









最近我们被客户要求撰写关于回归的研究报告,包括一些图形和统计输出。
在之前的文章中,我们研究了许多使用 多输出回归分析的方法。在本教程中,我们将学习如何使用梯度提升决策树GRADIENT BOOSTING REGRESSOR拟合和预测多输出回归数据。对于给定的 x 输入数据,多输出数据包含多个目标标签。本教程涵盖:
- 准备数据
- 定义模型
- 预测和可视化结果
我们将从加载本教程所需的库开始。
相关视频:Boosting集成学习原理与R语言提升回归树BRT预测短鳍鳗分布生态学实例
Boosting集成学习原理与R语言提升回归树BRT预测短鳍鳗分布生态学实例
,时长10:25
视频:从决策树到随机森林:R语言信用卡违约分析信贷数据实例
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
,时长10:11
准备数据
首先,我们将为本教程创建一个多输出数据集。它是随机生成的数据,具有以下一些规则。该数据集中有三个输入和两个输出。我们将绘制生成的数据以直观地检查它。
f = plt.figure()
f.add_subplot(1,2,1)
plt.title("Xs 输入数据")
plt.plot(X)
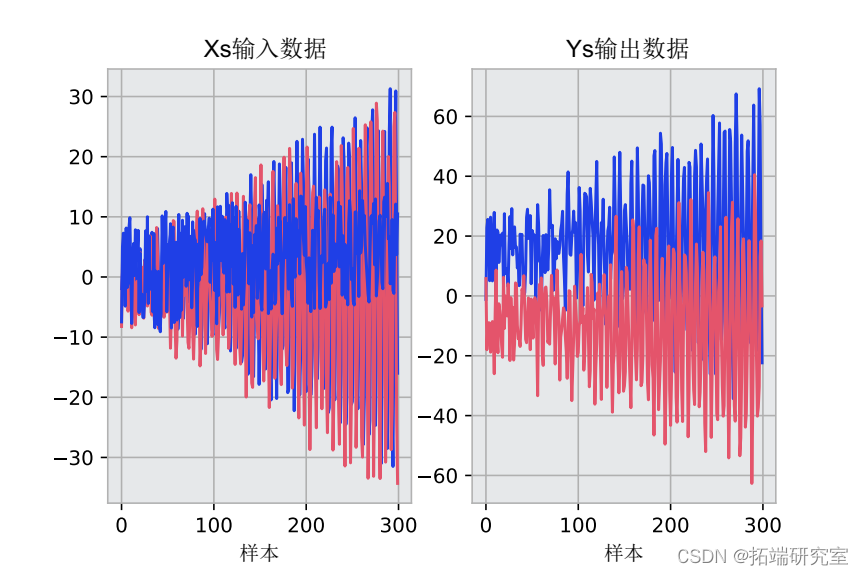
接下来,我们将数据集拆分为训练和测试部分并检查数据形状。
print("xtrain:", xtrain.shape, "ytrian:", ytrain.shape)

定义模型
我们将定义模型。作为估计,我们将使用默认参数实现。可以通过 print 命令查看模型的参数。
model = MutRer(es=gbr)
print(model )![]()
现在,我们可以用训练数据拟合模型并检查训练结果。
fit(xtrain, ytrain)
score(xtrain, ytrain)
预测和可视化结果
我们将使用经过训练的模型预测测试数据,并检查 y1 和 y2 输出的 MSE 率。
predict
![]()
最后,我们将在图中可视化结果并直观地检查它们。
xax = range(len)
plt.plot
plt.legend
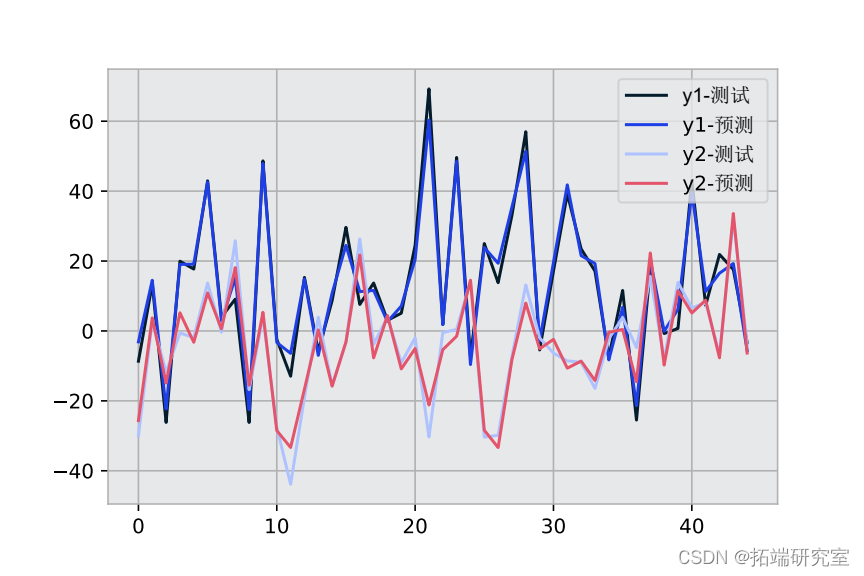
在本教程中,我们简要学习了如何在 Python 中训练了多输出数据集和预测的测试数据。

















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









