









Zero-Shot Learning
零样本学习总体来说是一种特殊的迁移学习。旨在将源域上训练完成的模型,迁移到没有标注数据的目标域中。因为缺少标注数据,所以在迁移过程,源域模型不能对目标域数据进行拟合训练。即源域模型需要直接在目标域上进行测试。如下图所示
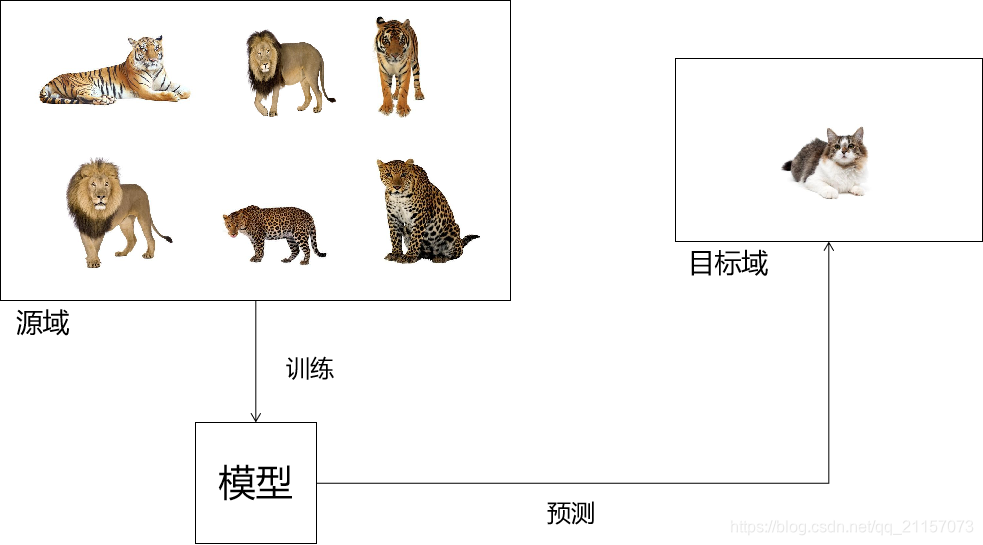
- 猫没有在源域中出现过
- 猫在目标域中没有标注样本可供迁移训练
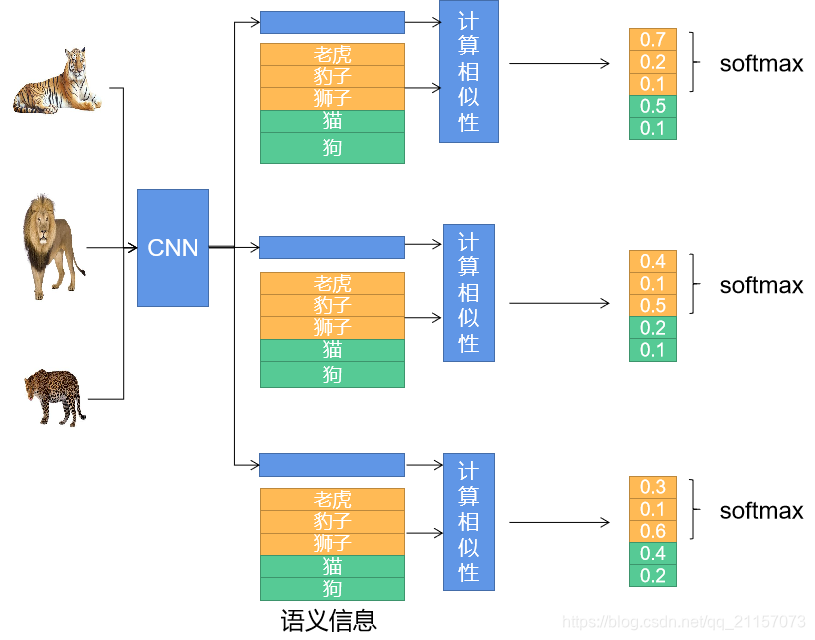
现阶段对于zero-shot研究,大多需要引入语义信息的帮助。即在训练源域数据过程中,模型不仅可以观察到图片信息,还可以观察到与图片对应的语义信息,同时语义信息是纵贯目标域与源域,因此可以建立源域与目标域之间的桥梁。简单分类架构如下图所示,其主要将视觉特征映射到语义空间中计算损失。
Zero-Shot Object Detection
对于物体检测而言,每张图片中可能有多个物体。测试样本中可能既包含新的物体也包含源域中出现过的物体,这比上述zero-shot learning难度更大。
论文:Transductive Learning for Zero-Shot Object Detection
Shafin Rahman, Salman Khan, Nick Barnes; The IEEE International Conference on Computer Vision (ICCV), 2019, pp. 6082-6091
关键点:
- 直推式学习(Transductive Learning)解决零样本物体检测,在直推式学习中,无标签的测试样本是可以参与训练的。直推式学习关注的是如何当前问题,而不作推广。论文中一句话有体现:Transductive ZSD: Predict category labels and object locations for only ‘unseen’ classes present in the set Xts.(你细品~~)
- 自监督(self-learning)调整模型
模型整体框架

- 目标域无标签图片输入Inductive Model产生Fixed Label(1)(2)
- 使用Inductive参数初始化Transductive Model(3)
- 使用初始化后的Transductive Model对目标域数据产生Dynamic Label(4)(5)
- 将Fixed和Dynamic Label输入Transductive Model中,动态迭代Dynamic Label
- 最后得到理想的分类
使用源域有标签数据训练Inductive Model
首先使用源域可见数据训练一个Inductive ZSD模型,这个模型可以完成候选框视觉特征与标签语义特征的对齐,通过sigmoid或者softmax获得分类结果。
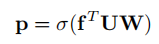
Transductive ZSD
直推式学习既需要迁移源域标注数据中所学的知识,也需学习目标域无标签数据的新知识。为解决两问题,模型分别使用Fixed pseudo-labeling与Dynamic pseudo-labeling完成旧知识的迁移与新知识的学习。
- Fixed Pseudo-labeling
首先使用已完成训练的Inductive Model识别无标签目标域数据中已经训练过的类,将其标记为Fixd Pseudo-labeling。因为Inductive Model已经在有标记的数据上完成训练,所以其检测出的物体具有一定可信度,可被视为真实标签。在整个Tranductive模型训练过程中,Fixed Pseudo-labeling保持不变,并且配合Dynamic pseudo-labeling
计算损失,这样模型可以将源域所学知识稳定迁移到目标域中。 - Dynamic Pseudo-labeling
使用Dynamic Pseudo-labeling主要是为学习目标域新知识,所以其需要动态调整。首先使用Inductive Model的参数初始化Tranductive Model,使用Tranductive Model为目标域中所有数据产生伪标签,数据包括包含已训练完成的类别以及未曾训练的类别。
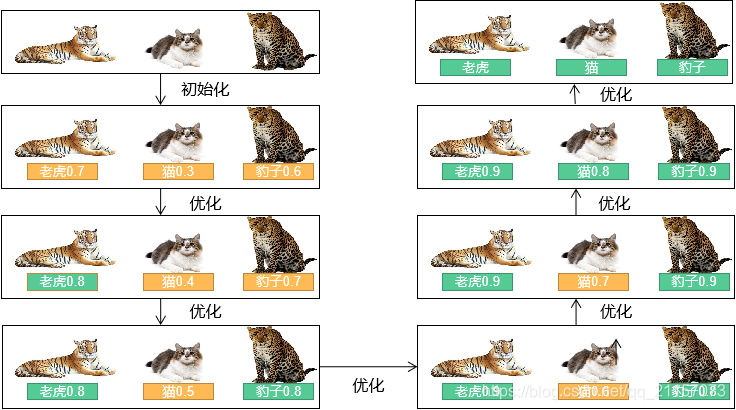
Dynamic Pseudo-labeling的动态调整是个啥过程?
众所周知,如果模型认为候选框属于某个类别概率越高,其分类越准确。对于可见类和不可见类而言,如果模型认为候选框属于某类别的概率超过阈值0.9,那么我们有很大的把握认为模型分类是正确的。即这个候选框可被认定为完成分类,所以在迭代过程中,候选框会产生另一种伪标签:已完成分类/未完成分类。而模型的任务就是使“已完成分类”的伪标签越多越好!如下图:
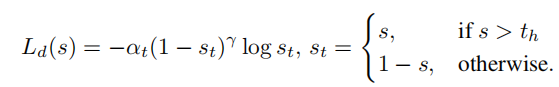

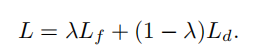
论文:A Multi-Space Approach to Zero-Shot Object Detection
Dikshant Gupta, Aditya Anantharaman, Nehal Mamgain, Sowmya Kamath S, Vineeth N Balasubramanian, C.V. Jawahar; The IEEE Winter Conference on Applications of Computer Vision (WACV), 2020, pp. 1209-1217
关键点:
- 在语义空间中融合视觉特征,在视觉空间中融合语义特征
- 在两种空间中计算相似度,在公共空间中合并
现有Zero-Shot研究,将视觉空间与语义空间相互映射,或将两者映射到公共空间。但是对于不同类别,其在语义空间与视觉空间对应特征所具备的区分性不同。有些类别可能在语义空间很容易区分,有些类别则容易在视觉空间区分,为使用不同类别在两种空间的区分度,本文将不同空间进行对齐,结果进行融合,达到使用不同空间共同预测的效果(并不是在公共空间预测)。
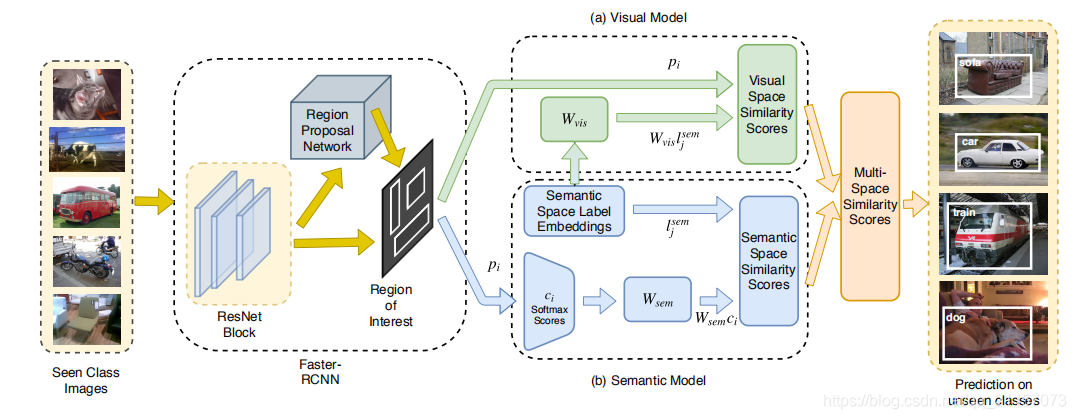
- 首先使用Faster-RCNN框架产生候每个选框特征p,由p获得softmax操作后的scores:c
- 使用Wsem将所得c映射到语义空间中:Wsem × c
- 计算第二步映射后向量与label语义空间向量的相似性
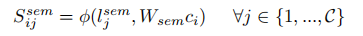
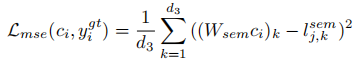
- 与此同时,使用子网络将语义信息映射到视觉空间中
- 计算第五步获得特征与第一步中p的相似度
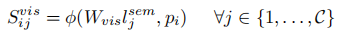
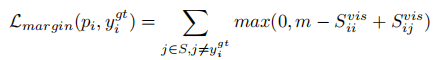
- 随后将语义空间与视觉空间相似性合并,下列两种方式选其一:
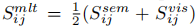
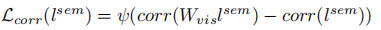
Zero Shot Detection(基于YOLOV2的零样本物体检测)

- 使用Feature-Extraction提取基础特征TF(13,13,1024)
- Object-Localization模块:定位物体,将TF卷积为TL(13,13,5×4)的定位信息,5个候选框,每个四个定位值
- Semantic-Prediction模块:使用语义信息链接seen类和unseen类,具体来说,将TF卷积为TS(13,13,5×64),每个候选框对应一个64维的语义信息
- Confidence Prediction模块:将TF,TL,TS拼接为(13, 13,1024+320+20)的block,使用1×1卷积卷它,最后得到TC(13,13,5),TC表示每个候选框的置信度
损失函数:
回归定位损失:
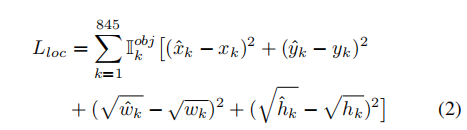
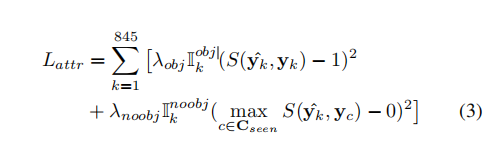
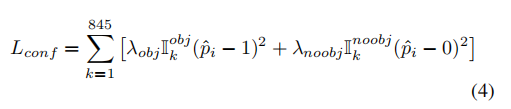
Don’t Even Look Once: Synthesizing Features for Zero-Shot Detection(基于YOLOV2的零样本物体检测)
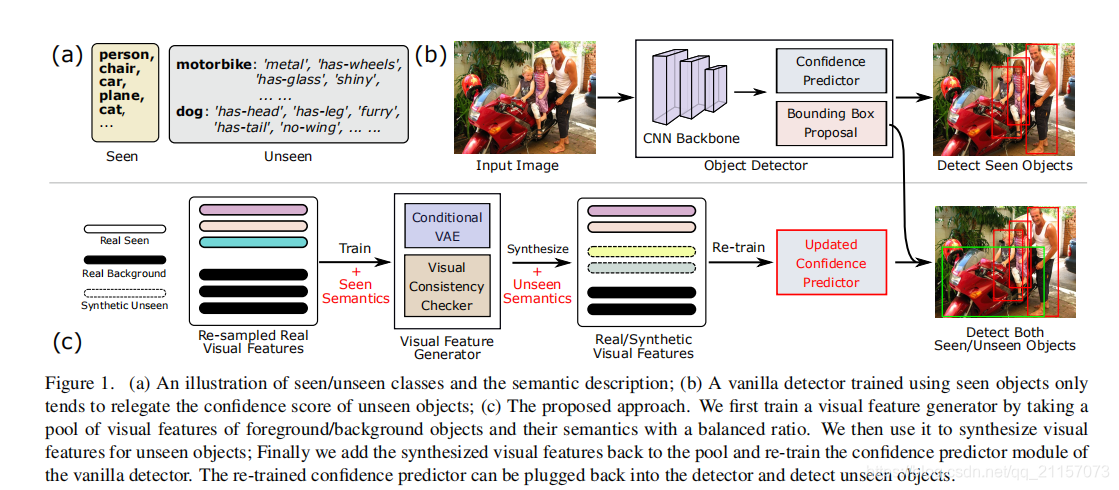
论文认为只要能产生足够好的候选框,即定位物体准确,就可以借助ZSR的工作解决分类问题,所以文章致力于解决如何产生准确的seen+unseen候选框。
网络在只用Seen类别的训练集中训练完成后,已经能够定位出Seen物体并完成分类。但是当面对Unseen物体时,网络会给出较低的置信度,这就导致Unseen类别难以检测。如果Confidence Predictor模块能够给予unseen较高的置信度就可以缓解此问题,所以我们需要将Unseen的特征输入Confidence Predictor模块进行训练,至于如何得到Unseen特征,答案就是使用生成网络,如下:
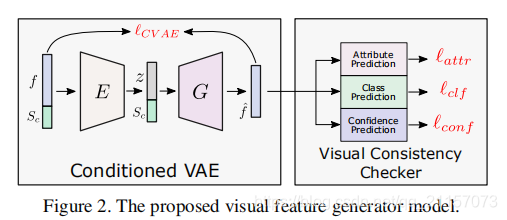
使用Seen类的特征 f 以及语义信息 S 训练CVAE,并通过4个损失函数进行约束,最后得到一个生成器G。其可以根据随机噪声 z 以及语义信息 S 生成视觉特征 f 。所以可以使用G以及Unseen类的语义信息生成Unseen类的视觉特征,并且将生成的Unseen特征以及Seen特征输入到Confidence Predictor中完成训练,最后将Confidence Predictor插入原网络中,完成Unseen类检测。

















 6248
6248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









