







文章目录
1. 前言
**情感对话系统的**成功取决于对情感的充分理解和适当表达。 在现实世界的对话中,我们首先从多种来源的信息(多模态信息)中感知情绪,包括对话历史的情感,面部表情和说话人的性格,然后根据我们的个性表达适当的情绪, 但是在情感交流领域,这些多模态信息没有得到充分利用。
为了解决这个问题,我们提出了一种**基于异质图的情感对话生成模型**。 具体来说,我们设计了一种基于异质图的编码器,以利用图神经网络来表示对话内容(即对话历史情感,面部表情和**说话人的个性**),然后进行预测,反馈适合的情绪。
然后,我们采用**情绪个性识别解码器**,生成不仅与对话上下文相关的响应而且还生成具有适当情感的响应。 实验结果表明,我们的模型可以有效地从多源知识中感知情绪并产生令人满意的响应,这大大优于以前的最新模型。
2. 模型结构
模型任务是根据一段序列, 给出对话:
模型输入一个5元组 < U, F, E, S, sN+1 > 包括 U = {u1,···,uN} 对话历史,直到第N轮,F = {f1,···,fN}是面部表情序列,E = {e1,···,eN} 情感序列 ,S = {s1,···,sN} 说话者序列,sN + 1是下一个响应的说话者,此任务是生成目标响应Y = {y1,···,yJ}
模型总体结构如图:

如图2所示,体系结构包含两个组件:
- 基于异质图的编码器
- 情绪个性识别解码器
其中的编码器旨在了解内容并通过具有多源信息的会话上下文感知情感, 解码器用于产生连贯的情感的响应。
具体来说,我们的编码器主要由四个部分组成:
(1)图构造,构造具有多源知识的异质图;
(2)图初始化,初始化不同种类的节点;
(3)异质图编码,基于构建的图, 感知情感并代表对话上下文;
(4)情绪预测器,通过图形增强的表示形式预测适当的情绪,以进行反馈。
我们的解码器将图形增强的表示,预测的情绪以及当前说话者的个性作为输入,以生成适当的情绪响应
2.1 Heterogeneous Graph-Based Encoder
2.1.1 Graph Construction

上图所示,我们构造了异质图G =(V,E),
其中V表示节点的集合,而E表示边的E表示节点之间的关系。
具体来说,我们考虑四种类型的异质节点,其中每个节点都是对话历史记录的话语,面部表情,情感类别,说话人的一个
然后,我们在其中建立边缘E , 包括下面7种类型
- 在同一说话者相邻说话者的两个话语之间 (左侧深蓝线)
- 在话语和相应的面部表情之间
- 在话语和相应的情感之间
- 在话语及其对应的说话人之间
- 在两个相邻或来自同一说话人的面部表情之间
- 在面部表情及其对应的说话者之间
- 在面部表情和对应的情绪之间
2.1.2 Graph Initialization
结构下如图

以一次N轮历史对话为例,描述如何初始化四种类型的节点
文本结点:
LSTM (hidden) + mulit-head attention + position encoding

面部特征结点:
先提取特征, 然后映射到相同维度

情感和说话人结点:
我们维护了可训练的参数矩阵EMB1和EMB2,它们是随机初始化的并且可以学习。 EMB1∈ 7×de存储七个情感标签特征,EMB2∈ Z×ds存储Z个说话者个性的特征,其中de和ds分别是情感节点表示和说话者节点表示的维度。
因此,从中检索出情感节点和说话者节点的初始化特征,分别表示为Xe和Xs。
(相当于训练了一个embedding 矩阵)
2.1.3 Heterogeneous Graph Encoding
这里是借鉴了HGNN网络结构(conventional homogeneous graph neural network )(Kipf and Welling 2017)
l层 的 每个结点的隐层表示为Hl
HGNN会考虑各种类型的节点,并将它们与它们各自的可训练矩阵映射到一个隐层公共空间。

A是邻接 矩阵, 实现encoder 只能看到前面的信息
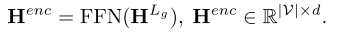
经过前馈层得到 encoder
PS: 不同模态的信息编码到相同维度 , 用全连接是否有效?
2.1.4 Emotion Predictor
在完全感知到来自多个不同来源的情感之后,编码器将表示形式存储在最后一层中。 我们通过Maxpooling将表示隐层H转换为固定大小的向量, 用solfmax 来判断情感
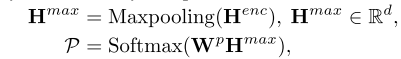
2.2 Emotion-Personality-Aware Decoder
我们的目标是将多源知识与异质图神经网络相结合以实现情感感知
因此我们使用简单且通用的解码器,即基于自注意的解码器(Vaswani等,2017)来生成响应词。如图所示。

这个的话其实就是 Transform的 decoder结构, 流程如下
- 对输入的前一个单词做 selff -attention

- 然后 和encoder的输入做 encoder-decoder attention, 然后过前馈神经网络 分类
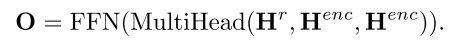
- 为了加入 说话人的情绪和性格, 设计一个门机制, 来控制 情绪和性格的加入

Eg表示情绪, Sg表示说话人性格, EMB1 表示情绪的变换矩阵, EMB2表示个性的变换矩阵
- 计算单词的概率就用solfmax来做

3. 实验
3.1 损失函数
模型的损失定义如下
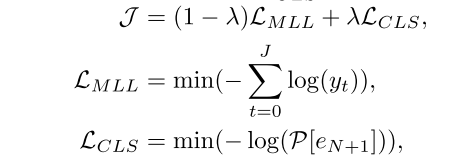
回应生成损失Lmml和情感分类损失Lcls,
3.2 模型结果
达到了sota 水平

两个测试集上生成的回应的结果。三种设置意味着使用了不同数量的模态
- 仅用 对话历史的“一个来源”,
- 用 对话历史及其 情感流的“两个来源”,
- 用 对话历史,情感流,面部表情和说话人个性的“四个来源” 。
W-avg。表示七个情感类别的加权平均F1得分
其中4模态 效果最好
4. 总结
4.1 模型贡献
- 提出了一种新颖的基于异质图的框架,用于感知来自不同类型的多源知识的情感,以产生连贯的情感响应。 据我们所知,我们是第一个引入异质图神经网络进行情感对话的人
- 在多个数据集 达到sota 效果















 5992
5992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









