









收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
随着社会老龄化程度的加深,以及慢性病、神经系统疾病等患者的增多,康复医学的需求越来越大。传统的康复训练方法往往依赖于物理治疗师的指导,但物理治疗师的数量有限,且训练过程需要耗费大量时间和人力。因此,利用技术手段辅助康复训练成为了一个迫切的需求。
近年来,深度学习、机器视觉等技术的快速发展,使得人体姿态识别在准确度和实时性方面取得了显著进步。这为基于人体姿态识别的康复训练动作矫正系统的实现提供了可能。每个人的身体状况、疾病类型、康复目标等都是不同的,因此需要个性化的康复训练方案。传统的康复训练方法通常采用统一的训练方案,缺乏对个体差异的考虑,难以满足个性化康复的需求。而基于人体姿态识别的康复训练动作矫正系统可以通过实时监测患者的动作,并根据患者的具体情况提供个性化的反馈和建议,从而更好地满足个性化康复的需求。
例如,对于某些神经系统疾病患者,康复训练的重点可能在于改善平衡能力、协调性和肌肉力量等方面。基于人体姿态识别的系统可以通过实时监测患者的动作,分析其姿态和运动模式,并根据分析结果提供针对性的训练建议和反馈,帮助患者逐步纠正错误的动作和姿势,提高康复训练的效果。
此外,基于人体姿态识别的系统还可以根据患者的康复进展和目标,逐步调整训练方案,以适应患者的康复需求。这有助于实现个性化的康复训练,提高康复效果和生活质量。
一、项目介绍
基于人体姿态识别的康复训练动作矫正系统是一个通过机器视觉和深度学习技术来监测和纠正人体姿态的自动化系统。该系统的核心在于对人体姿态的识别和判断,通过实时捕捉和分析患者的动作,判断其是否存在异常或需要改进的地方,并给出相应的反馈和建议。
该系统的应用范围广泛,可以用于康复医学、运动训练、健身等领域。在康复医学中,该系统可以帮助患者进行针对性的康复训练,提高康复效果和生活质量。在运动训练中,该系统可以用于指导运动员进行正确的动作训练,提高运动表现和减少运动损伤。在健身领域,该系统可以用于指导健身者进行正确的运动姿势,避免因错误的姿势导致的运动损伤和不适。
基于人体姿态识别的康复训练动作矫正系统的实现需要结合深度学习、机器视觉、传感器技术等多个领域的知识。在技术上,该系统需要采用先进的人体姿态识别算法,实现快速、准确的人体姿态识别和判断。同时,该系统还需要结合传感器技术,实时捕捉患者的动作数据,并进行分析和处理。
基于人体姿态识别的康复训练动作矫正系统的应用价值在于提高康复训练的效果和生活质量,减少运动损伤和不适。同时,该系统的应用也有助于提高康复医学和运动训练的科学性和有效性,推动相关领域的技术进步和发展。
二、功能介绍
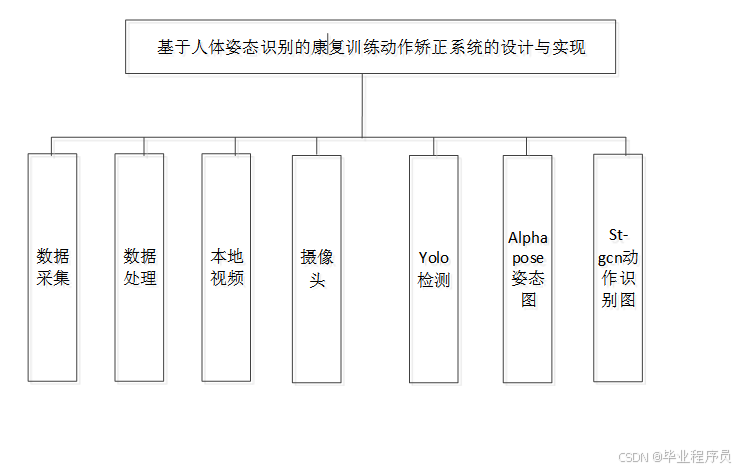
根据需求分析可知,康复训练动作矫正系统的设计主要分为四个模块:数据采集、数据处理、动作识别和矫正。 本系统的框架结构图如图6-1所示。
三、核心代码
部分代码:
# 提供CMD接口
parser = argparse.ArgumentParser(
description='''Lightweight human pose estimation python demo.
This is just for quick results preview.
Please, consider c++ demo for the best performance.''')
parser.add_argument('--checkpoint-path', type=str, help='path to the checkpoint')
parser.add_argument('--height-size', type=int, default=256, help='network input layer height size')
parser.add_argument('--video', type=str, default='', help='path to video file or camera id')
parser.add_argument('--images', nargs='+', default='', help='path to input image(s)')
parser.add_argument('--cpu', action='store_true', help='run network inference on cpu')
parser.add_argument('--track', type=int, default=1, help='track pose id in video')
parser.add_argument('--smooth', type=int, default=1, help='smooth pose keypoints')
args = parser.parse_args()
# 读取图片
class ImageReader(object):
def __init__(self, file_names):
self.file_names = file_names
self.max_idx = len(file_names)
def __iter__(self):
self.idx = 0
return self
def __next__(self):
if self.idx == self.max_idx:
raise StopIteration
img = cv2.imread(self.file_names[self.idx], cv2.IMREAD_COLOR)
if img.size == 0:
raise IOError('Image {} cannot be read'.format(self.file_names[self.idx]))
self.idx = self.idx + 1
return img
# 读取视频
class VideoReader(object):
def __init__(self, file_name):
self.file_name = file_name
try: # OpenCV needs int to read from webcam
self.file_name = int(file_name)
except ValueError:
pass
def __iter__(self):
self.cap = cv2.VideoCapture(self.file_name)
if not self.cap.isOpened():
raise IOError('Video {} cannot be opened'.format(self.file_name))
return self
def __next__(self):
was_read, img = self.cap.read()
if not was_read:
raise StopIteration
return img
# 轻量化预测
def infer_fast(net, img, net_input_height_size, stride, upsample_ratio, cpu,
pad_value=(0, 0, 0), img_mean=np.array([128, 128, 128], np.float32), img_scale=np.float32(1/256)):
height, width, _ = img.shape
scale = net_input_height_size / height
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
scaled_img = normalize(scaled_img, img_mean, img_scale)
min_dims = [net_input_height_size, max(scaled_img.shape[1], net_input_height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = torch.from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float()
if not cpu:
tensor_img = tensor_img.cuda()
stages_output = net(tensor_img)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
return heatmaps, pafs, scale, pad
# 运行的Demo
def run_demo(net, image_provider, height_size, cpu, track, smooth):
net = net.eval()
if not cpu:
net = net.cuda()
stride = 8
upsample_ratio = 4
num_keypoints = Pose.num_kpts
previous_poses = []
delay = 1
for img in image_provider:
orig_img = img.copy()
heatmaps, pafs, scale, pad = infer_fast(net, img, height_size, stride, upsample_ratio, cpu)
total_keypoints_num = 0
all_keypoints_by_type = []
for kpt_idx in range(num_keypoints): # 19th for bg
total_keypoints_num += extract_keypoints(heatmaps[:, :, kpt_idx], all_keypoints_by_type, total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, pafs)
for kpt_id in range(all_keypoints.shape[0]):
all_keypoints[kpt_id, 0] = (all_keypoints[kpt_id, 0] * stride / upsample_ratio - pad[1]) / scale
all_keypoints[kpt_id, 1] = (all_keypoints[kpt_id, 1] * stride / upsample_ratio - pad[0]) / scale
current_poses = []
for n in range(len(pose_entries)):
if len(pose_entries[n]) == 0:
continue
pose_keypoints = np.ones((num_keypoints, 2), dtype=np.int32) * -1
for kpt_id in range(num_keypoints):
if pose_entries[n][kpt_id] != -1.0: # keypoint was found
pose_keypoints[kpt_id, 0] = int(all_keypoints[int(pose_entries[n][kpt_id]), 0])
pose_keypoints[kpt_id, 1] = int(all_keypoints[int(pose_entries[n][kpt_id]), 1])
pose = Pose(pose_keypoints, pose_entries[n][18])
current_poses.append(pose)
if track:
track_poses(previous_poses, current_poses, smooth=smooth)
previous_poses = current_poses
for pose in current_poses:
pose.draw(img)
img = cv2.addWeighted(orig_img, 0.6, img, 0.4, 0)
for pose in current_poses:
cv2.rectangle(img, (pose.bbox[0], pose.bbox[1]),
(pose.bbox[0] + pose.bbox[2], pose.bbox[1] + pose.bbox[3]), (0, 255, 0))
if track:
cv2.putText(img, 'id: {}'.format(pose.id), (pose.bbox[0], pose.bbox[1] - 16),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 255))
cv2.imshow('Lightweight Human Pose Estimation Python Demo', img)
key = cv2.waitKey(delay)
if key == 27: # esc
return
elif key == 112: # 'p'
if delay == 1:
delay = 0
else:
delay = 1
# 加载OPENPOSE模型
# For static images:
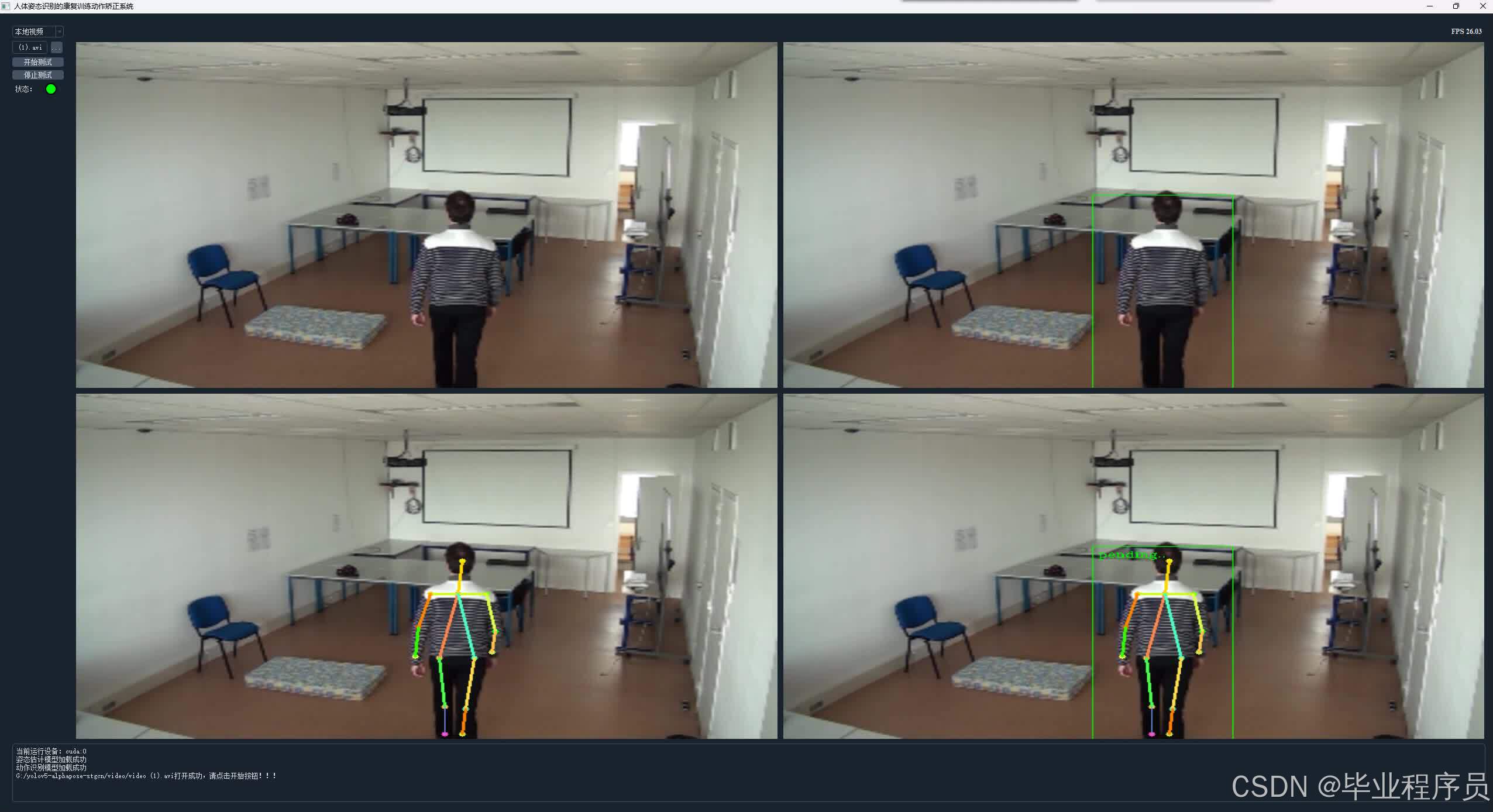
四、效果图
五 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻


















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











