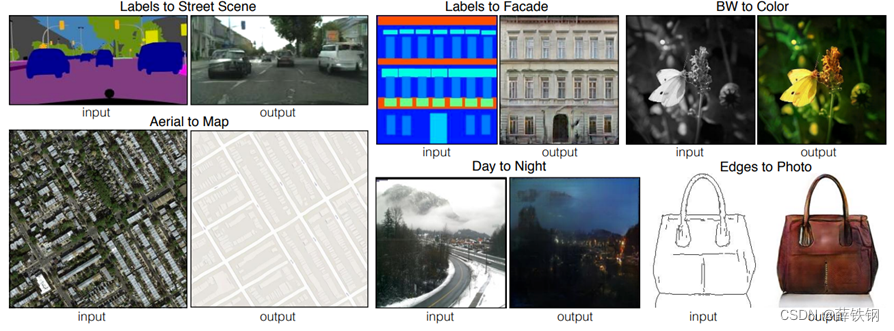
当前的图像生成技术通常是一对一的输出,即一张输入的图片只能一次性转变为一张对应的输出图片,而且输出图片始终具有相同的外观和色调,例如Pix2PixGAN。
但是,事实上,即使是在同一场景,真实的图像应该是多种多样的,应该拥有不同的背景、色调、花纹等。
因此,为了生成更加真实,同时具有多样性的图像,本文在Pix2PixGAN的基础上提出了BicycleGAN。
2、背景知识补充
2.1、GAN
生成式对抗网络GAN,其中包括两个模型:生成器和判别器。
1、生成器G(Generator)接收一个随机的噪声Z,通过这个噪声生成假图像,使这个假图像看起来像真实的训练图像;
2、判别器D(Discriminator)需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。
训练过程中,生成器G会不断尝试通过生成更好的假图像来骗过判别器,而判别器D在这过程中也会逐步提升判别能力,这就形成了对抗的局面。
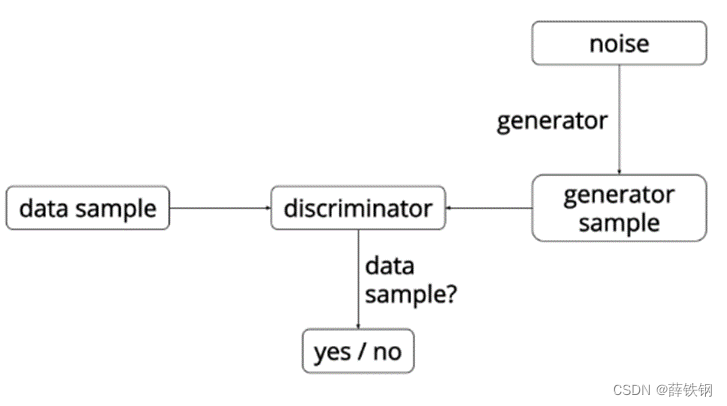
在判别器D中,用x代表图像数据,用D(x)表示D判定x为真实图像的概率,1- D(x) 表示D判定x为假图像的概率。 在判别过程中,当x来自训练数据(真实数据)时,D(x)应该趋近于 1;而当x来自生成器(假图像)时,D(x)应该趋近于0。
在生成器G中,用z代表标准正态分布中提取出的随机噪声(隐向量),用G(z)表示使用生成器从z生成的数据。G(z)的目标是将服从高斯分布的随机噪声z 通过生成网络变换为近似于真实的数据分布。D(G(z))表示生成器G生成的假图像被判定为真实图像的概率;1-D(G(z))表示生成器G生成的假图像被判定为假图像的概率。
在GAN的损失函数中,判别器希望最大化正确判断的准确率,即最大化D(x)和1-D(G(z)),生成器希望最小化假图像被识别到的概率,即最小化1-D(G(z))。
在更新D时G参数固定,更新G时D参数固定。损失函数如下所示:
min
G
max
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
[
log
D
(
x
)
]
+
E
z
∼
p
z
(
z
)
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\min_G\max_DV(D,G)=E_{x\sim p_{data}}[\log D(x)]+E_{z\sim p_z(z)}[\log(1-D(G(z)))]
GminDmaxV(D,G)=Ex∼pdata[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
2.2、VAE
变分自编码器VAE,其中包括两个模型:编码器和解码器。
1、编码器E(Encoder)的任务是将高维的输入图像数据映射到隐向量的分布上(通常是高斯分布),即在隐空间中,输入图像的潜在表示不是一个单一的点,而是一个区域;
2、解码器(Decoder)的任务是从隐空间中重构出输入图像。

在VAE的损失函数中,包括重构损失和KL散度损失:
重构损失用于最小化输入数据和重构的数据之间的差异;
KL散度损失用于将 编码器E编码后的隐向量的分布 接近一个先验分布(通常是标准正态分布),这样做是为了简化隐空间的结构,使得从隐空间中采样并通过解码器生成新的数据变得更加容易和有效。
损失函数如下所示:
V
A
E
L
o
s
s
=
Reconstruction Loss
+
β
⋅
KL Divergence Loss
\mathrm{VAE~Loss}=\text{Reconstruction Loss}+\beta\cdot\text{KL Divergence Loss}
VAE Loss=Reconstruction Loss+β⋅KL Divergence Loss
2.3、隐空间
隐空间Latent Space: 可以看作是有一个无形的、多维的数据空间。在这个空间中,每一点(或者说每一个坐标位置)都对应着一个可能的数字图像。这个空间是连续的,也就是相近的点将对应着外观相似的数字图像。
隐编码/隐向量/隐变量: 如果从这个隐空间中随机选取一个点,这个点的坐标(也就是一组数字)就是一个隐编码或隐向量。例如,假设在这个空间中随机选取了点0.8,−1.3,0.5,这组数字就是隐向量。将这个隐向量输入到GAN模型中,模型会根据这个向量生成对应的具体的数字图像。比如,根据向量0.8,−1.3,0.5,可能生成的是一个“2”的图像。就像在图书馆中根据坐标寻找相应的图书一样。使用隐向量可以简化复杂的高维数据,表示数据的分布,使模型能在无需标签的情况下学习数据的特性。
在GAN中,输入到生成器中的随机噪声Z就是隐变量,随机噪声作为输入提供了一个起点,让生成器可以从这点出发,去探索数据的隐空间,学习如何映射到复杂多样的数据分布上。
在VAE中,编码器将输入图像映射到隐向量的分布上,随后从这个分布上随机采样,以获得与输入图像数据的隐向量相似的隐向量,最后,解码器根据这个相似的隐向量生成和输入图像数据相似的图像。
2.4、Pix2PixGAN
Pix2Pix是基于条件生成对抗网络(cGAN)实现的一种深度学习图像转换模型,其中包括两个模型:生成器和判别器。
cGAN与GAN不同的是,生成器和判别器都增加额外的信息y为条件变量, y可以是任意信息,例如类别标签,语义信息,或者其他模态的数据,使得图像生成能够朝规定的方向进行。例如,输入“一只狗在奔跑”,输出即为一只狗在奔跑的图。
如果条件变量y是类别标签,可以看做cGAN是把纯无监督的GAN变成有监督的模型的一种改进。

Pix2Pix中,输入图片x作为cGAN的条件,被输入到生成器G和判别器D中。生成器G的输入是x(x是需要转换的图片),输出是生成的图片G(x)。判别器D的作用是在轮廓图x的条件下,对于生成的图片G(x)判断为假,对于真实图片y判断为真。

Pix2Pix 的生成器模型基于 U-Net 结构,判别器模型采用PatchGAN。
普通的GAN判别器是将输入映射成一个实数,即输入样本为真样本的概率。PatchGAN将输入映射为NxN的patch(矩阵)X,Xij的值代表输入图像的某个局部区域(感受野)为真样本的概率,将Xij求均值,即为判别器最终输出。这种求平均的方式能够考虑到图像的不同部分的影响,更能关注图像细节。
3、算法简介
本文提出了一种处理多对多的图像生成问题的网络:BicycleGAN,包括:
1、cVAE-GAN(条件变分自编码GAN): 将真实图像编码到隐空间中,使用编码器将真实图像进行潜在编码,再将编码后的随机噪声和输入图像进行结合生成输出。

2、cLR-GAN(条件潜在回归GAN): 条件生成器从随机抽样的隐向量产生一个输出,当它作为输入给编码器时,编码返回与随机抽样相同的隐向量。

3、BicycleGAN: 将上述两种方法结合起来,构成双向映射的结构
对于PixPixGAN而言,生成器更多地依赖于输入图像的具体内容而非随机噪声来重建输出。因此,即使添加了噪声,只要输入图像信息足够丰富,生成的输出仍然会依照输入的结构和特征进行构建。
与传统的pix2pix模型不同,BicycleGAN在生成过程中引入了隐变量。由于隐空间是连续的,相近的点将对应着外观相似的图像,通过对隐空间中的隐向量进行采样,BicycleGAN可以从同一输入生成多个不同的输出,每个输出反映了隐向量不同的可能实现。
并且,采用双向映射结构,不仅可以由隐编码映射得到输出,也可以由输出反过来生成对应的隐编码,这可以防止两个不同的隐编码生成同样的输出,避免输出的单一性。假设只用单个方向的映射,不同的输入可能对应着同样的输出。但加了反向的映射的话,反向的过程中用同样的输出是不可能产生不同的输入的。双形映射结构就可以避免不同的输入产生同样的输出。

4、算法细节
4.1、cVAE-GAN
B:ground-truth
A:输入图像input(可能是边缘草图,全景分割的图像,黑夜图像等)
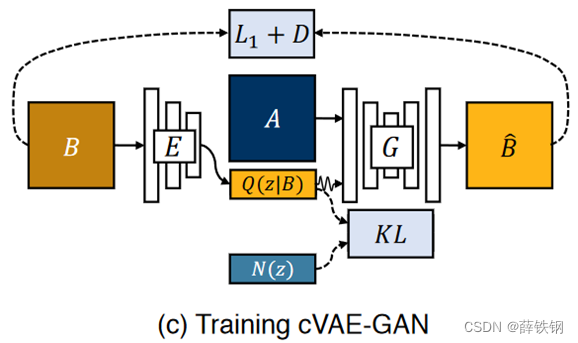
(1) VAE中的编码器E对输入的ground-truth图片B进行编码,得到编码后的隐向量z,z的分布为Q(z|B);(即VAE中的内容)
(2)计算Q(z|B)和事先定义好的服从高斯分布的随机噪声的分布N(z)之间的KL散度,使编码后的隐向量z服从高斯分布;(即VAE中的内容)
(3)将服从高斯分布的隐向量z和输入图像A结合,送入生成器G中,得到重构的假图像 B ^ \hat{B} B^。(即cGAN中的内容)
训练中的数据流为:
B
−
>
Z
−
>
B
^
B->Z->\hat{B}
B−>Z−>B^
最终,总的损失函数包括:对抗损失、KL散度损失、图像重建L1损失:
G
∗
,
E
∗
=
arg
min
G
,
E
max
D
L
G
A
N
V
A
E
(
G
,
D
,
E
)
+
λ
L
1
V
A
E
(
G
,
E
)
+
λ
K
L
L
K
L
(
E
)
.
G^{*},E^{*}=\arg\min_{G,E}\max_{D}\quad\mathcal{L}_{\mathrm{GAN}}^{\mathrm{VAE}}(G,D,E)+\lambda\mathcal{L}_{1}^{\mathrm{VAE}}(G,E)+\lambda_{\mathrm{KL}}\mathcal{L}_{\mathrm{KL}}(E).
G∗,E∗=argG,EminDmaxLGANVAE(G,D,E)+λL1VAE(G,E)+λKLLKL(E).
4.2、cLR-GAN
B:ground-truth
A:输入图像input(可能是边缘草图,全景分割的图像,黑夜图像等)
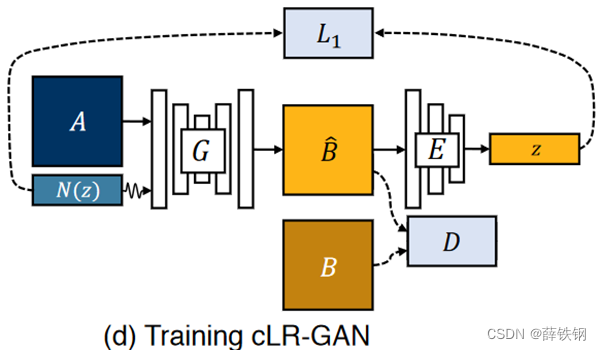
(1) 类似于cGAN,输入图像A和事先定义好的服从高斯分布的随机噪声z输入到GAN的生成器G中得到假图像𝐵 ̂;(即cGAN中的内容)
(2)使用和cVAE-GAN中相同的VAE编码器E对假图像进行编码得到隐向量z;(即VAE中的内容)
(3)这里计算隐向量z和服从高斯分布的噪声的损失,使编码后的隐向量z服从高斯分布;同时计算假图像和真实图像之间的对抗损失。
训练中的数据流为:
z
−
>
B
^
−
>
z
^
z->\hat{B}->\hat{z}
z−>B^−>z^
最终,总的损失函数包括:对抗损失、服从高斯分布的噪声和隐向量的L1损失:
G
∗
,
E
∗
=
arg
min
G
,
E
max
D
L
G
A
N
(
G
,
D
)
+
λ
l
a
t
e
n
t
L
1
l
a
t
e
n
t
(
G
,
E
)
G^*,E^*=\arg\min_{G,E}\max_{D}\quad\mathcal{L}_{\mathrm{GAN}}(G,D)+\lambda_{\mathrm{latent}}\mathcal{L}_{1}^{\mathrm{latent}}(G,E)
G∗,E∗=argG,EminDmaxLGAN(G,D)+λlatentL1latent(G,E)
4.3、BicycleGAN
将二者结合形成BicycleGAN
生成器G采用Unet
判别器D采用patchGAN
编码器E采用ResNet
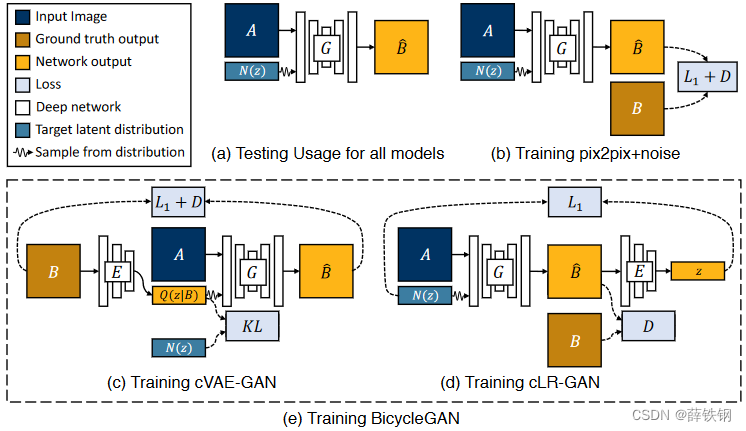
在两个模型中,采用相同的生成器和编码器,判别器使用不同尺度的patchGAN (70X70,140X140),也就是一共四个子网络。

训练时,两个模型一起训练,但是处理不同的图像对,即两次获取数据:

执行前向传递时同时收集两个模型的输出:

5、实验
5.1、可视化结果
BicycleGAN方法可以一次性产生多张图片,产生的结果既真实又多样。
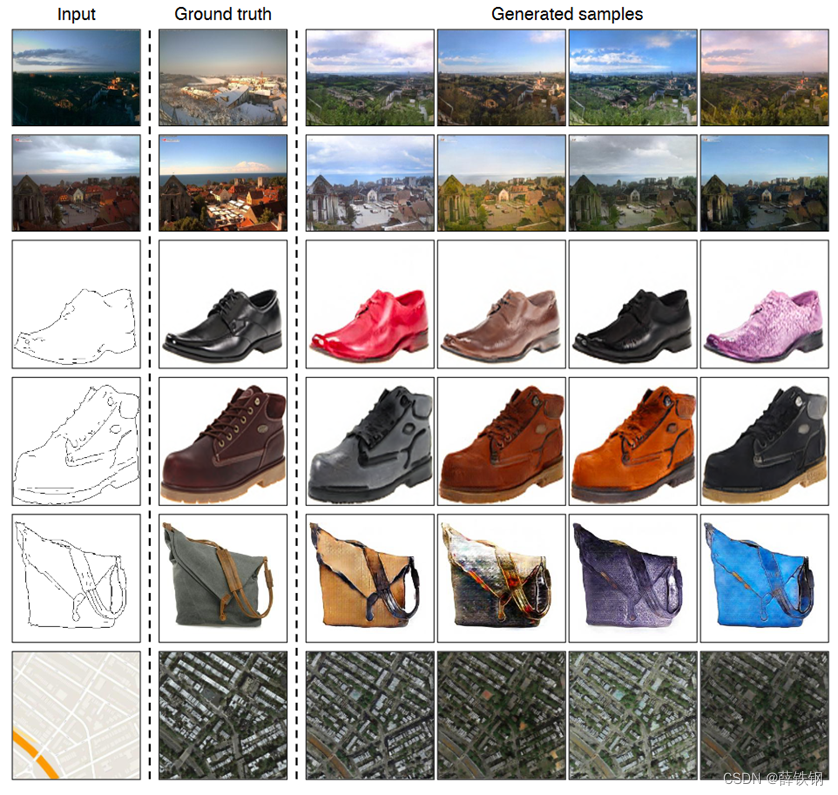
5.2、定性分析-关注数据质量
在facades数据集上的结果:

5.3、定量分析-关注数据量
评估真实性和多样性:
AMT Fooling:用于评估生成模型产生的输出与真实值之间的区分难度,越高越好;
LPIPS:用于度量两张图像之间的差别,这里用来度量真实图像和生成图像之间的差别,越小越好;
BicycleGAN方法在保持多样性的同时,获得了更高的真实性。


5.4、编码器结构
测试两种编码器架构:
CNN和ResNet
下表报告的是重建损失,越小越好。可以看出编码器采用ResNet性能好一些。

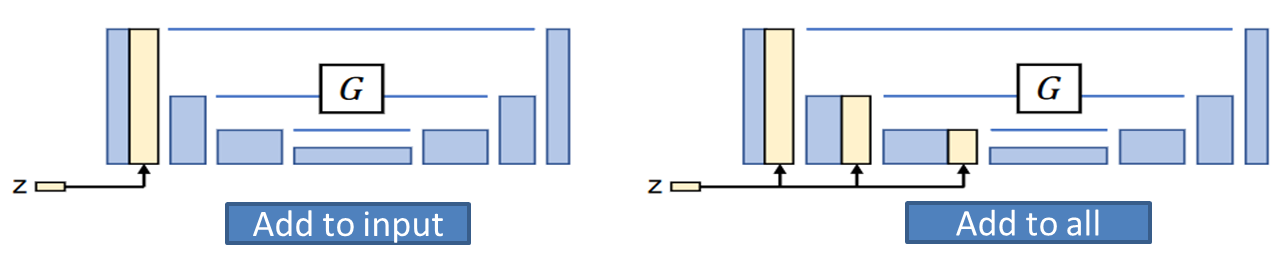
5.5、隐向量z的插入方式
z和图片A的结合送入生成器G的结合方法:
Add_to_input:直接与输入图像进行concat
Add_to_all:将z插入到生成器的下采样路径中的其他层中
下表报告的是重建损失,越小越好。可以看出Add_to_input性能好一点点。

5.6、隐向量z的长度
考虑三种隐向量长度:
2,8,256
非常低的维度可能会使生成的图像多样性不足,
非常高的维度可能会使采样困难,
具体取多大维度要看实际应用要求。
















 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









