








论文地址:https://arxiv.org/pdf/2002.03370.pdf
代码地址:暂未公布
摘要
针对目前最新的深度学习图像压缩所遭遇的计算复杂性,本文提出了一个称为高效深度图像压缩(Efficient Deep Image Compression, EDIC)的统一框架,该框架基于三个新的技术:通道注意力模型,高斯混合模型以及解码端增强模型。整个编解码框架基于Balle的超先验图像压缩模型,通过利用通道注意力机制获取隐藏表示的通道之间的关系来提高编码效率;在熵编码中引入高斯混合模型提高了比特率估计的准确性;解码端增强模块可以进一步增强图像压缩的表现。此外,EDIC框架还可以配合DVC(Deep Video Compression,Guo Lu发表于CVPR2019的文章)框架来提高视频压缩的表现。EDIC在提升图像编码变现的同时也稍稍增加了计算复杂性。实验证明,EDIC方法超越了现有最新的方法,同时也提升了DVC的性能。
模型:EDIC
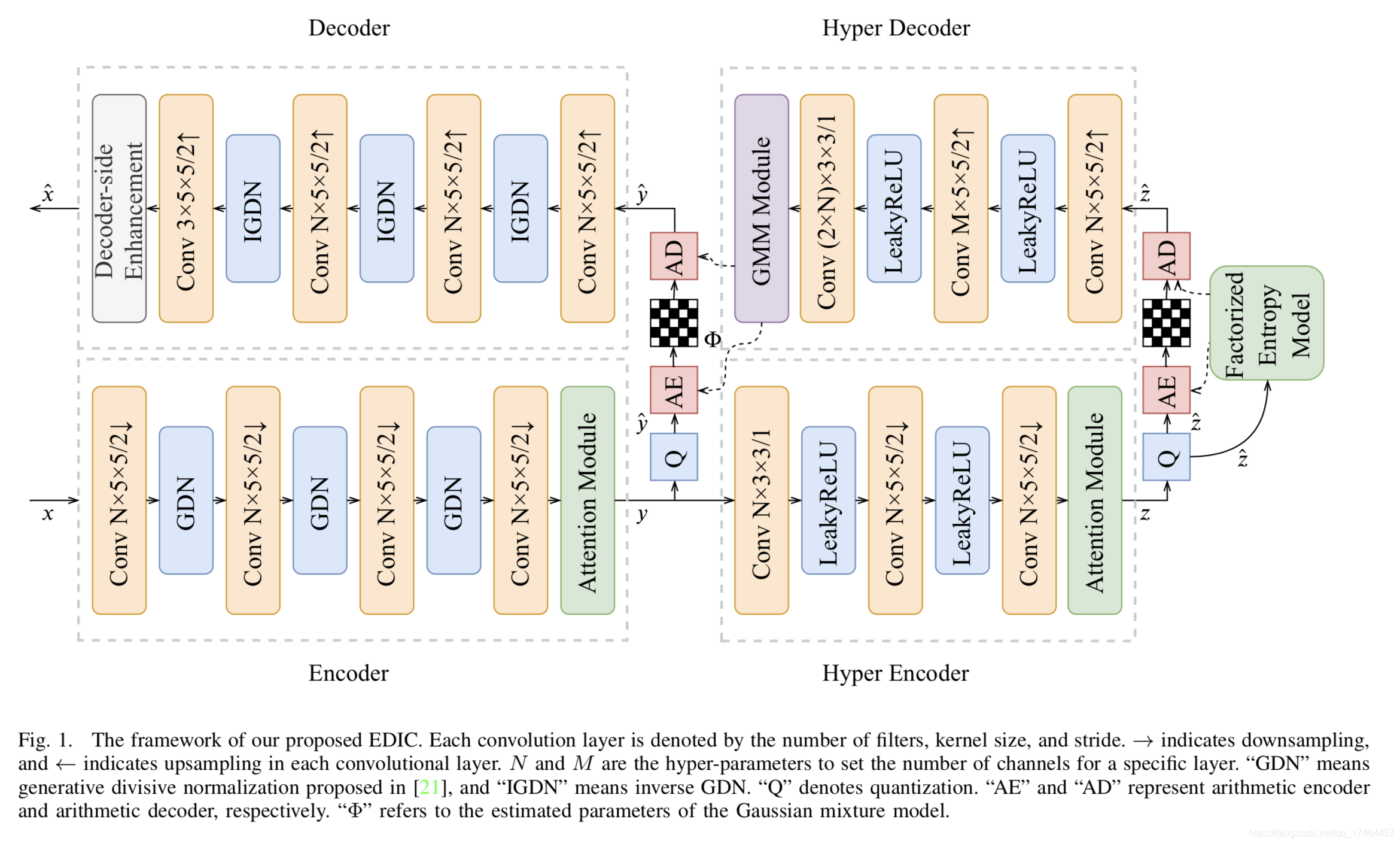
整个模型的基本框架是基于Balle的模型改进的,主要改进内容:
1. 引入通道注意力机制进一步去除信息冗余;
2. 相较于Balle的单高斯模型压缩能力的限制,高斯混合模型可以进一步提升压缩性能;
3. 加入增强模块可以提升重构图像的质量;
其EDIC框架图如下图所示:
整个模型的优化目标为
![]()
其中, 为失真损失,
与
为熵损失。
通道注意力方法
Balle的自回归先验模型就可以获取隐藏表示的空间关系进而提升了压缩性能,与此同时,一些使用空间注意力机制(如non-local blocks)的图像压缩方法也是旨在减少空间冗余。基于这些现有方法的启发,作者提出了一个轻量型的通道注意力方案如下图所示。
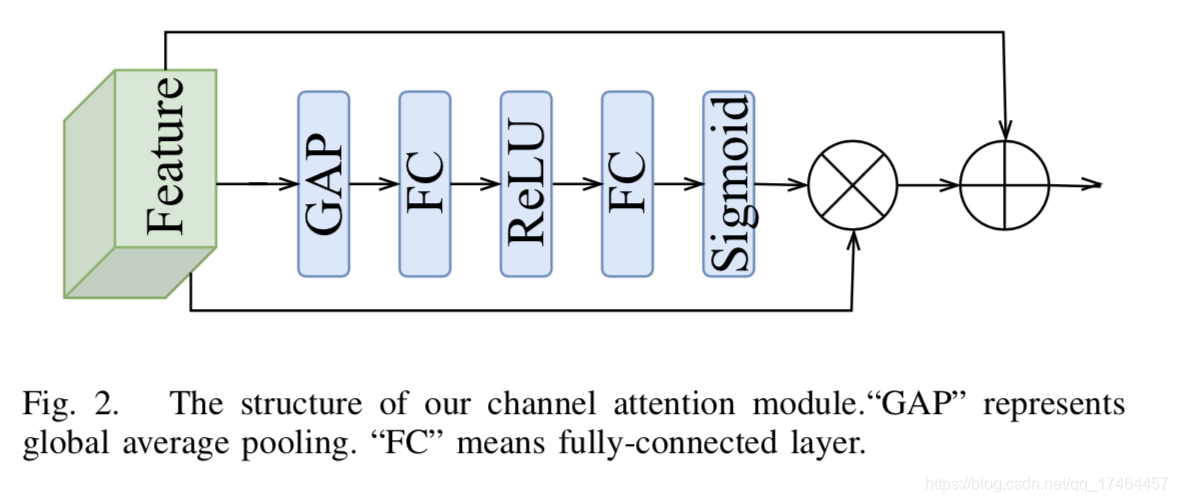
通过非线性变换等操作获取特征图在通道之间的关系,进而对特征图进行加权。
高斯混合模型
在Balle等提出的编解码模型中作为熵估计的超先验编解码模块,其作用就是用于估计隐层特征的高斯分布mu和sigma。虽然相较于之前的基于深度学习的图像压缩方法,基于单个高斯的熵模型以及达到了非常好的效果,但是单个高斯模型的能力仍旧有限,特别是对于一些复杂的图像内容,所以作者使用高斯混合模型来进一步提升图像压缩的效率。具体的,对于隐层特征y_hat的分布估计由下述公式表示,
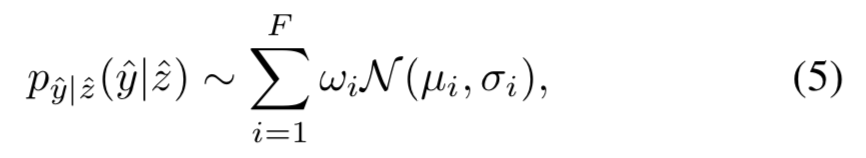
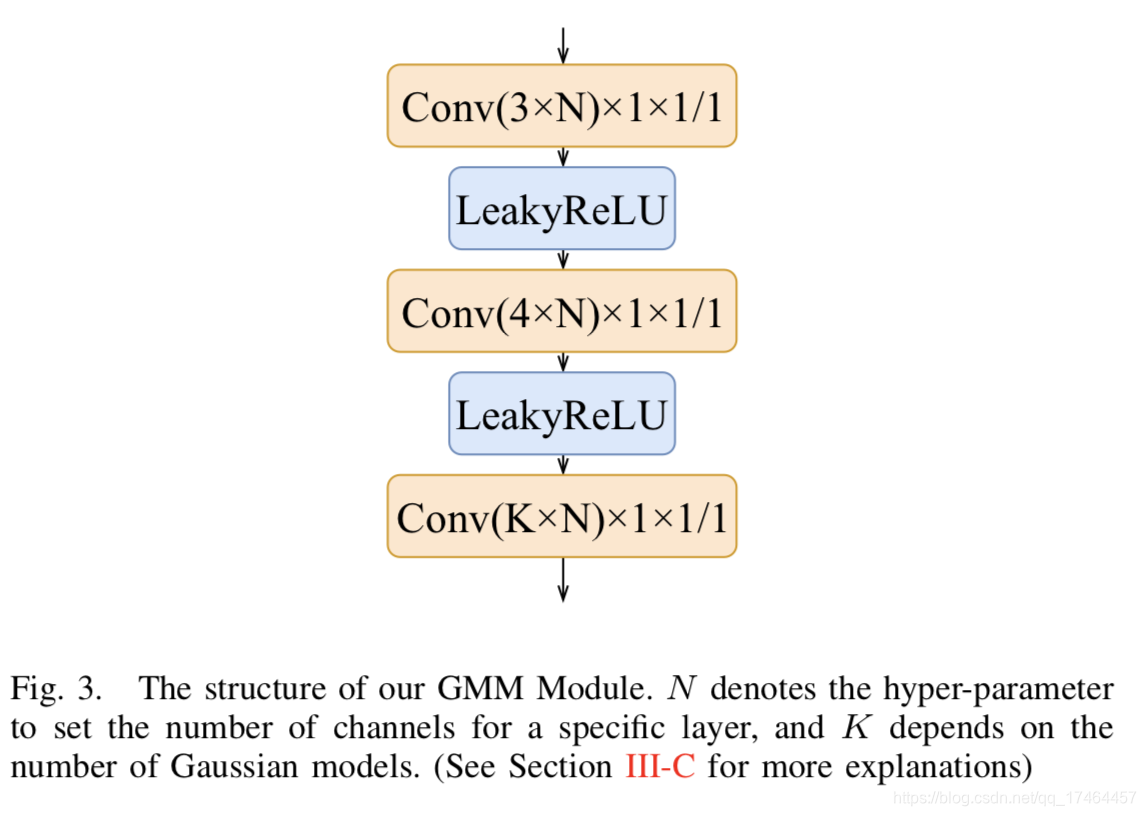
其中wi是不同高斯模型的权重,F是高斯模型的数量,实验中F=2。高斯混合模型的结构如下图所示。
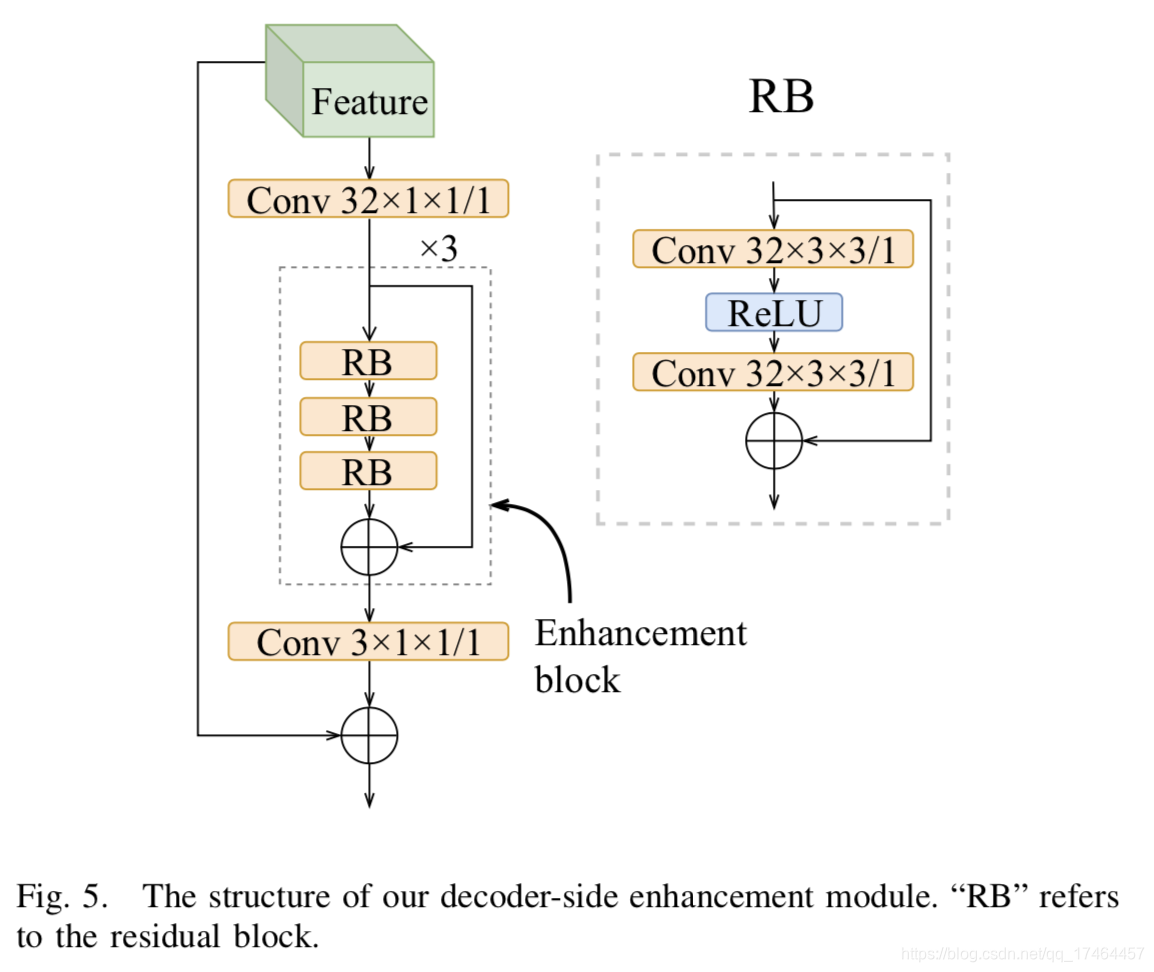
解码端增强
为了进一步提升重构图像的质量,作者在解码端重构出图像之后引入增强模块。增强模块如下图所示;
视频压缩中的应用
为了进一步说明本方法的有效性,将EDIC模型嵌入到视频压缩模型中,其框架图如下所示;

其中残差和运动信息由EDIC方法压缩,具体细节以及实验结果分析,可视化结果等请参考论文。

















 2983
2983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









