1. import package and download data
from atrader import *
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import statsmodels.api as sm
import datetime as dt
import scipy.stats as stats
import seaborn as sns
# 获取因子数据
# 单日多标的多因子
# 4个月的动量类因子
names = ['REVS60','REVS120','BIAS60','CCI20','PVT','MA10Close','DEA','RC20','RSTR63','DDI']
factors1 = get_factor_by_day(factor_list= names, target_list=list(get_code_list('hs300',date='2019-02-01').code), date='2019-02-28')
factors2 = get_factor_by_day(factor_list= names, target_list=list(get_code_list('hs300',date='2019-02-01').code), date='2019-03-29')
factors3 = get_factor_by_day(factor_list= names, target_list=list(get_code_list('hs300',date='2019-02-01').code), date='2019-04-30')
factors4 = get_factor_by_day(factor_list= names, target_list=list(get_code_list('hs300',date='2019-02-01').code), date='2019-05-31')
2. factors preprocess
# MAD:中位数去极值
def extreme_MAD(dt,n = 5.2):
median = dt.quantile(0.5) # 找出中位数
new_median = (abs((dt - median)).quantile(0.5)) # 偏差值的中位数
dt_up = median + n*new_median # 上限
dt_down = median - n*new_median # 下限
return dt.clip(dt_down, dt_up, axis=1) # 超出上下限的值,赋值为上下限
# Z值标准化
def standardize_z(dt):
mean = dt.mean() # 截面数据均值
std = dt.std() # 截面数据标准差
return (dt - mean)/std
# 行业中性化
shenwan_industry = {
'SWNLMY1':'sse.801010',
'SWCJ1':'sse.801020',
'SWHG1':'sse.801030',
'SWGT1':'sse.801040',
'SWYSJS1':'sse.801050',
'SWDZ1':'sse.801080',
'SWJYDQ1':'sse.801110',
'SWSPCL1':'sse.801120',
'SWFZFZ1':'sse.801130',
'SWQGZZ1':'sse.801140',
'SWYYSW1':'sse.801150',
'SWGYSY1':'sse.801160',
'SWJTYS1':'sse.801170',
'SWFDC1':'sse.801180',
'SWSYMY1':'sse.801200',
'SWXXFW1':'sse.801210',
'SWZH1':'sse.801230',
'SWJZCL1':'sse.801710',
'SWJZZS1':'sse.801720',
'SWDQSB1':'sse.801730',
'SWGFJG1':'sse.801740',
'SWJSJ1':'sse.801750',
'SWCM1':'sse.801760',
'SWTX1':'sse.801770',
'SWYH1':'sse.801780',
'SWFYJR1':'sse.801790',
'SWQC1':'sse.801880',
'SWJXSB1':'sse.801890'
}
# 构造行业哑变量矩阵
def industry_exposure(target_idx):
# 构建DataFrame,存储行业哑变量
df = pd.DataFrame(index = [x.lower() for x in target_idx],columns = shenwan_industry.keys())
for m in df.columns: # 遍历每个行业
# 行标签集合和某个行业成分股集合的交集
temp = list(set(df.index).intersection(set(get_code_list(m).code.tolist())))
df.loc[temp, m] = 1 # 将交集的股票在这个行业中赋值为1
return df.fillna(0) # 将 NaN 赋值为0
# 需要传入单个因子值和总市值
def neutralization(factor,MktValue,industry = True):
Y = factor.fillna(0)
df = pd.DataFrame(index = Y.index, columns = Y.columns) # 构建输出矩阵
for i in range(Y.shape[1]): # 遍历每一天的截面数据
if type(MktValue) == pd.DataFrame:
lnMktValue = MktValue.iloc[:,i].apply(lambda x:math.log(x)) # 市值对数化
lnMktValue = lnMktValue.fillna(0)
if industry: # 行业、市值
dummy_industry = industry_exposure(Y.index.tolist())
X = pd.concat([lnMktValue,dummy_industry],axis = 1,sort = False) # 市值与行业合并
else: # 仅市值
X = lnMktValue
elif industry: # 仅行业
dummy_industry = industry_exposure(factor.index.tolist())
X = dummy_industry
# X = sm.add_constant(X)
result = sm.OLS(Y.iloc[:,i].astype(float),X.astype(float)).fit() # 线性回归
df.iloc[:,i] = result.resid # 每日的截面数据存储到df中
return df
3. corr(mean) test
# 计算因子的相关系数矩阵函数
def factor_corr(factors):
factors = factors.set_index('code')
factors_process = standardize_z(extreme_MAD(factors.fillna(0)))
result = factors_process.fillna(0).corr()
return result
# 获取相关系数矩阵
factors_corr1 = factor_corr(factors1)
factors_corr2 = factor_corr(factors2)
factors_corr3 = factor_corr(factors3)
factors_corr4 = factor_corr(factors4)
factors_corr = (factors_corr1+factors_corr2+factors_corr3+factors_corr4).div(4) # 矩阵均值检验
# 相关系数检验
abs(factors_corr).mean()
abs(factors_corr).median()
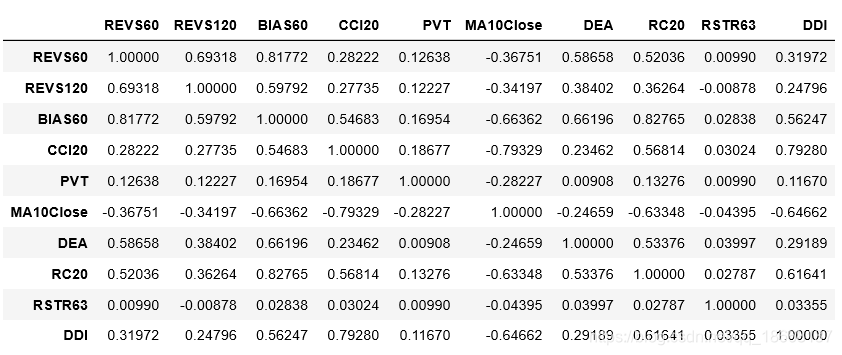
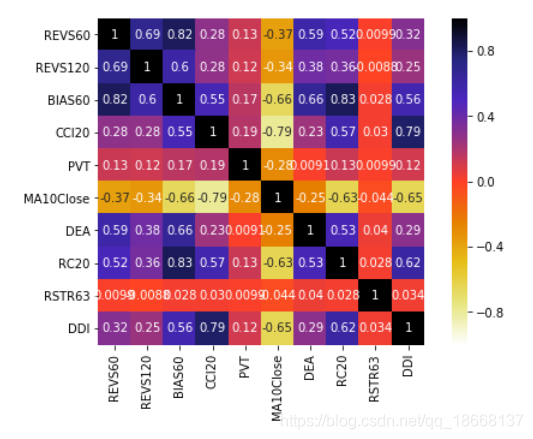
4. corr hot map plot
# 画图二
fig = plt.figure()
plt.subplots(figsize=(8, 6.4)) # 设置画面大小
sns.heatmap(factors_corr, annot=True, vmax=1, vmin=-1, square=True, cmap="CMRmap_r",)
plt.show()
5. factors equal combine
# 因子合成
# 等权法
corrnames = ['REVS60','REVS120','BIAS60','CCI20','MA10Close','DEA','RC20','DDI']
collinear_factors = factors4.loc[:,corrnames] # 共线的因子矩阵
composite_factor = collinear_factors.mul(1/len(corrnames)).sum(axis=1)
print(composite_factor)




























 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









