







 本文探讨了开放世界目标检测(OVD)的重要性,指出现有目标检测方法的局限性,如需要预先定义目标集合和依赖大量标注数据。OVD通过结合无类别区域检测器和跨模态模型,解决了这些问题,适用于未知物体检测。文章介绍了OVR-CNN、RegionCLIP和CORA等OVD领域的代表性工作,并讨论了OVD在多模态AGI发展中的潜力和未来应用。
本文探讨了开放世界目标检测(OVD)的重要性,指出现有目标检测方法的局限性,如需要预先定义目标集合和依赖大量标注数据。OVD通过结合无类别区域检测器和跨模态模型,解决了这些问题,适用于未知物体检测。文章介绍了OVR-CNN、RegionCLIP和CORA等OVD领域的代表性工作,并讨论了OVD在多模态AGI发展中的潜力和未来应用。
作者:王斌 谢春宇 冷大炜
引言
目标检测是计算机视觉中的一个非常重要的基础任务,与常见的的图像分类/识别任务不同,目标检测需要模型在给出目标的类别之上,进一步给出目标的位置和大小信息,在CV三大任务(识别、检测、分割)中处于承上启下的关键地位。当前大火的多模态GPT4在视觉能力上只具备目标识别的能力,还无法完成更高难度的目标检测任务。而识别出图像或视频中物体的类别、位置和大小信息,是现实生产中众多人工智能应用的关键,例如自动驾驶中的行人车辆识别、安防监控应用中的人脸锁定、医学图像分析中的肿瘤定位等等。
已有的目标检测方法如YOLO系列、R-CNN系列等耳熟能详的目标检测算法在科研人员的不断努力下已经具备很高的目标检测精度与效率,但由于现有方法需要在模型训练前就定义好待检测目标的集合(闭集),导致它们无法检测训练集合之外的目标,比如一个被训练用于检测人脸的模型就不能用于检测车辆;另外,现有方法高度依赖人工标注的数据,当需要增加或者修改待检测的目标类别时,一方面需要对训练数据进行重新标注,另一方面需要对模型进行重新训练,既费时又费力。一个可能的解决方案是,收集海量的图像,并人工标注Box信息与语义信息,但这将需要极高的标注成本,而且使用海量数据对检测模型进行训练也对科研工作者提出了严峻的挑战,如数据的长尾分布问题与人工标注的质量不稳定等因素都将影响检测模型的性能表现。
发表于CVPR2021的文章OVR-CNN[1]提出了一种全新的目标检测范式:开放词集目标检测(Open-Vocabulary Detection,OVD,亦称为开放世界目标检测),来应对上文提到的问题,即面向开放世界未知物体的检测场景。OVD由于能够在无需人工扩充标注数据量的情形下识别并定位任意数量和类别目标的能力,自提出后吸引了学术界与工业界持续增长的关注,也为经典的目标检测任务带来了新的活力与新的挑战,有望成为目标检测的未来新范式。具体地,OVD技术不需要人工标注海量的图片来增强检测模型对未知类别的检测能力,而是通过将具有良好泛化性的无类别(class-agnostic)区域检测器与经过海量无标注数据训练的跨模态模型相结合,通过图像区域特征与待检测目标的描述性文字进行跨模态对齐来扩展目标检测模型对开放世界目标的理解能力。跨模态和多模态大模型工作近期的发展非常迅速,如CLIP[2]、ALIGN[3]与R2D2[4]等,而它们的发展也促进了OVD的诞生与OVD领域相关工作的快速迭代与进化。
OVD技术涉及两大关键问题的解决:1)如何提升区域(Region)信息与跨模态大模型之间的适配;2)如何提升泛类别目标检测器对新类别的泛化能力。从这个两个角度出发,下文我们将详细介绍一些OVD领域的相关工作。
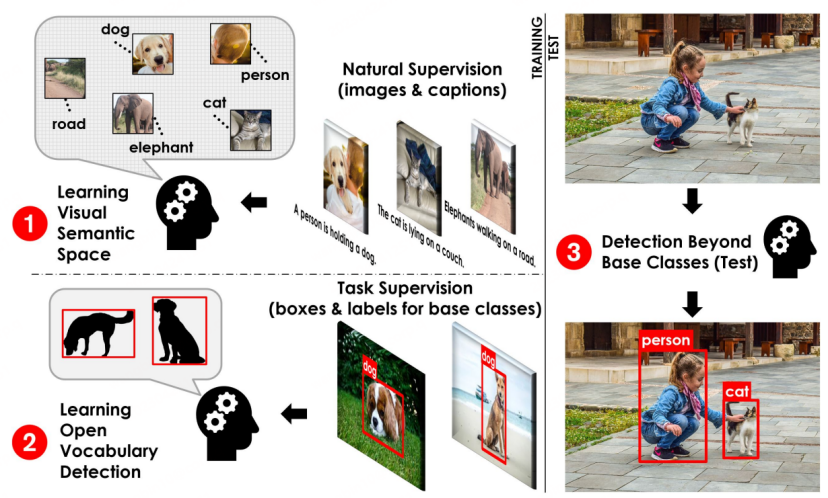
OVD基本流程示意[1]
OVD的基础概念:OVD的使用主要涉及到 few-shot 和 zero-shot两大类场景,few-shot是指有少量人工标注训练样本的目标类别,zero-shot则是指不存在任何人工标注训练样本的目标类别。在常用的学术评测数据集COCO、LVIS上,数据集会被划分为Base类和Novel类,其中B
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









