







 在Seaborn的heatmap中,启用`annot=True`可在方格上显示数据。若要展示自定义内容,如添加标准差信息,可将结果与标准差合并为字符串并设置`fmt='s'`防止数值格式错误。通过这种方式,可以在原始数据基础上展示额外信息。
在Seaborn的heatmap中,启用`annot=True`可在方格上显示数据。若要展示自定义内容,如添加标准差信息,可将结果与标准差合并为字符串并设置`fmt='s'`防止数值格式错误。通过这种方式,可以在原始数据基础上展示额外信息。
一般在seaborn中使用heatmap,想在方格上显示结果,需要将annot设置为True。
sns.heatmap(result, cmap='Blues_r', annot=True, annot_kws={"fontsize":16}, linewidths=1, vmax=100, vmin=0) 这样就可以在heatmap上显示出result的内容,如下图所示。
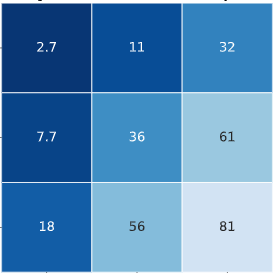
如果想在格子里放自己定义的内容,或者在原数据的内容上加点东西,可以再自行定义。
例如:将result和另一个维度相同的result_std合并成一个str,原数据保持,后者扩在括号里,并进行显示,可以这样定义,
labels = (np.asarray(["{:.1f} ({:.2f})".format(string, value)
for string, value in zip(result.flatten(),
result_std.flatten())])
).reshape(3, 3)并且设置
annot=labels 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









