







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🚀 「PDF分析要失业?阿里开源视觉文档核弹:多智能体动态推理,复杂图表秒变答案」
大家好,我是蚝油菜花。你是否还在为这些场景抓狂——
- 👉 百页技术文档图文混杂,关键信息像玩「大家来找茬」
- 👉 学术论文图表公式连环嵌套,检索3小时理解5分钟
- 👉 产品手册跨页流程图看不懂,AI生成答案总在瞎编…
今天揭秘阿里通义实验室的 ViDoRAG ,重新定义视觉文档理解!这个融合多模态检索与动态推理的框架,让AI真正学会「看图说话」:
- ✅ 高斯混合模型 智能调配文本/视觉权重
- ✅ Seeker-Inspector-Answer 三体协作推理
- ✅ 动态调整检索粒度 拒绝无效信息轰炸
这个由阿里巴巴通义实验室联合中科大、上交大推出的视觉文档检索增强生成框架,基于多智能体协作和动态迭代推理,显著提升了复杂视觉文档的检索和生成效率。无论是教育、金融还是医疗领域,ViDoRAG 都能为你提供精准的文档分析和答案生成服务。接下来,让我们一起深入了解这个强大的工具!
🚀 快速阅读
ViDoRAG 是一个基于多智能体协作的视觉文档检索增强生成框架。
- 核心功能:整合视觉和文本信息,支持动态迭代推理,提升复杂文档的理解和生成效率。
- 技术原理:采用高斯混合模型(GMM)的多模态混合检索策略,动态调整检索结果数量,优化生成质量。
ViDoRAG 是什么
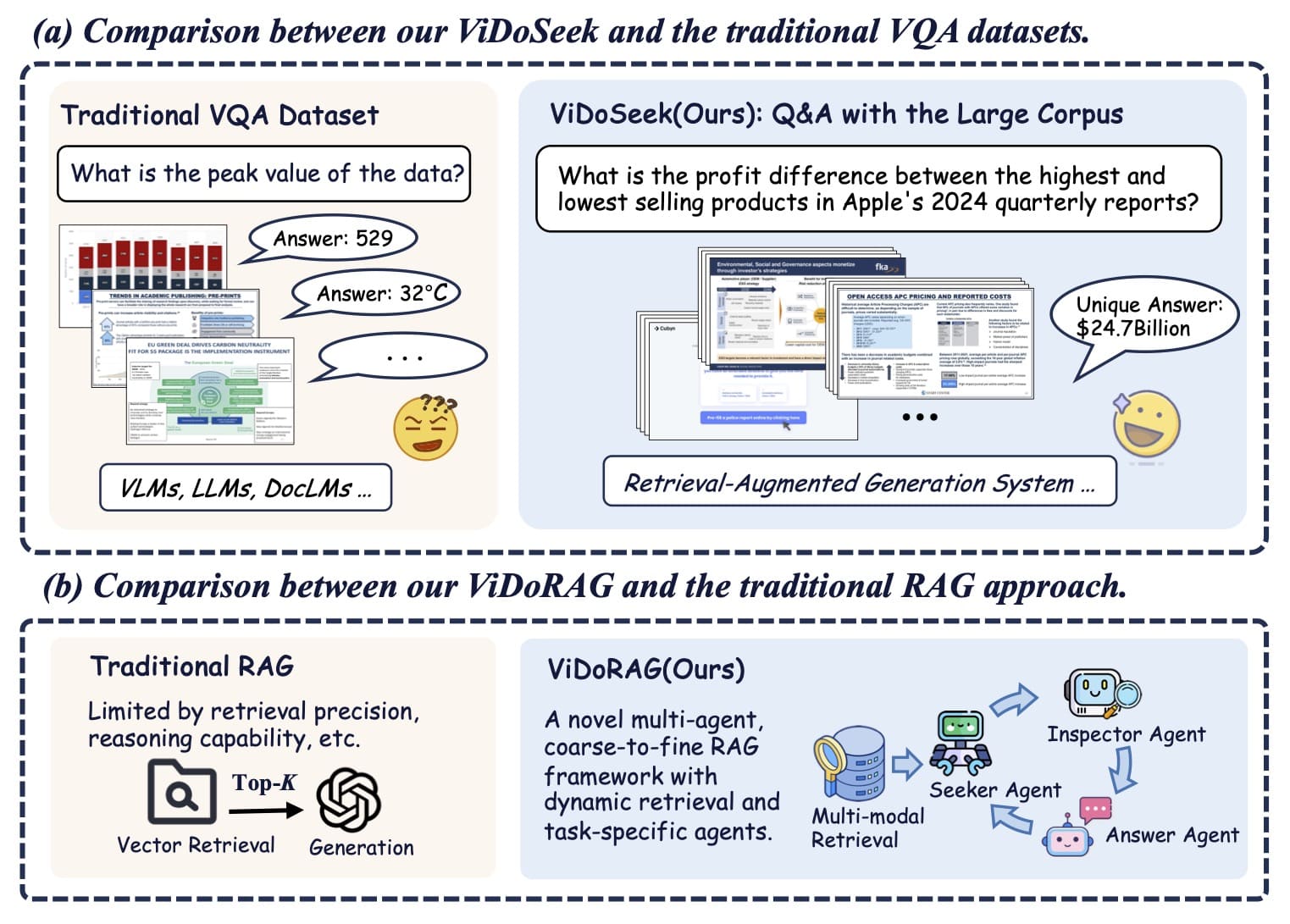
ViDoRAG 是阿里巴巴通义实验室联合中国科学技术大学和上海交通大学推出的视觉文档检索增强生成框架。它基于多智能体协作和动态迭代推理,解决了传统方法在处理复杂视觉文档时的检索和推理局限性。
ViDoRAG 使用高斯混合模型(GMM)的多模态混合检索策略,动态调整检索结果数量,优化文本和视觉信息的整合。框架中包含 Seeker、Inspector 和 Answer 三种智能体,分别负责快速筛选、详细审查和最终答案生成,基于迭代交互逐步细化答案,提升生成质量和一致性。
ViDoRAG 的主要功能
- 多模态检索:整合视觉和文本信息,实现精准的文档检索。
- 动态迭代推理:多智能体协作(Seeker、Inspector、Answer Agent),逐步细化答案,提升推理深度和准确性。
- 复杂文档理解:支持单跳和多跳推理,处理复杂的视觉文档内容。
- 生成一致性保障:基于 Answer Agent 确保最终答案的准确性和一致性。
- 高效生成:动态调整检索结果数量,减少计算开销,提升生成效率。
ViDoRAG 的技术原理
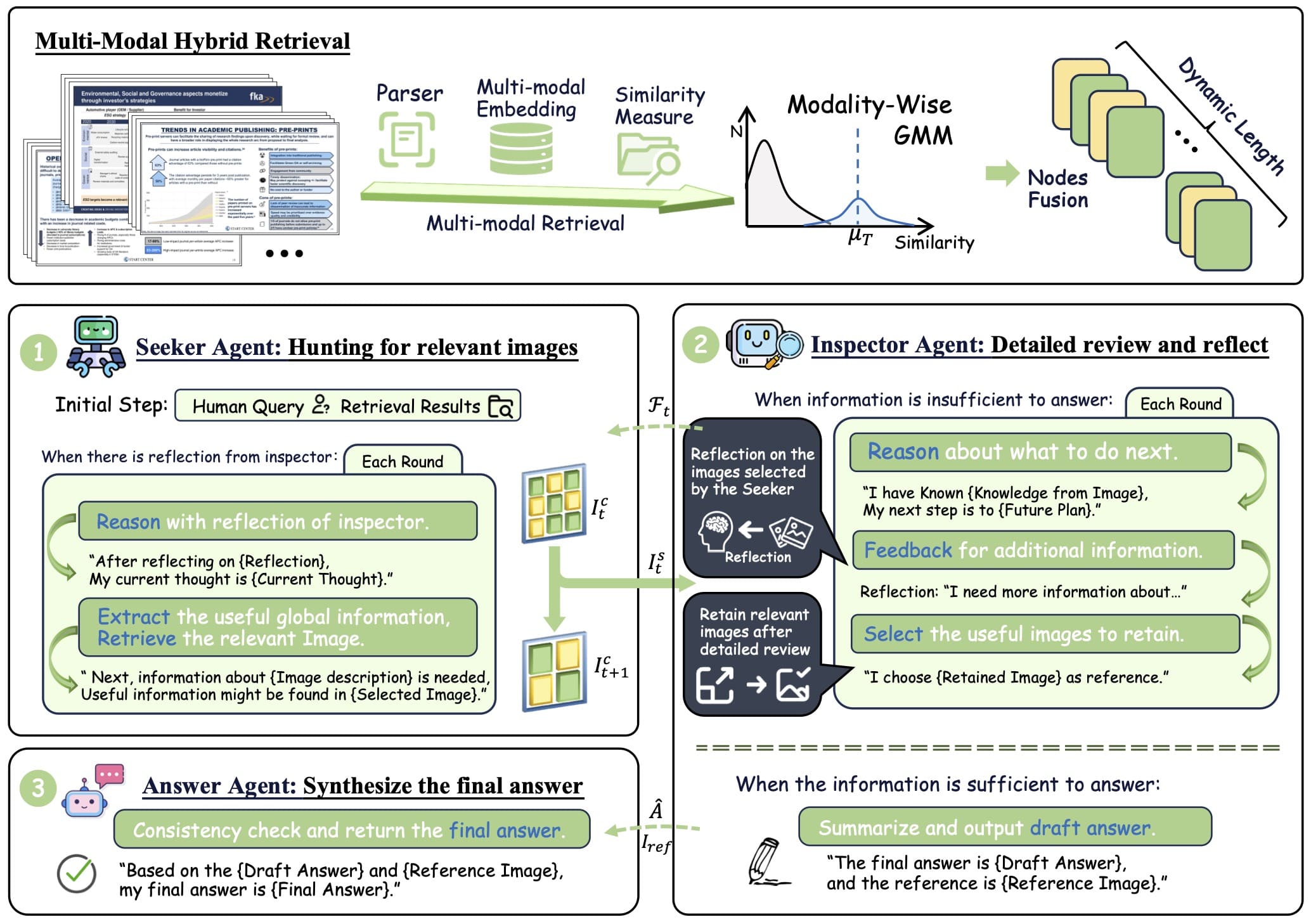
- 多模态混合检索:结合文本和视觉检索结果,基于高斯混合模型(GMM)动态调整检索结果数量。GMM 拟合查询与文档集合的相似度分布,动态确定最优的检索结果数量(Top-K),避免固定数量检索带来的噪声和计算开销,有效整合视觉和文本信息,提升检索精度,减少无关信息的干扰。
- 动态迭代推理框架:
- Seeker Agent:负责快速筛选相关图像或文档片段,提供全局线索。
- Inspector Agent:对筛选结果进行详细审查,提供反馈或初步答案。
- Answer Agent:整合 Inspector 的初步答案,验证一致性生成最终答案。
- 粗到细的生成策略:从全局视角开始,逐步聚焦到局部细节,多智能体协作实现从粗到细的生成过程,减少无关信息的干扰,提升生成效率和准确性。
- 推理能力激活:基于迭代推理和多智能体协作,激活模型的推理能力,特别是在处理复杂视觉文档时,提升模型在多跳推理和复杂文档理解任务中的表现。
- 动态检索长度调整:基于 GMM 动态调整检索结果数量,避免固定 Top-K 值带来的局限性,减少计算开销,提升检索效率和生成质量。
如何运行 ViDoRAG
1. 环境准备
# 创建环境
conda create -n vidorag python=3.10
# 克隆项目
git clone https://github.com/alibaba-nlp/ViDoRAG.git
cd ViDoRAG
# 安装依赖
pip install -r requirements.txt
2. 构建索引数据库
在嵌入整个数据集之前,可以运行 ./llm/vl_embedding.py 检查嵌入模型是否正确加载:
python ./llm/vl_embedding.py
然后运行 ingestion.py 嵌入整个数据集:
# 文档嵌入和多模态嵌入
python ./ingestion.py
3. 运行多模态检索器
尝试使用基本的单模态搜索引擎:
from search_engine import SearchEngine
# 初始化引擎
search_engine = SearchEngine(dataset='ViDoSeek', node_dir_prefix='colqwen_ingestion',embed_model_name='vidore/colqwen2-v1.0')
# 检索结果
recall_results = search_engine.search('some query')
4. 运行多智能体生成
可以直接使用 vidorag_agents.py 脚本进行生成,或将其集成到自己的框架中:
from llms.llm import LLM
vlm = LLM('qwen-vl-max')
agent = ViDoRAG_Agents(vlm)
answer=agent.run_agent(query='Who is Tim?', images_path=['./data/ExampleDataset/img/00a76e3a9a36255616e2dc14a6eb5dde598b321f_1.jpg','./data/ExampleDataset/img/00a76e3a9a36255616e2dc14a6eb5dde598b321f_2.jpg'])
print(answer)
5. 运行评估
使用基于 LLM 的评估方法进行端到端评估:
python eval.py \
--experiment_type retrieval_infer ## 选择 retrieval_infer/dynamic_hybird_retrieval_infer/vidorag
--dataset ViDoSeek ## 数据集文件夹名称
--embed_model_name_vl ## 视觉语言嵌入模型名称
--embed_model_name_text ## 文本嵌入模型名称
--embed_model_name ## 仅用于单一嵌入模型评估
--generate_vlm ## 视觉语言模型名称,如 gpt-4o/qwen-max-vl
资源
- GitHub 仓库:https://github.com/Alibaba-NLP/ViDoRAG
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









