







大型语言模型(LLM)的进步极大地增强了自然语言处理(NLP)的能力,实现了上下文理解、代码生成和推理等功能。 然而,一个关键的限制因素依然存在:上下文窗口大小受限。 大多数 LLM 只能处理固定数量的文本,通常最多 128K 标记,这限制了它们处理需要大量上下文的任务的能力,例如分析冗长文档或调试大型代码库。 由于这些限制,通常需要采用文本分块等变通方法,从而增加了计算的复杂性。 要克服这些挑战,就需要能在不影响性能的前提下有效扩展上下文长度的模型。
Qwen AI 的最新版本
Qwen AI 推出了两个新模型:Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M,旨在支持多达 100 万个代币的上下文长度。 这些模型由阿里巴巴集团的 Qwen 团队开发,还配备了一个开源推理框架,专为处理长上下文而优化。 这一进步使开发人员和研究人员能够一次性处理更大的数据集,为需要扩展上下文处理的应用提供了实用的解决方案。 此外,这些模型还改进了稀疏关注机制和内核优化,从而加快了扩展输入的处理时间。
技术细节和优势
Qwen2.5-1M 系列保留了基于变换器的架构,并集成了分组查询关注(GQA)、旋转位置嵌入(RoPE)和 RMSNorm 等功能,以确保在长语境下的稳定性。 训练涉及自然数据集和合成数据集,中间填充(FIM)、段落重新排序和基于位置的检索等任务增强了模型处理长距离依赖关系的能力。 稀疏注意力方法(如双块注意力(DCA))可将序列划分为易于管理的块,从而实现高效推理。 渐进式预训练策略将上下文长度从 4K 逐步扩展到 100 万标记,在控制计算需求的同时优化了效率。 这些模型与 vLLM 的开源推理框架完全兼容,简化了开发人员的集成工作。
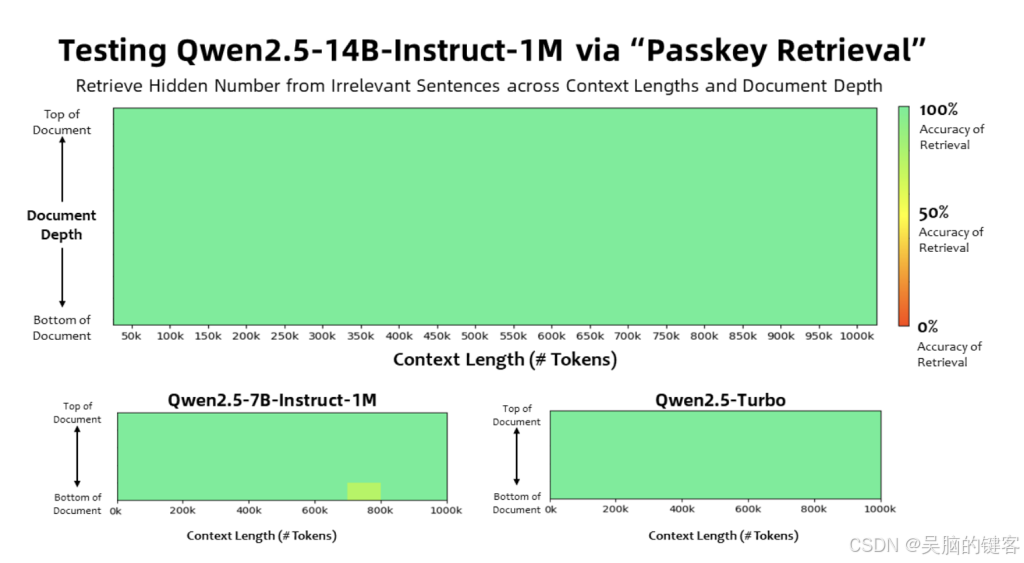
结果与启示
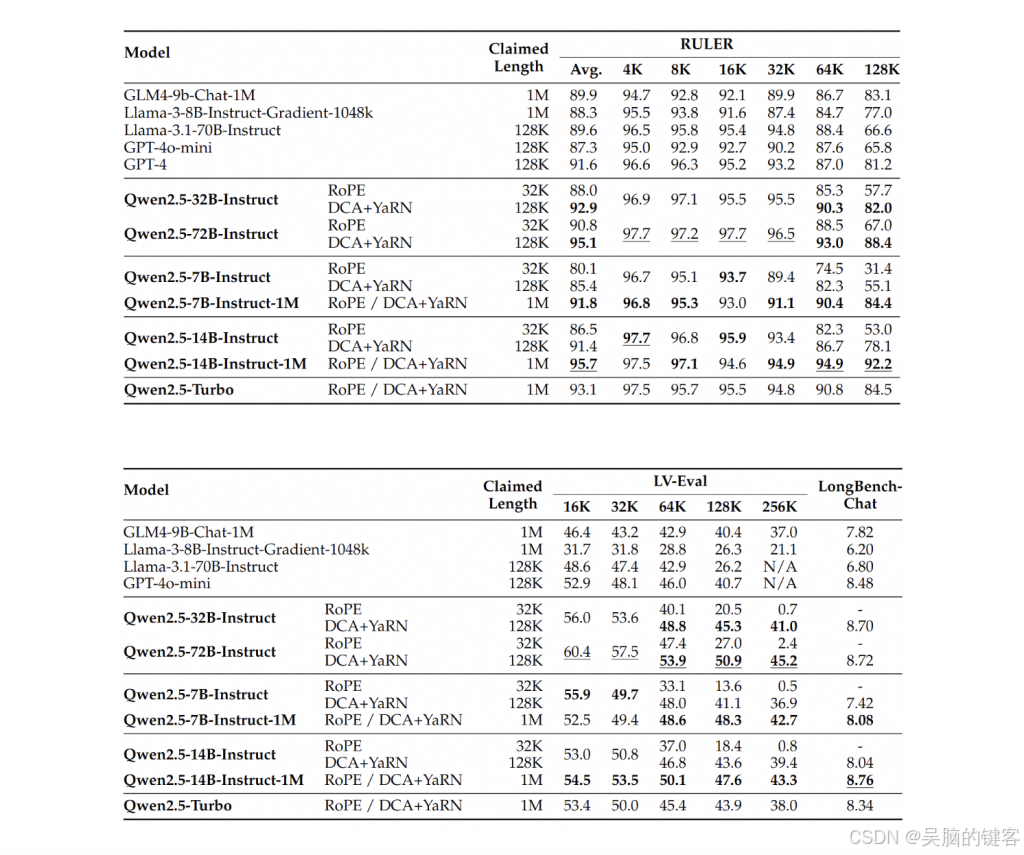
基准测试结果证明了 Qwen2.5-1M 模型的能力。 在 "密码检索测试 "中,7B 和 14B 变体成功检索了 100 万个标记中的隐藏信息,展示了它们在长语境场景中的有效性。 在其他基准测试中,包括 RULER 和 Needle in a Haystack (NIAH),14B 模型的表现优于 GPT-4o-mini 和 Llama-3 等其他模型。 稀疏注意力技术缩短了推理时间,在 Nvidia H20 GPU 上实现了高达 6.7 倍的提速。 这些结果凸显了模型兼具高效和高性能的能力,使其适用于需要广泛语境的实际应用。
快速上手
Qwen2.5-7B-Instruct-1M
Qwen2.5 的代码已在最新的抱抱脸转换器中使用,我们建议您使用最新版本的转换器。 如果转换器<4.37.0,您将会遇到以下错误:
KeyError: 'qwen2'
这里提供了一个 apply_chat_template 的代码片段,向您展示如何加载标记符和模型,以及如何生成内容。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct-1M"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
处理超长文本
为了提高长序列的处理精度和效率,我们开发了一种基于 vLLM 的高级推理框架,其中包含稀疏注意力和长度外推法。 这种方法大大提高了超过 256K 字节的序列的模型生成性能,并将高达 100 万字节的序列的生成速度提高了 3 到 7 倍。
在此,我们提供了使用我们的框架部署 Qwen2.5-1M 模型的分步说明。
- 系统准备
为达到最佳性能,我们建议使用支持优化内核的 Ampere 或 Hopper 架构 GPU。 确保您的系统满足以下要求:
- CUDA 版本:12.1 或 12.3
- Python 版本: >=3.9和<=3.12
显存要求:
- 处理 100 万个令牌序列:
- Qwen2.5-7B-Instruct-1M:至少 120GB 显存(各 GPU 总计)。
- Qwen2.5-14B-Instruct-1M:至少 320GB 显存(各 GPU 总计)。
- 安装依赖项
目前,你需要从我们的自定义分支克隆 vLLM 仓库,然后手动安装。 我们正在努力将我们的分支合并到主 vLLM 项目中。
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git
cd vllm
pip install -e . -v
- 启动 vLLM
vLLM 支持离线推理或启动类 openai 服务器。
离线推理示例
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct-1M")
# Pass the default decoding hyperparameters of Qwen2.5-7B-Instruct
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=512)
# Input the model name or path. See below for parameter explanation (after the example of openai-like server).
llm = LLM(model="Qwen/Qwen2.5-7B-Instruct-1M",
tensor_parallel_size=4,
max_model_len=1010000,
enable_chunked_prefill=True,
max_num_batched_tokens=131072,
enforce_eager=True,
# quantization="fp8", # Enabling FP8 quantization for model weights can reduce memory usage.
)
# Prepare your prompts
prompt = "Tell me something about large language models."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# generate outputs
outputs = llm.generate([text], sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
类 Openai 服务器示例
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill --max-num-batc[hed-tokens 131072 \
--enforce-eager \
--max-num-seqs 1
# --quantization fp8 # Enabling FP8 quantization for model weights can reduce memory usage.
然后,您就可以使用 curl 或 python 与已部署的模型进行交互。
参数解释:
- –tensor-parallel-size
- 设置为使用的 GPU 数量。 7B 模型最多 4 个 GPU,14B 模型最多 8 个 GPU。
- –max-model-len
- 定义最大输入序列长度。 如果遇到内存不足问题,请减少该值。
- –max-num-batched-tokens
- 设置分块预填充中的分块大小。 建议使用 131072 以获得最佳性能。
- –max-num-seqs
- 限制处理的并发序列数。
有关 vLLM 的用法,您也可以参考我们的文档。
结论
Qwen2.5-1M 系列在保持效率和可访问性的同时,大幅扩展了上下文长度,从而解决了 NLP 中的关键限制。 通过克服长期阻碍 LLM 的限制,这些模型为从分析大型数据集到处理整个代码库等各种应用开辟了新的可能性。 Qwen2.5-1M 在稀疏注意力、内核优化和长上下文预训练等方面进行了创新,为处理复杂、上下文繁重的任务提供了实用而有效的工具。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









