







读书笔记: NonLinear System Identification, Chapter 10
《Nonlinear System Identification From Classical Approaches to Neural Networks, Fuzzy Models, and Gaussian Processes, Second Edition》
Chapter 10 : 线性、多项式、查找表模型
10.1 线性模型
y ^ = ∑ i = 0 p w i u i with u 0 = 1 \hat y = \sum^p_{i=0}w_iu_i \quad \text{with} \quad u_0=1 y^=i=0∑pwiuiwithu0=1
特性:
- 内插是线性
- 外插是线性
- 没有局部特性
- 精度低
- 光滑度高
- 对噪音不敏感
- 参数优化速度快
- 结构优化可使用linear subset selection technique例如OLS
- 可在线自适应(使用RLS)
- Training速度快
- Evaluation速度快
- 可解释
- 可处理约束,使用二次规划可处理输出约束和参数约束
- 以惩罚形式附加先验知识,如岭回归
- 实用性非常高
10.2 多项式模型
y
^
=
∑
i
=
0
p
θ
i
x
i
with
x
0
=
1
\hat y = \sum^p_{i=0}\theta_ix_i \quad \text{with} \quad x_0=1
y^=i=0∑pθixiwithx0=1
其中
x
i
x_i
xi是
u
i
u_i
ui的各阶次幂的乘积,例如,三输入二次多项式模型:
y
^
=
θ
0
+
θ
1
u
1
+
θ
2
u
2
+
θ
3
u
3
+
θ
4
u
1
2
+
θ
5
u
1
u
2
+
θ
6
u
1
u
3
+
θ
7
u
2
2
+
θ
8
u
2
u
3
+
θ
9
u
3
2
\hat{y}=\theta _0+\theta _1u_1+\theta _2u_2+\theta _3u_3 +\theta _4u_{1}^{2}+\theta _5u_1u_2+\theta _6u_1u_3+\theta _7u_{2}^{2}+\theta _8u_2u_3+\theta _9u_{3}^{2}
y^=θ0+θ1u1+θ2u2+θ3u3+θ4u12+θ5u1u2+θ6u1u3+θ7u22+θ8u2u3+θ9u32
10.2.1正则化多项式
添加 λ \lambda λ惩罚,可减小各个参数值,增项鲁棒性
直接加 λ \lambda λ正则化会在offset或bias上加惩罚,但是这是不合理的。一般而言有两个方法:
- 不使用LS估计bias,直接将 θ 0 \theta_0 θ0设为输出的均值
- 在惩罚中去除bias对应的项
θ ^ = ( X T X + λ I ~ ) − 1 X T y \hat{\theta}=(X^TX+\lambda\tilde I)^{-1}X^Ty θ^=(XTX+λI~)−1XTy
其中 I ~ = d i a g ( 0 , 1 , 1 , . . . ) \tilde{I}=\mathrm{diag}\left( 0,1,1,... \right) I~=diag(0,1,1,...)将bias对应的惩罚项给0
10.2.2 正交多项式
在制定区间内可另多项式正交,及满足不同阶次的多项式在
[
−
1
,
1
]
[-1, 1]
[−1,1]之间有
∫
−
1
1
f
(
u
)
g
(
u
)
d
u
=
0
\int_{-1}^1{f\left( u \right) g\left( u \right) du=0}
∫−11f(u)g(u)du=0
如果是正交归一,还应该有
∫
−
1
1
f
(
u
)
f
(
u
)
d
u
=
1
\int_{-1}^1{f\left( u \right) f\left( u \right) du=1}
∫−11f(u)f(u)du=1
满足以上条件的多项式称为勒让德多项式。
L
0
(
u
)
=
1
L
1
(
u
)
=
u
L
2
(
u
)
=
1
2
(
3
u
2
−
1
)
L
3
(
u
)
=
1
2
(
5
u
3
−
3
u
)
L
4
(
u
)
=
1
8
(
35
u
4
−
30
u
2
+
3
)
L
5
(
u
)
=
1
8
(
63
u
5
−
70
u
3
+
15
u
)
\begin{aligned} L_0\left( u \right) &=1\\ L_1\left( u \right) &=u\\ L_2\left( u \right) &=\frac{1}{2}\left( 3u^2-1 \right)\\ L_3\left( u \right) &=\frac{1}{2}\left( 5u^3-3u \right)\\ L_4\left( u \right) &=\frac{1}{8}\left( 35u^4-30u^2+3 \right)\\ L_5\left( u \right) &=\frac{1}{8}\left( 63u^5-70u^3+15u \right)\\ \end{aligned}
L0(u)L1(u)L2(u)L3(u)L4(u)L5(u)=1=u=21(3u2−1)=21(5u3−3u)=81(35u4−30u2+3)=81(63u5−70u3+15u)
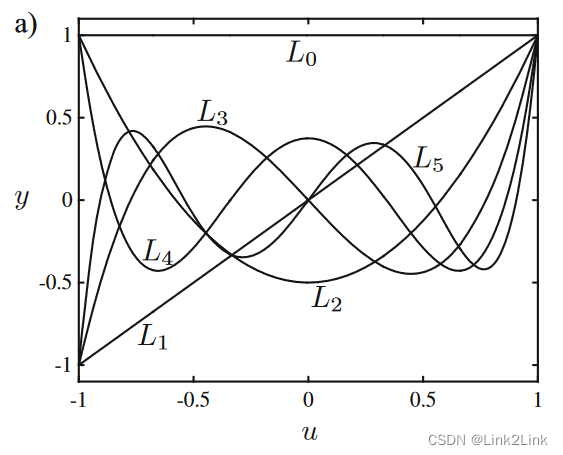
正交性导致的结果就是在LS时各个系数是完全独立的,既增加或减少阶数不会影响参数的优化结果。
但以上结果只对
[
−
1
,
1
]
[-1, 1]
[−1,1]区间适用,因此在使用时需要归一化。
10.2.3 多项式模型的总结
- 高次多项式的内插不稳定(龙格现象),正则化可缓解这个问题
- 多项式的外推会趋向无穷
- 不存在局部特性,只有全局特性
- 精度有限,因为高阶多项式不实用
- 光惯性差(因为龙格现象)
- 对噪音敏感度低因为所有训练数据都对参数有贡献,但是训练数据数据中如果局部噪音很大,则会显著影像全局行为
- 参数优化较快
- 结构优化可以使用线性子集选择方法如OLS
- 可以在线自适应,使用RLS
- 训练速度快
- 评估速度中等
- 维数灾难
- 不可解释
- 使用二次规划可以处理约束
- 无法处理先验信息
- 使用频率较高
10.3 查找表模型
10.3.1 一维查找表

y
^
=
w
l
(
c
r
−
u
)
+
w
r
(
u
−
c
l
)
c
r
−
c
l
\hat{y}=\frac{w_l(c_r-u)+w_r(u-c_l)}{c_{r}-c_{l}}
y^=cr−clwl(cr−u)+wr(u−cl)
一维查找表可写成如下标准形式
y
^
=
∑
i
=
1
M
w
i
Φ
i
(
u
,
c
)
\hat{y}=\sum_{i=1}^M{w_i\Phi _i\left( u,c \right)}
y^=i=1∑MwiΦi(u,c)
这是一个M点的查找表
Φ
i
(
u
,
c
)
=
{
(
u
−
c
i
−
1
)
/
(
c
i
−
c
i
−
1
)
f
o
r
c
i
−
1
≤
u
≤
c
i
(
u
−
c
i
+
1
)
/
(
c
i
−
c
i
+
1
)
f
o
r
c
i
<
u
≤
c
i
+
1
0
o
t
h
e
r
w
i
s
e
\Phi _i\left( u,c \right) =\begin{cases} \left( u-c_{i-1} \right) /\left( c_i-c_{i-1} \right)\quad \mathrm{for}\quad c_{i-1}\le u\le c_i\\ \left( u-c_{i+1} \right) /\left( c_i-c_{i+1} \right)\quad \mathrm{for}\quad c_i<u\le c_{i+1}\\ 0 \quad \mathrm{otherwise}\\ \end{cases}
Φi(u,c)=⎩
⎨
⎧(u−ci−1)/(ci−ci−1)forci−1≤u≤ci(u−ci+1)/(ci−ci+1)forci<u≤ci+10otherwise
这个最简单的一维查找表可以理解为线性差值,或者一个简单的Fuzzy系统。
10.3.2 二维查找表
二维查找表使用基于栅格的方法实现,栅格法可以推广到更高维度,但是会产生维数灾难。使用矩形法代替栅格划分可以缓解维数灾难,能够处理4到5个输入。
对二维查找表,有
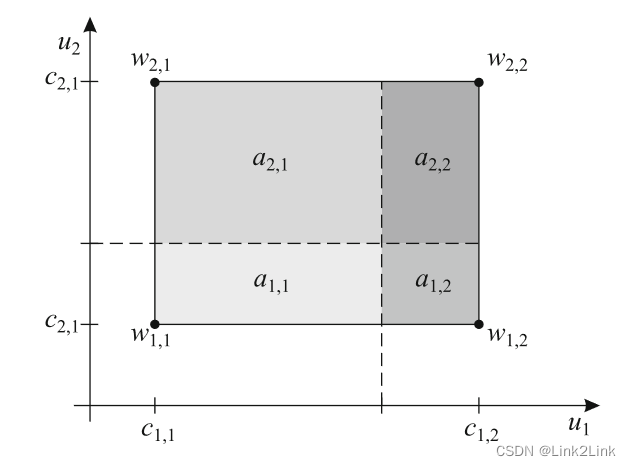
y
^
=
w
1
,
1
a
2
,
2
+
w
1
,
2
a
2
,
1
+
w
2
,
1
a
1
,
2
+
w
2
,
2
a
1
,
1
a
1
,
1
+
a
1
,
2
+
a
2
,
1
+
a
2
,
2
\hat{y}=\frac{w_{1,1}a_{2,2}+w_{1,2}a_{2,1}+w_{2,1}a_{1,2}+w_{2,2}a_{1,1}}{a_{1,1}+a_{1,2}+a_{2,1}+a_{2,2}}
y^=a1,1+a1,2+a2,1+a2,2w1,1a2,2+w1,2a2,1+w2,1a1,2+w2,2a1,1
其中
a
i
,
j
a_{i,j}
ai,j是对应的面积,如此形成的差值叫做双线性插值或面积插值。
其等价与一个四参数的二次插值
y
^
=
θ
0
+
θ
1
u
1
+
θ
2
u
2
+
θ
3
u
1
u
2
\hat y=\theta_0+\theta_1u_1+\theta_2u_2 + \theta_3u_1u_2
y^=θ0+θ1u1+θ2u2+θ3u1u2
10.3.7 查找表特性
- 内插分段线性
- 没有外插
- 强局部性
- 精度中等
- 光滑性很低
- 对噪音敏感
- 参数优化速度快 (LS)
- 结构优化难以实现
- 可以在线自适应(RLS)
- 训练速度快
- 评估速度快
- 解释性差
- 容易处理约束
- 用模糊方法处理先验信息
- 低维情况下非常常用
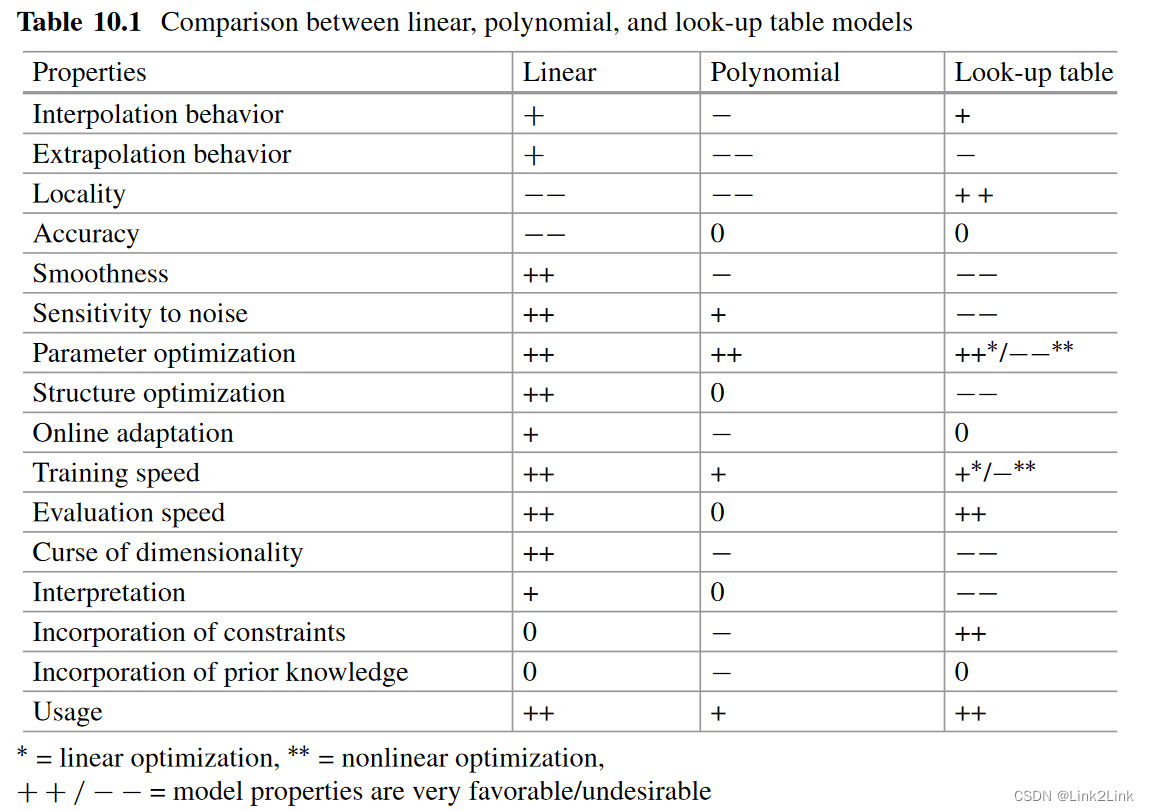
10.4 总结















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









