










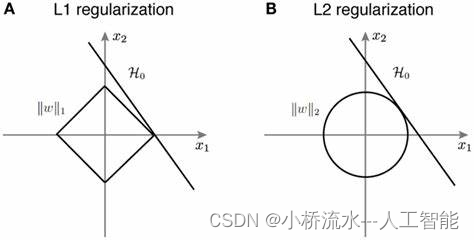
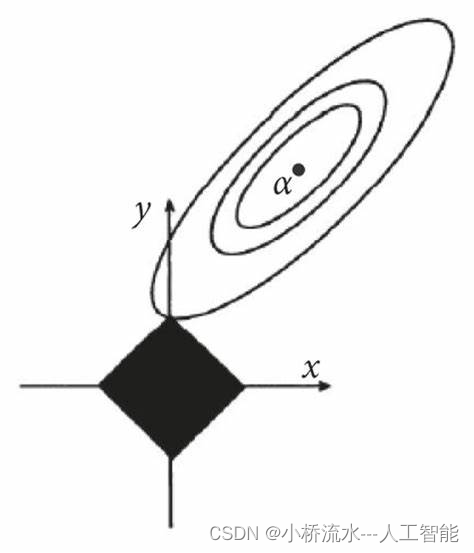
L1正则化具有稀疏性的原因主要是由于它的优化性质和几何解释:
-
L1正则化的优化性质:L1正则化的损失函数包含参数的绝对值之和作为正则化项。在优化过程中,当正则化参数 λ \lambda λ足够大时,优化算法会倾向于将一些参数的值减小到零,因为这样可以最小化整体的损失函数。
而绝对值函数的导数在零点处不连续,这使得优化过程中某些参数很容易变成零,从而产生稀疏性。 -
几何解释:在参数空间中,L1正则化的等值线是由参数的绝对值之和构成的菱形。在优化过程中,模型的参数向量在参数空间中往往会落在菱形的顶点处,这些顶点恰好对应着某些参数为零的情况,因此导致了参数的稀疏性。
因此,由于L1正则化的优化性质和几何解释,它能够促使模型的参数向量在优化过程中趋向于稀疏化,从而实现特征选择和模型简化的效果。
总结
首先,L1正则化的正则化项是权重向量的绝对值之和。在优化过程中,这个正则化项会引导模型尽量将某些权重压缩为零。这是因为最小化L1正则化项(即权重向量的绝对值之和)的过程中,优化算法会倾向于让不太重要的权重趋于零。
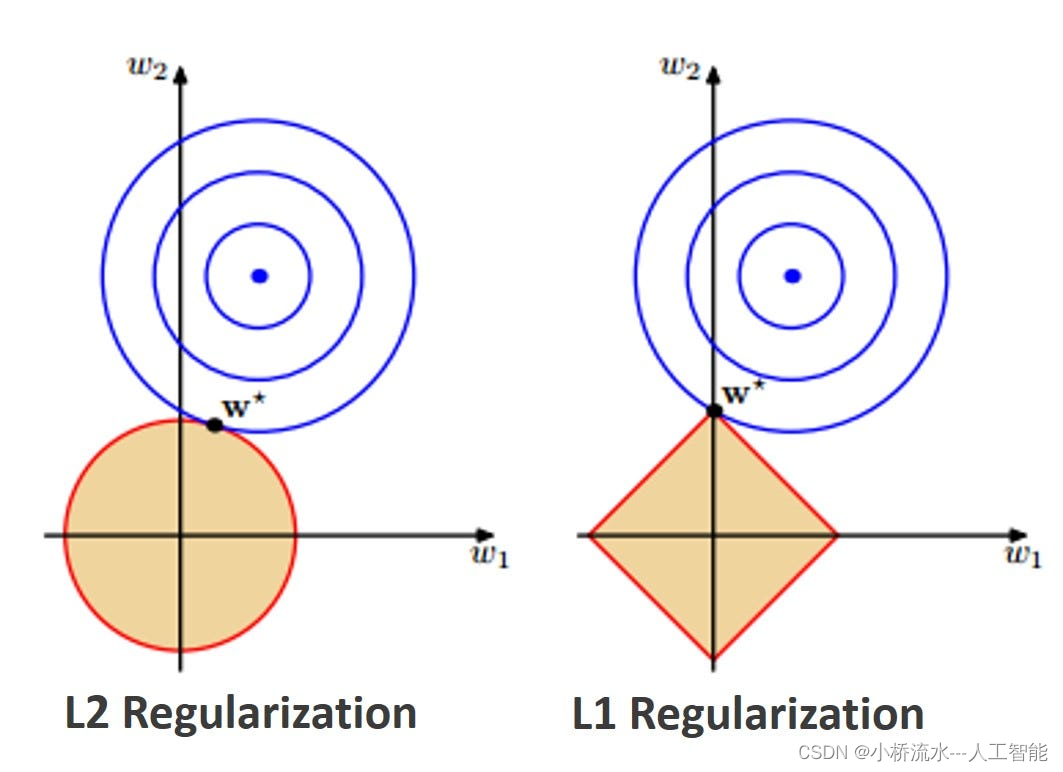
其次,从几何角度来看,L1正则化在优化过程中用一个菱形去逼近目标。这种逼近方式使得L1正则化更容易在坐标轴和目标相交,因此更容易得到稀疏解,即权重向量的某些分量可能为零。

















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









