







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🎧 “开发者福音!PySpur 开源 AI 代理构建工具,拖拽式工作流轻松搞定复杂任务”
大家好,我是蚝油菜花。你是否也遇到过——
- 👉 想快速构建 AI 工作流,却被复杂的代码劝退?
- 👉 需要处理多模态数据,却苦于没有合适的工具?
- 👉 希望快速迭代 AI 模型,却找不到高效的开发环境?
今天要介绍的 PySpur,正是为解决这些问题而生!这款开源的轻量级可视化 AI 智能体工作流构建器,通过拖拽式界面,让你无需编写复杂代码,就能快速构建、测试和迭代 AI 工作流。无论是多模态数据处理、RAG 技术,还是文件上传和结构化输出,PySpur 都能轻松应对。接下来,我们将深入探讨它的核心功能和技术原理,并手把手教你如何快速上手!
🚀 快速阅读
PySpur 是一款开源的轻量级可视化 AI 智能体工作流构建器。
- 核心功能:支持拖拽式界面、多模态数据处理、RAG 技术、文件上传和结构化输出。
- 技术原理:基于 Python 开发,支持多种工具集成,提供模块化构建块和节点级调试功能。
PySpur 是什么
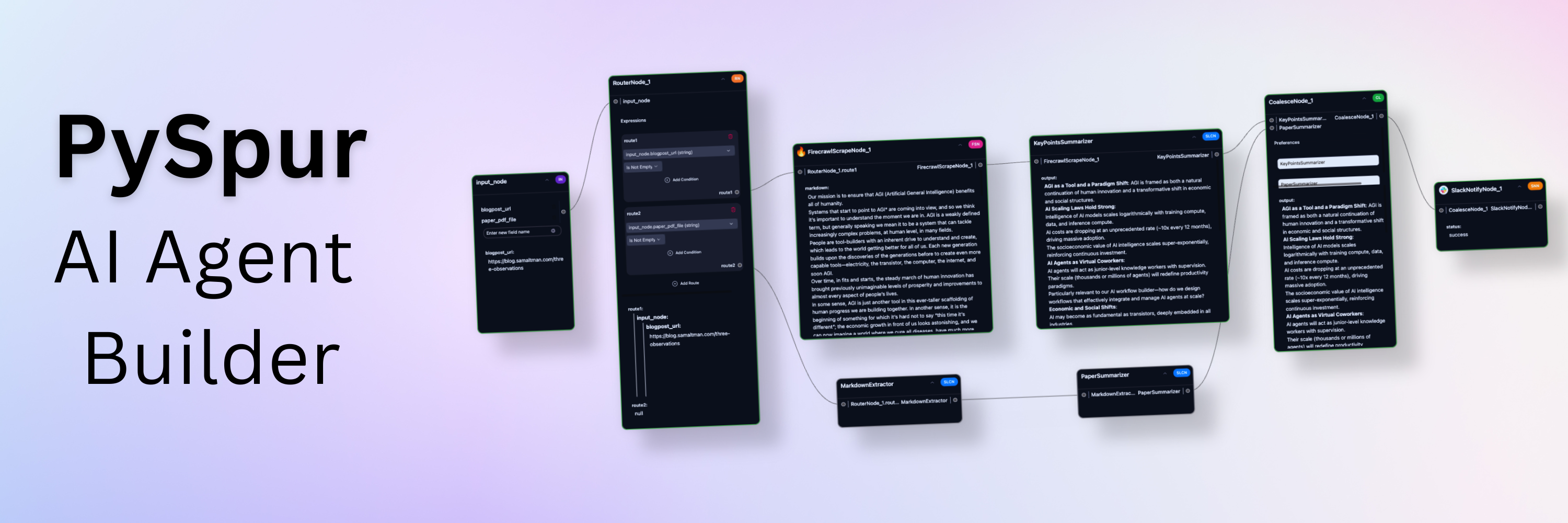
PySpur 是一款开源的轻量级可视化 AI 智能体工作流构建器,旨在简化 AI 系统的开发流程。通过拖拽式界面,用户可以快速构建、测试和迭代 AI 工作流,无需编写复杂代码。它支持循环与记忆功能、文件上传、结构化输出、RAG 技术、多模态数据处理(文本、图像、视频等)及与多种工具(如 Slack、Google Sheets)的集成。
PySpur 提供简单的安装和部署方式,适合快速构建智能应用,尤其适合非技术背景的用户和开发者快速上手。无论是智能对话系统开发、自动化任务管理,还是多模态数据分析和文档处理,PySpur 都能提供强大的支持。
PySpur 的主要功能
- 拖拽式构建:提供直观的拖拽界面,用户用简单的拖拽操作快速构建、测试和迭代 AI 工作流,无需编写复杂代码。
- 循环与记忆功能:支持智能体在多次迭代中记住之前的状态,模型从每次反馈中学习和优化。
- 文件上传与处理:用户上传文件或粘贴 URL,支持文档解析、摘要提取等任务,方便处理各种文档数据。
- 结构化输出:提供 JSON Schema 的 UI 编辑器,帮助用户生成结构化的数据输出格式。
- RAG 支持:支持解析、分块、嵌入数据到向量数据库,使得检索和生成模型的调用更高效、更精确,提升数据处理和模型响应的性能。
- 多模态支持:支持处理多种模态的数据,包括文本、图像、音频、视频等。
- 工具集成:支持与多种工具和平台集成,如 Slack、Firecrawl.dev、Google Sheets、GitHub 等,增强工作流的功能,提升系统的整体协调性。
如何运行 PySpur
使用 pyspur Python 包
这是最快速的入门方式,要求 Python 3.12 或更高版本。
1. 安装 PySpur
pip install pyspur
2. 初始化新项目
pyspur init my-project
cd my-project
这将创建一个带有 .env 文件的新目录。
3. 启动服务器
pyspur serve --sqlite
默认情况下,PySpur 应用将在 http://localhost:6080 启动,并使用 SQLite 数据库。建议在 .env 文件中配置 PostgreSQL 实例 URL 以获得更稳定的体验。
4. [可选] 自定义部署
你可以通过以下两种方式自定义 PySpur 部署:
a. 通过应用(推荐):
- 在应用中的 API Keys 标签页添加各种提供商的 API 密钥(如 OpenAI、Anthropic 等)。
- 更改会立即生效。
b. 手动配置:
- 编辑项目目录中的
.env文件。 - 建议在
.env中配置 PostgreSQL 数据库以提高可靠性。 - 使用
pyspur serve重启应用。如果不使用 PostgreSQL,请添加--sqlite。
使用 Docker(推荐用于生产环境)
这是生产部署的推荐方式:
1. 安装 Docker
首先,根据操作系统的官方安装指南安装 Docker:
- Docker for Linux:https://docs.docker.com/engine/install/
- Docker Desktop for Mac:https://docs.docker.com/desktop/install/mac-install/
2. 创建 PySpur 项目
安装 Docker 后,使用以下命令创建新的 PySpur 项目:
curl -fsSL https://raw.githubusercontent.com/PySpur-com/pyspur/main/start_pyspur_docker.sh | bash -s pyspur-project
这将:
- 在名为
pyspur-project的新目录中启动 PySpur 项目。 - 设置必要的配置文件。
- 自动启动由本地 PostgreSQL Docker 实例支持的 PySpur 应用。
3. 访问 PySpur
在浏览器中访问 http://localhost:6080。
4. [可选] 自定义部署
你可以通过以下两种方式自定义 PySpur 部署:
a. 通过应用(推荐):
- 在应用中的 API Keys 标签页添加各种提供商的 API 密钥(如 OpenAI、Anthropic 等)。
- 更改会立即生效。
b. 手动配置:
- 编辑项目目录中的
.env文件。 - 使用以下命令重启服务:
docker compose up -d
资源
- 项目主页:https://www.pyspur.dev
- GitHub 仓库:https://github.com/PySpur-Dev/pyspur
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









