






giuhub: code
做的是attention,该attention比起以往的non-local来说很light-weight (主要是和SENet那样采用了scale的策略),而且照样很有效。
本文提出的attention叫**global context (GC) block—即全局的感受野。**因为轻量化,所以可以插在网络的任何位置,不像Non-local block那样用多了的话网络根本train不动。
作者补了Non-local的一些实验:


红色是query点,而heatmap则是该点attention到的区域,可以发现不同query点的attention区域都差不太多,改善这个就是作者的motivation。
首先介绍一下Non-local:
non-local是一种self-attention机制。

为何要提出这种self-attention机制?
以下图为例:

对于分割或检测任务来说,很有必要让网络的感受野大到能覆盖所有物体。对于绿色圆来说:用一个3*3的卷积可能能覆盖它,但对于黑色五角可能就不行了,这是就需要更大kernel的卷积核或空洞卷积来覆盖它。但是,更大的卷积核会带来feature map尺寸的急速下降和计算量的暴增,计算量的问题还可以用大卷积核分解为多个小卷积核代替来解决,但feature map降得太小是不能接受的,尤其是在分割中。此外,大卷积核和空洞卷积都还有一个共同毛病,就是可能他们的感受野大,但却可能不够大,可能在遇到红色矩形时都会崩溃。所以就需要一种机制来将整张图像的信息记录下来,具有覆盖整张图像的感受野。
于是self-attention就产生了(不过最早的self-attention其实是在NLP领域产生的)。
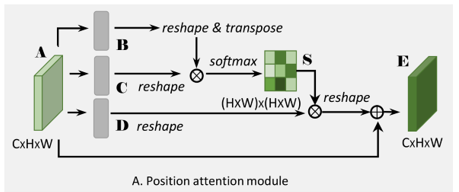
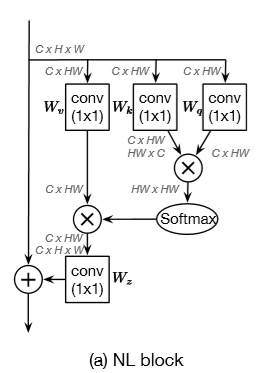
对于一个HWC的特征图,要想获取self-attention的关系,只需要将其与自身转置后的结果相乘得到HWHW的矩阵即为一个协方差矩阵,矩阵对角上为自身像素的重要行,而i-j元素表示i像素对j像素的重要性,有了这个结果就能对HW平面上的所有像素进行加权了,即attention。基本上多数attention都是基于此的,如:
Non-local:

PAM:
GCNet:

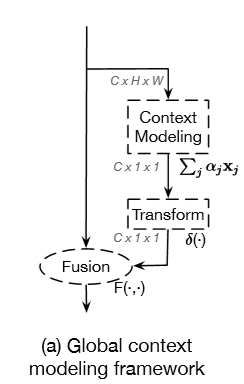
基本都基于下面的结构:
最经典的Non local可以画成:
然后有的说参数太多做成了:
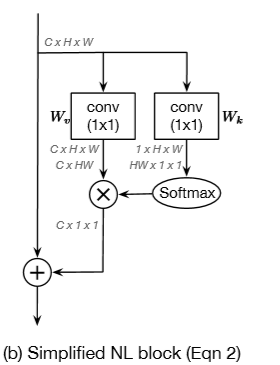
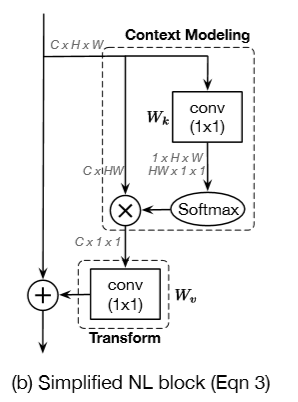
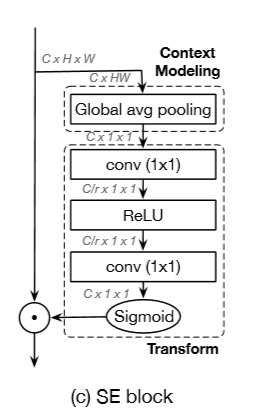
(SENet通过将通道数降低(/r)来降低运算时的参数)
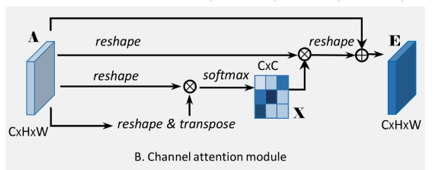
有的观察到某些通道对识别圆有利,有的通道对矩形有利,…呈现group效应,而提出了CAM(仿照PAM对channel操作):
有的用池化代替矩阵乘法操作节省计算量(CBAM 论文,代码):


各种各样的都有,参差不齐,可见:自注意力视频介绍
于是本文从SeNet(通道注意力)和Simplied Non Local各拉一半组成了又轻量化有效的GCNet:

实验:

scale指的是SENet中的那个点乘的fusing操作。

















 1347
1347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









