









最近我们被客户要求撰写关于随机波动率(SV)的研究报告,包括一些图形和统计输出。
相关视频:随机波动率SV模型原理和Python对标普SP500股票指数时间序列波动性预测
随机波动率SV模型原理和Python对标普SP500股票指数时间序列波动性预测
资产价格具有随时间变化的波动性(逐日收益率的方差)。在某些时期,收益率是高度变化的,而在其他时期则非常平稳。随机波动率模型用一个潜在的波动率变量来模拟这种情况,该变量被建模为随机过程。下面的模型与 No-U-Turn Sampler 论文中描述的模型相似,Hoffman (2011) p21。

这里,r是每日收益率序列,s是潜在的对数波动率过程。
建立模型
首先,我们加载标普500指数的每日收益率。
returns = (pm.get_data("SP500.csv"))
returns[:5]
![]()
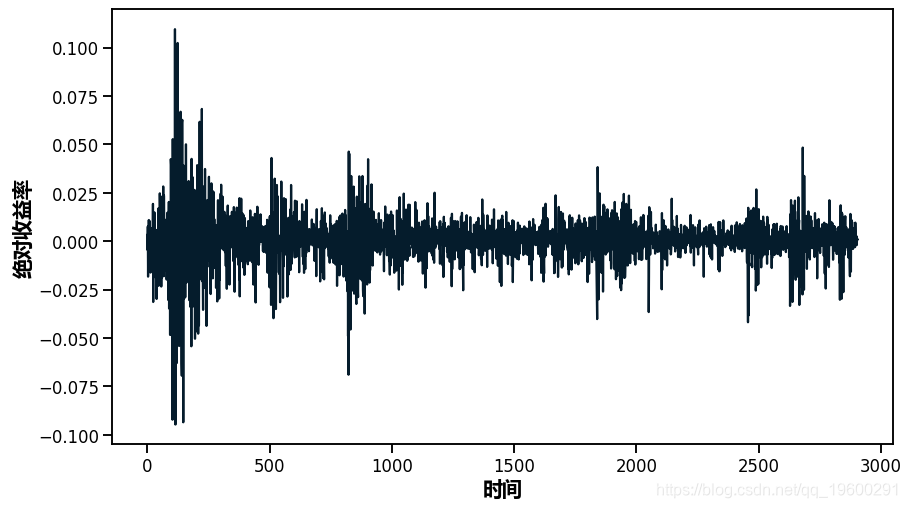
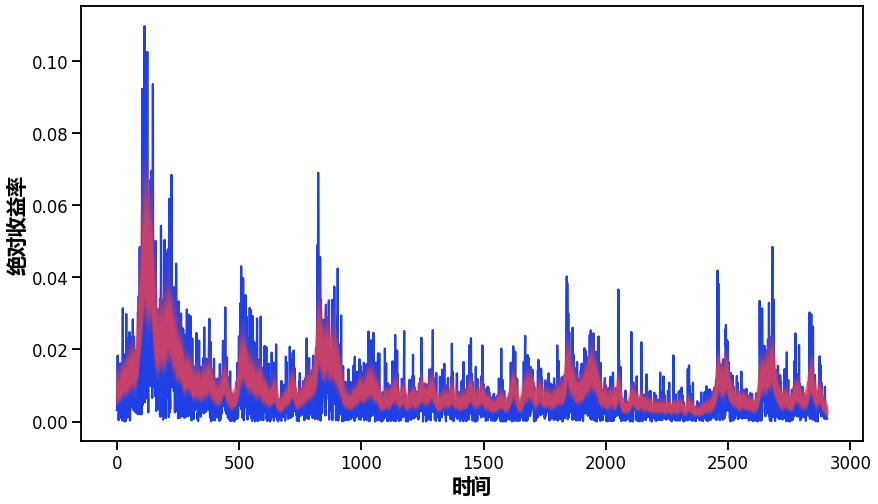
正如你所看到的,波动性似乎随着时间的推移有很大的变化,但集中在某些时间段。在2500-3000个时间点附近,你可以看到2009年的金融风暴。
ax.plot(returns)
 指定模型。
指定模型。
GaussianRandomWalk('s', hape=len(returns))
nu = Exponential( .1)
r = StudentT( pm.math.exp(-2*s),
obs=returns)拟合模型
对于这个模型,最大后验(Maximum A Posteriori,MAP)概率估计具有无限的密度。然而,NUTS给出了正确的后验。
pm.sample(tune=2000
Auto-assigning NUTS sampler...

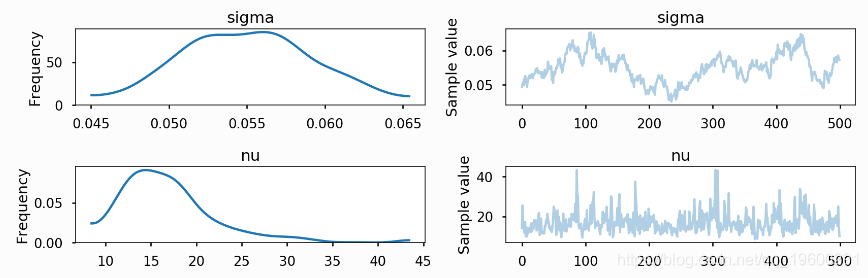
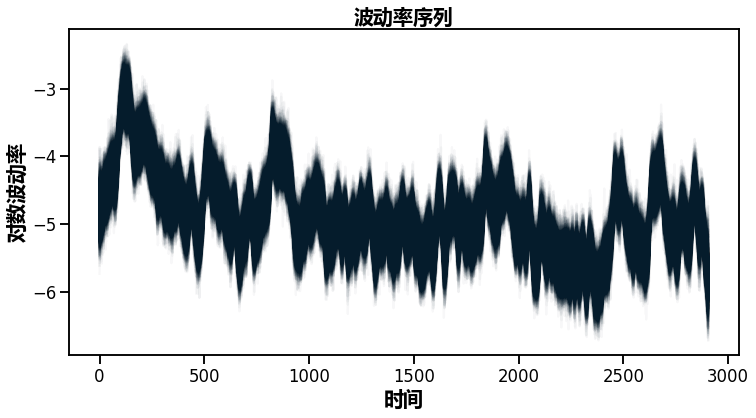
plot(trace['s']);
观察一段时间内的收益率,并叠加估计的标准差,我们可以看到该模型是如何拟合一段时间内的波动率的。
plot(returns)
plot(exp(trace[s]);
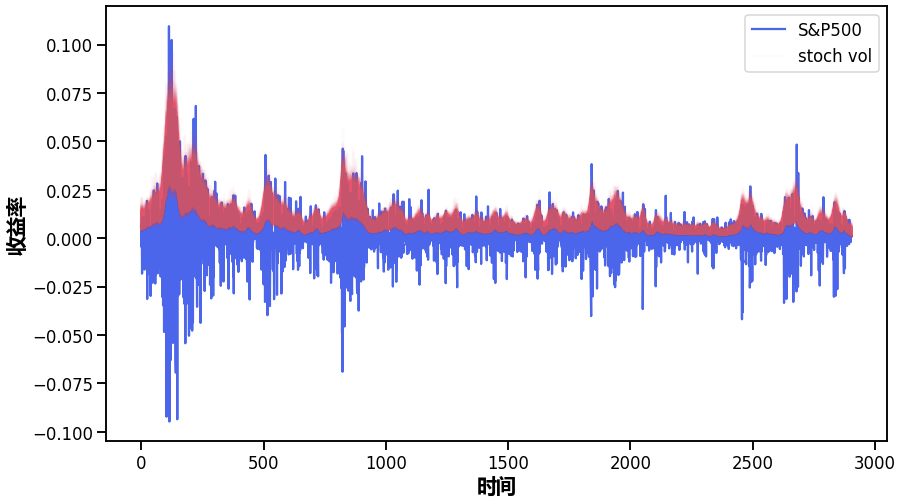
np.exp(trace[s])
参考文献
- Hoffman & Gelman. (2011). The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo.















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









