






本文主要内容:InternLM2 模型介绍和技术报告解读
1.模型介绍
原视频链接在此:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
本文只截取一些重点简要概括,具体看原视频
1.1 简介
LLM的概念我就不解释了,LLM本质是对自然语言建模(通俗点说:鹦鹉学舌),InternLM2是一个自回归LLM(chatGPT也是),在很多评测基准上达到了不错的效果(PS:打榜是一回事,落地应用做项目是另一回事),这里先记录一些视频中的要点

参数规模应该是有 1.8B,7B,20B这几种,关于模型大小,如果硬件资源够的话尽量用大点的模型(不考虑训练是否充分和数据质量的情况下,越大的模型建模能力越强)
关于base和chat模型:
1. base模型是在大量语料上预训练的,预训练是基于之前的token预测后面的token(输入1 预测 2 -> 输入1 2 预测 3 -> ...)
2. chat模型是经过SFT和RLHF的,SFT数据集一般像这样 { 指令:" ", user:" ", answer:" " },SFT训练时输入指令和user的内容,让模型输出answer,未经过SFT的模型只能预测下一个token显然不能回应你的输入prompt,经过SFT之后的模型就可以正常响应你的 prompt 了只不过有时候输出的东西不是你想要的,所以还要RLHF,RLHF是通过人类反馈作为奖励函数训练模型让它与人类的偏好进行对齐的过程(比如:不能说脏话,多输出正能量),具体过程网上可查我就不赘述了
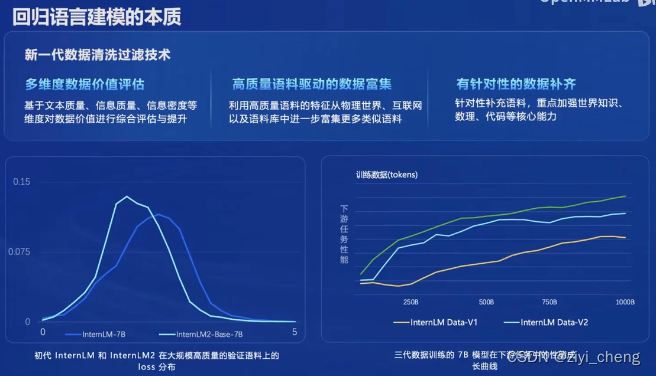
internLM2主要的提升在训练数据质量更高,因为LLM的本质是语言建模,数据质量高理论上效果不会差

这里注意一下:超长上下文目前主要的评测方式是“大海捞针”,这个评价方式只能证明能从大量的文本中提取关键信息,即 文本检索能力,其他如总结概括能力,推理能力,代码能力等目前都缺乏超长上下文情况下的评价方式,比如写个小说写着写着主角变了。。然后工具调用能力,单纯依靠原始的LLM能力很多时候都不可靠,一般都需要收集一些数据微调一下
当然这个PPT只是说 internLM2 在各项指标上性能大幅提升,没啥毛病
1.2 internLM2能力展示
下面是一些具体案例的介绍,简单贴在这吧:

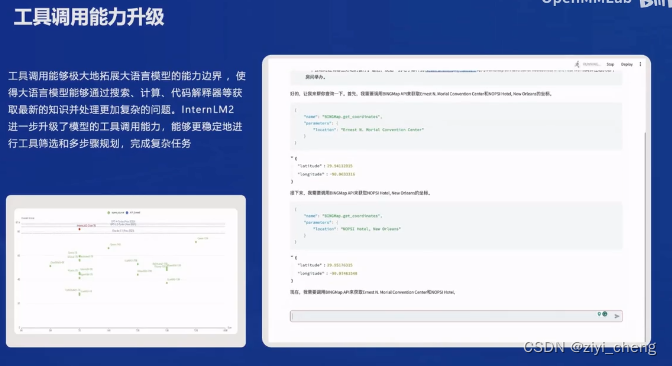
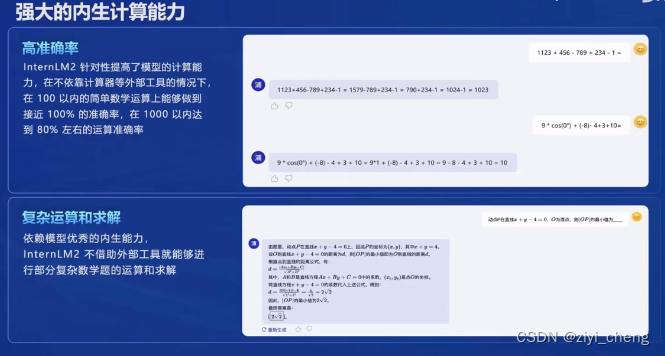
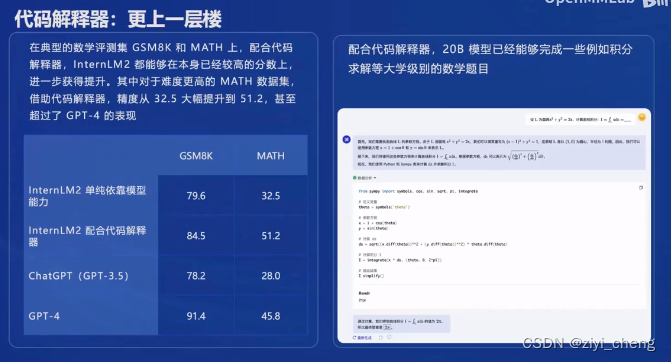
代码解释器可以让模型具备一定的数据分析能力(输入数据-生成代码-执行代码-输出图表)
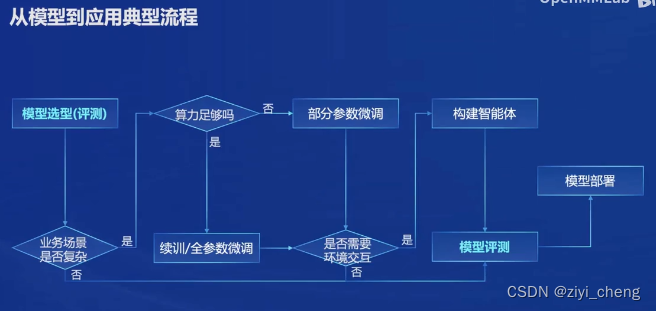
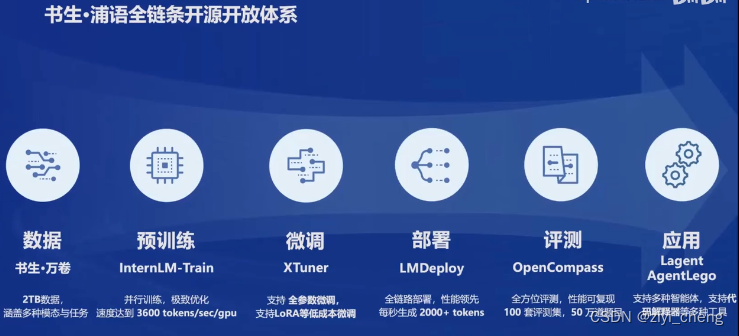
基于上面的LLM应用流程,openmmlab开源了一系列工具,目前我只用过 OpenCompass 评测工具,感觉不错,部署方面目前还是 vLLM 用的比较多,不知道 LMDeploy 怎么样,有机会用一下再说
2.技术报告
https://arxiv.org/pdf/2403.17297.pdf
中文翻译版:InternLM2 技术报告——社区翻译版 - 知乎
详细技术报告请看原文,这里我还是摘抄一些要点:
1.训练框架
大模型的训练,训练框架作为基础设施是非常重要的一环,千卡集群随时都会出现宕机,GPU掉线等异常情况,必须做容错处理,还要保证集群的通信效率,GPU在训练过程中大多数时间是在传输数据,而不是在进行计算。internLM2 的训练框架 InternEvo 通过实现一系列自适应分片技术(如Full-Replica、FullSharding和Partial-Sharding)减少了通信开销,通过参数预加载等方式实现了通信-计算重叠,提高整体系统性能。对于长序列,InternEvo将GPU内存管理分解为四个并行维度(数据、 张量、 序列和管道)和三个分片维度(参数、梯度和优化器状态)使用执行模拟器来识别和实施最优的并行化策略,还实施了内存管理技术来减少GPU内存碎片。容错性方面,引入了一个容错的预训练系统和一个为评估任务设计的解耦调度系统,通过诊断大模型相关的故障并自动恢复来提高容错性,提供及时的模型性能反馈,并通过异步保存机制确保了在系统自动检测到偶尔的硬件或网络故障时,仅丢失少量的训练进度
2.模型结构
主要结构跟LLaMa一样,但是将Wq,Wk,Wv矩阵合并提高效率,改变布局支持张量并行,采用分组查询注意力(GQA)支持长上下文
3.数据
预训练数据集来源为网页、论文、专利和书籍。首先将所有数据标准化为指定格式,然后根据内容类型和语言进行分类,将结果存储为JSON Lines(jsonl)格式;然后对所有数据应用了基于规则的过滤、数据去重、安全过滤和质量过滤等多个处理步骤。得到了一个丰富、安全且高质量的文本数据集
整个数据处理流程首先将来自不同来源的数据标准化以获得格式化数据。然后,使用启发式统计规则对数据进行过滤以获得干净数据。接下来,使用局部敏感哈希(LSH)方法对数据去重以获得去重数据。应用一个复合安全策略对数据进行过滤,得到安全数据。对不同来源的数据采用了不同的质量过滤策略,最终获得高质量预训练数据
4.训练
使用GPT-4的tokenization方法,预训练1.8B、7B和20B模型的总的token数范围从2.0T到2.6T,在第一阶段,使用长度不超过4k的预训练语料库。第二阶段,加入长度不超过32k的50%的预训练语料库。第三阶段,使用特定能力的增强数据。每一阶段都混合英文、中文和代码数据。
对齐:监督微调(SFT)和基于人类反馈的强化学习(RLHF)
SFT阶段:使用了一个包含1000万个指令数据实例的数据集,涵盖了各种主题,包括一般对话、NLP任务、数学问题、代码生成和函数调用等
RLHF阶段:针对原始RLHF存在的偏好冲突和奖励滥用的问题,提出了条件在线RLHF(Conditional OnLine RLHF, COOL RLHF),引入了一个条件奖励机制来调和不同的偏好,允许奖励模型根据特定条件动态地分配其注意力到各种偏好上,从而最优地整合多个偏好。此外,COOL RLHF采用多轮在线RLHF策略,以使LLM能够快速适应新的人类反馈,减少奖励滥用的发生。

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









