







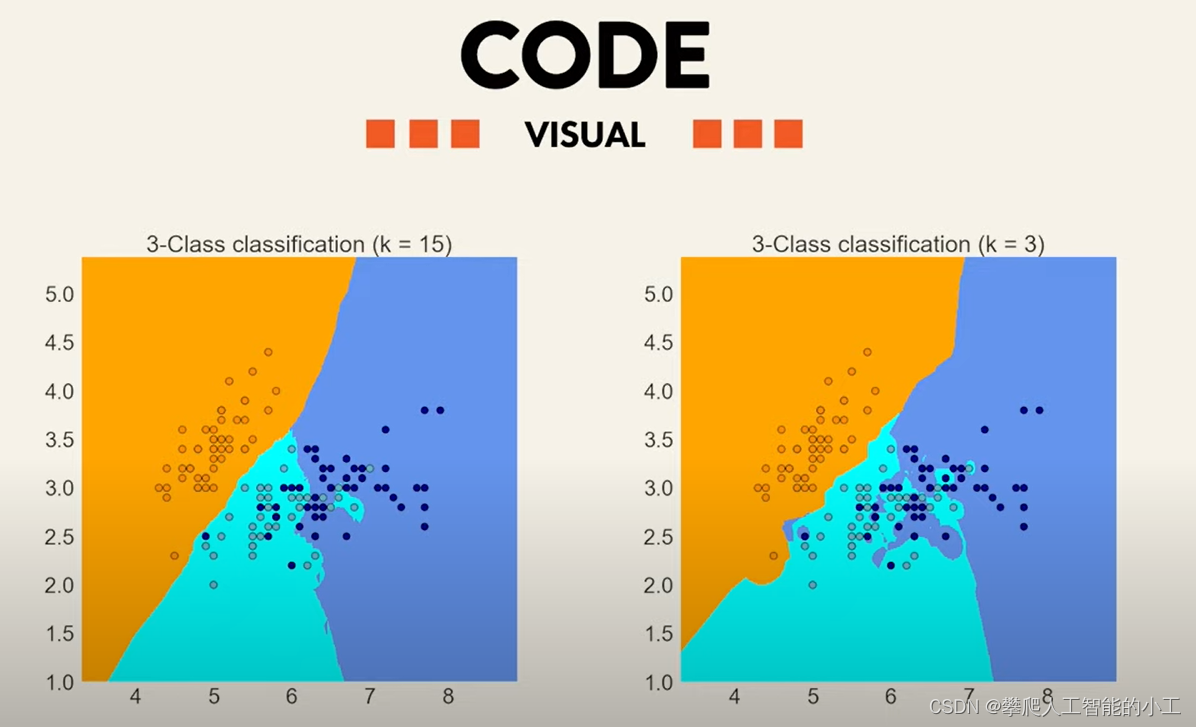
一、KNN是什么?
KNN是基于样本的邻近度进行分类的一种简单的机器学习算法,它的核心就是根据新数据与已有数据之间的距离或相似程度来判断其所属类别。
二、利用KNN进行分类的过程
1.计算测试样本与每个训练样本的距离或相似程度;
2.按照距离或相似程度排序,选出距离或相似程度最近的k个训练样本;
3.统计k个样本中各类别出现的次数,选出出现次数最多的类别作为测试样本所属的类别;
4.输出测试样本的类别。
二、利用KNN进行分类的python代码
# 导入相关包
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载Iris数据集
iris = load_iris()
data = iris['data']
target = iris['target']
# 划分数据集
train_data, test_data, train_target, test_target = train_test_split(data, target, test_size=0.2)
# 参数设置
k = 5 # 定义k值
# 欧几里得距离计算函数
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))
# 分类模型
def KNN(train_data, test_data, train_target, k):
# 存储预测结果
predictions = []
for i in range(len(test_data)):
# 计算测试样本与训练集样本之间的距离并存储
distances = [euclidean_distance(test_data[i], j) for j in train_data]
# 距离排序并确定前k个样本
sorted_distances = np.argsort(distances)[:k]
# 统计前k个样本中各类别出现的次数,并选出出现次数最多的类别
class_counts = np.zeros(max(target)+1)
for j in sorted_distances:
class_counts[train_target[j]] += 1
prediction = np.argmax(class_counts)
# 存储每个测试样本的预测结果
predictions.append(prediction)
return predictions
# 调用KNN函数进行分类
predictions = KNN(train_data, test_data, train_target, k)
# 计算分类精度
accuracy = np.sum(predictions == test_target) / len(test_target)
print('Accuracy:', accuracy)
总结
在以上代码中,euclidean_distance函数为欧几里得距离的计算函数,KNN函数则是实现了KNN算法进行训练和预测。最后输出的是分类的准确率。















 4655
4655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









