






倒数排名融合 (RRF) 是一种算法,可评估多个以前的排名结果中的搜索分数以生成统一的结果集。在RAG搜索中,每当并行执行两个或更多个查询时,都会使用 RRF。每个查询都会生成一个排名结果集,RRF 可用于将排名合并和同质化为单个结果集,在查询响应中返回。始终使用 RRF 的示例方案包括混合搜索和并行执行的多个矢量查询。
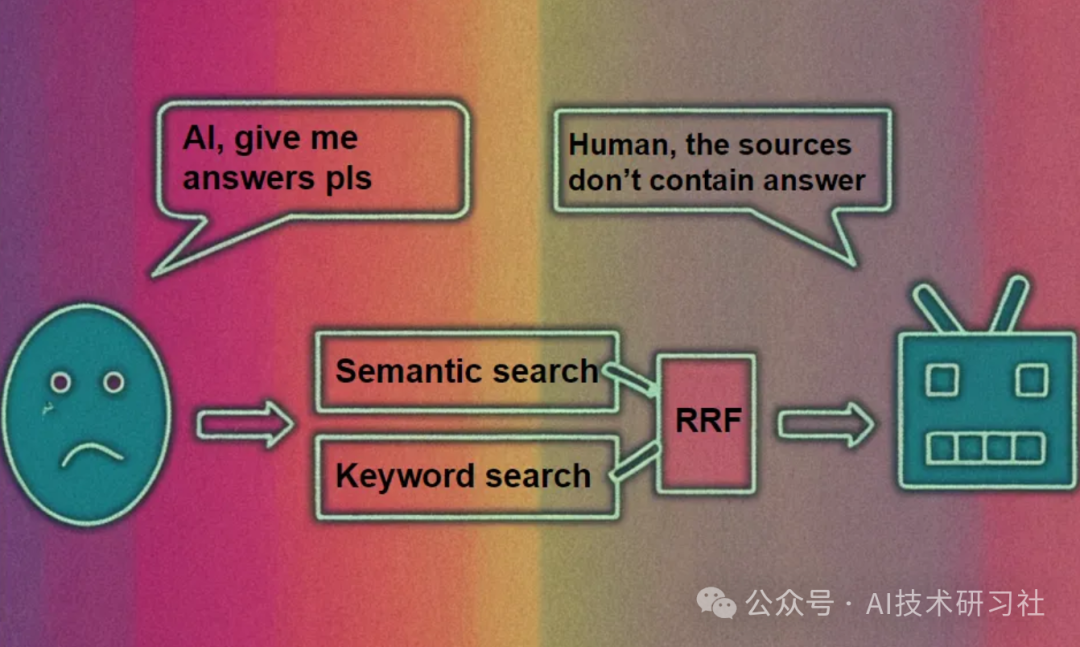
RRF 基于倒数排名的概念,即搜索结果列表中第一个相关文档的排名的倒数。 该方法的目标是考虑项目在原始排名中的位置,并赋予在多个列表中排名较高的项目更高的重要性。这有助于提高最终排名的整体质量和可靠性,使其对融合多个有序搜索结果的任务更加有用。
RRF 算法详解
检索增强生成(RAG)是一种将检索模型和生成模型优势结合起来的强大自然语言处理技术。RAG 系统的成功在很大程度上取决于检索阶段的表现,如果检索器无法找到相关文档,系统的精度就会降低,并增加生成内容出现幻觉的可能性。
在处理查询时,一些更适合使用基于关键字的检索技术(如 BM25),而其他则可能在使用语言模型嵌入的密集检索方法中表现更好。混合检索技术旨在弥补这两种方法的不足。而倒数秩融合(RRF)作为一种排名聚合方法,可以将多个检索模型的排名合并,生成一个统一的排名结果。
RRF 算法原理
RRF 是一种用于组合多个来源排名的聚合方法,特别是在 RAG 系统中应用时,不同的检索模型会生成不同的文档排名,RRF 将这些排名融合为一个统一的结果。

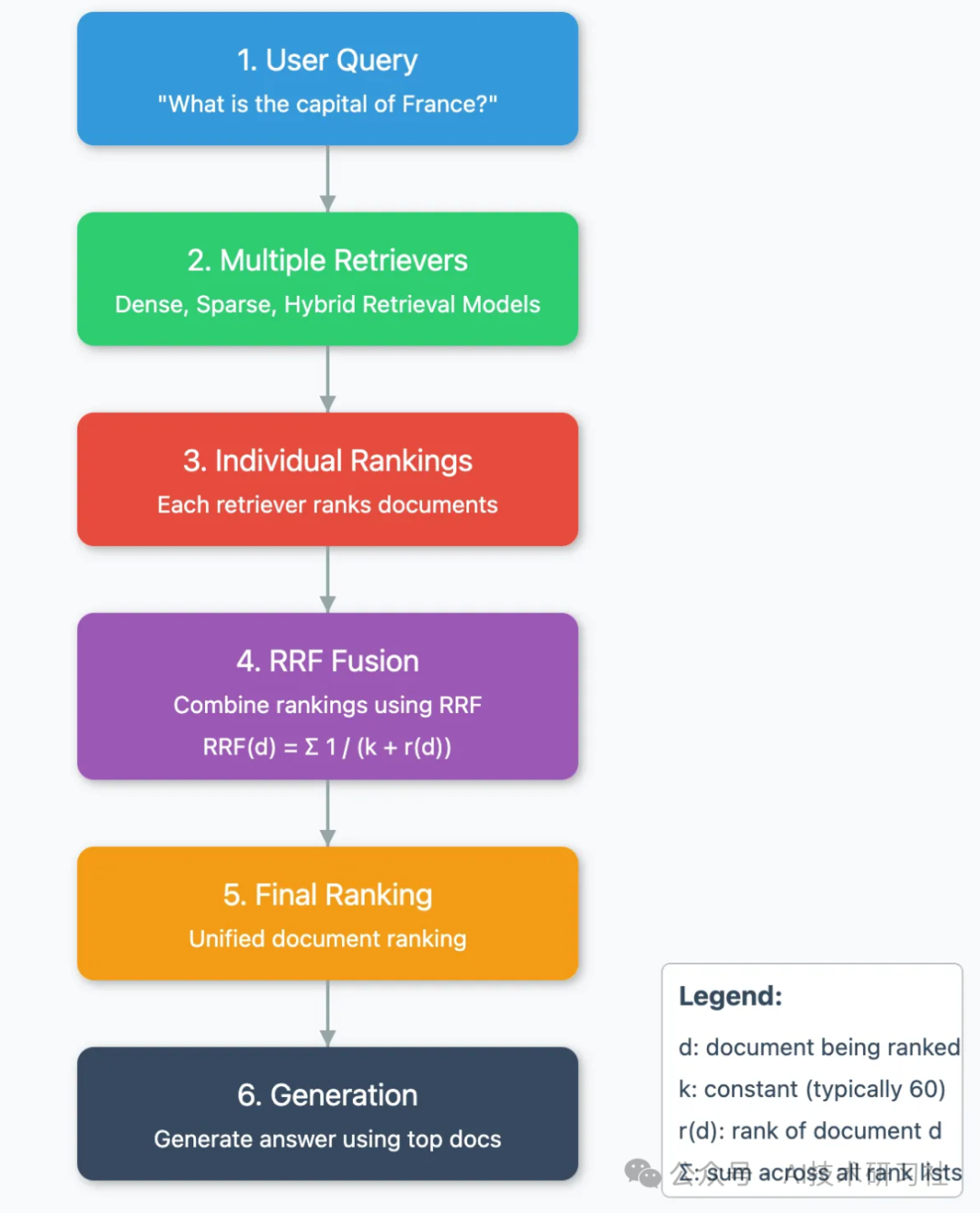
RRF的工作流程
-
用户查询:用户输入一个查询。
-
多重检索器:查询被发送到多个检索器,这些检索器可能使用不同的检索模型(如密集检索、稀疏检索、混合检索)。
-
独立排名:每个检索器对相关文档进行排名。
-
RRF 融合:使用 RRF 公式将所有检索器的排名结果合并。
-
生成最终排名:根据 RRF 分数生成一个统一的文档排名。
-
生成答案:生成模型使用排名最高的文档生成最终答案。

RRF背后的数学直觉
-
倒数排名:RRF 通过 1/(rank + k) 的公式,给排名靠前的文档更多的权重,这确保了在多个检索器中排名靠前的文档在最终排名中被优先考虑。
-
收益递减:随着排名的增加,分数的贡献呈非线性递减。这反映了排名 1 和 2 之间的相关性差异通常比排名 100 和 101 之间的差异更大。
-
排名聚合:通过对所有检索器的倒数秩求和,RRF 能够有效地结合多个来源的证据,使得最终排名更稳健,并且减少了单个检索器的偏见对结果的影响。
-
归一化:常数 k 作为平滑因子,防止任何单个检索器对结果的主导,并有助于更优雅地处理低排名项目中的平局。
k 值的选择
RRF 中常用的 k 值为 60,这一选择背后有几个原因:
-
实证表现:k = 60 在各种数据集和检索任务中表现良好。
-
平衡影响力:这个值在高排名和低排名项目的影响之间提供了良好的平衡。
-
有效的平局:k = 60 有助于在低排名项目中有效打破平局。
-
鲁棒性:该值在不同类型的检索系统和数据分布中表现出很强的鲁棒性。
尽管 k = 60 是常用的选择,但最佳值可能因具体应用和数据特性而异。某些系统可能需要调整这个参数以获得更好的表现。
RRF的应用
RRF 通过融合多个检索模型的排名结果,在 RAG 系统中表现出色。其数学原理确保了生成的文档排名具有稳健性,并且可以根据实际应用需求进行调整。
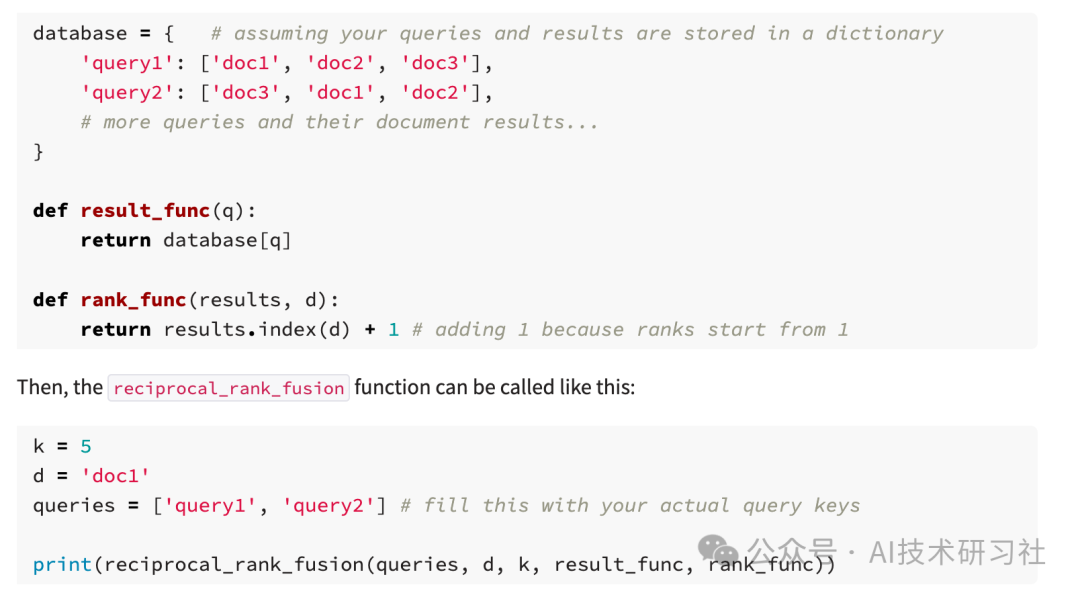
score = 0.0
for q in queries: # loop over queries send to different search engines
if d in result(q):
score += 1.0 / ( k + rank(result(q), d))
return score
# where
# k is a ranking constant
# q is a query in the set of queries
# d is a document in the result set of q
# result(q) is the result set of q
# rank( result(q), d ) is d's rank within the result(q) starting from 1
def reciprocal_rank_fusion(queries, d, k, result_func, rank_func):
def reciprocal_rank_fusion(queries, d, k, result_func, rank_func):
return sum([1.0 / (k + rank_func(result_func(q), d)) if d in result_func(q) else 0 for q in queries])
结论
RRF 是 RAG 系统中一种强大的排名聚合工具,通过有效结合多个检索器的排名结果,它能够生成更加稳健和相关的文档排名。掌握 RRF 的原理和应用能够帮助从业者更好地在他们的系统中实现和优化这一技术。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}