







VisualBERT 是一种深度学习模型,专门设计用于处理涉及文本和图像的多模态数据。它是基于 BERT(双向编码器表示从变换器)模型发展而来,旨在通过结合文本和视觉信息来提高对复杂场景的理解能力。
核心理念
跨模态理解:VisualBERT 的主要目标是通过集成文本和图像的数据,实现更深层次的信息理解和交互。这使得模型能够在诸如视觉问答(VQA)、图像描述生成等任务中表现得更加出色。
技术基础
-
BERT 架构:继承了 BERT 的双向变换器架构,VisualBERT 能够有效地捕捉文本中的长距离依赖关系。
-
图像特征提取:为了处理图像数据,VisualBERT 使用预训练的卷积神经网络(如 ResNet)来提取图像特征,并将这些特征与文本信息一同输入模型。
输入处理
-
多模态输入:VisualBERT 将图像分解为多个区域,并为每个区域生成一个特征向量。这些特征向量与文本的词嵌入组合在一起,形成一个多模态的输入序列。
-
统一编码:通过变换器层,VisualBERT 对这个多模态序列进行编码,学习文本和图像之间的相互作用。
训练方法
-
预训练与微调:VisualBERT 首先在一个大型的未标注多模态数据集上进行预训练,以学习通用的多模态表示。之后,通过在特定任务的小规模标注数据上进行微调,进一步优化模型性能。
1 INTRODUCTION
结合视觉和自然语言的任务为评估具有视觉信息的系统推理能力提供了丰富的测试平台。这些任务不仅仅是识别图像中存在的对象(Russakovsky et al., 2015; Lin et al., 2014),还涵盖了更复杂的任务,如描述(Chen et al., 2015)、视觉问题回答(Antol et al., 2015)和视觉推理(Suhr et al., 2019; Zellers et al., 2019)。这些任务要求系统不仅要识别图像中的对象,还要理解图像的广泛详细语义,包括对象、属性、部分、空间关系、动作和意图,以及这些概念是如何在自然语言中被提及和基于图像的。
VisualBERT 概述
在本文中,我们提出了VisualBERT,这是一个简单且灵活的模型,旨在捕捉图像和相关文本中的丰富语义。VisualBERT 整合了以下两个关键技术:
-
BERT (Bidirectional Encoder Representations from Transformers):
-
BERT 是一个基于 Transformer 的自然语言处理模型,由 Devlin 等人在 2019 年提出。
-
它通过双向训练方法有效捕捉文本中的长距离依赖关系,提高了模型在各种 NLP 任务中的性能。
-
-
预训练的目标提议系统:
-
如 Faster-RCNN(Ren et al., 2015),这是一个高效的物体检测模型。
-
它可以从图像中提取目标提议(即可能包含对象的图像区域),并生成相应的特征向量。
-
模型结构
在 VisualBERT 中,从目标提议中提取的图像特征被视为无序的输入标记,并与文本一起输入模型。具体来说:
-
输入处理:
-
文本被编码为词嵌入。
-
图像被分割成多个区域,每个区域通过 Faster-RCNN 提取特征向量。
-
这些图像特征向量和文本词嵌入一起组成一个多模态输入序列。
-
-
联合处理:
-
多个 Transformer 层对这个多模态输入序列进行联合处理。
-
单词和目标提议之间的丰富交互使模型能够捕捉文本和图像之间的复杂关联。
-
关键优势
-
跨模态理解:VisualBERT 能够同时处理文本和图像数据,通过联合训练和多模态输入,模型能够更好地理解图像中的对象及其与文本的关系。
-
灵活性:模型结构简单且灵活,可以轻松适应多种视觉与语言任务,如视觉问答、图像描述生成和视觉推理。
-
高效性:利用预训练的 BERT 和目标提议系统,VisualBERT 在保持高性能的同时,减少了从零开始训练模型所需的时间和资源。
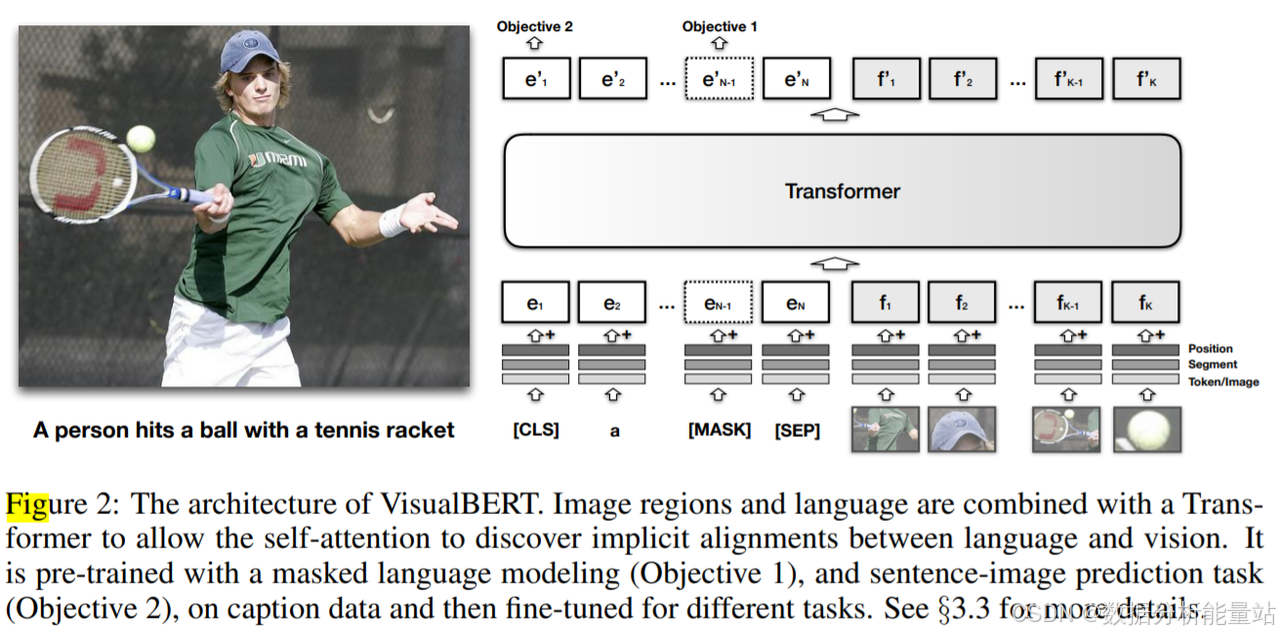
为了使 VisualBERT 学习图像和文本之间的关联,我们提出了两个基于视觉的语言模型预训练目标:
-
掩码语言建模(Masked Language Modeling, MLM):
-
目标:部分文本被随机掩盖,模型需要基于剩余的文本和视觉上下文预测被掩盖的单词。
-
作用:这种任务迫使模型学习如何利用视觉信息来补充文本信息,从而更好地理解图像中的内容。
-
-
图像文本匹配(Image-Text Matching, ITM):
-
目标:模型被训练以确定提供的文本是否与图像匹配。
-
作用:这种任务帮助模型学习图像和文本之间的对齐关系,提高模型在理解图像和文本之间关联方面的能力。
-
数据集
预训练使用的数据集是 COCO 图像描述数据集(Chen et al., 2015),该数据集包含大量带有详细描述的图像。这些描述提供了丰富的文本信息,有助于模型学习图像和文本之间的复杂关系。
下游任务
为了评估预训练 VisualBERT 的效果,我们在四个视觉与语言任务上进行了全面实验:
-
视觉问题回答(VQA 2.0, Goyal et al. (2017)):
-
任务:回答关于给定图像的问题。
-
结果:VisualBERT 表现优异,能够准确理解图像中的内容并回答相关问题。
-
-
视觉常识推理(VCR, Zellers et al. (2019)):
-
任务:根据图像和上下文进行逻辑推理。
-
结果:VisualBERT 在这项任务中表现良好,显示出其在复杂推理任务中的能力。
-
-
自然语言视觉推理(NLVR2, Suhr et al. (2019)):
-
任务:判断给定的自然语言句子是否与一对图像匹配。
-
结果:VisualBERT 在这项任务中取得了很好的成绩,展示了其在多图像推理中的能力。
-
-
区域到短语的接地(Flickr30K, Plummer et al. (2015)):
-
任务:将文本中的短语与图像中的特定区域对齐。
-
结果:VisualBERT 在这项任务中表现优秀,能够准确地将文本与图像中的特定区域对应起来。
-
实验结果
-
性能比较:通过在 COCO 图像描述数据集上预训练,VisualBERT 在上述四个任务中表现优于或与最先进模型相当。
-
消融研究:我们进行了详细的消融研究,验证了预训练目标和模型设计的选择对最终性能的影响。
-
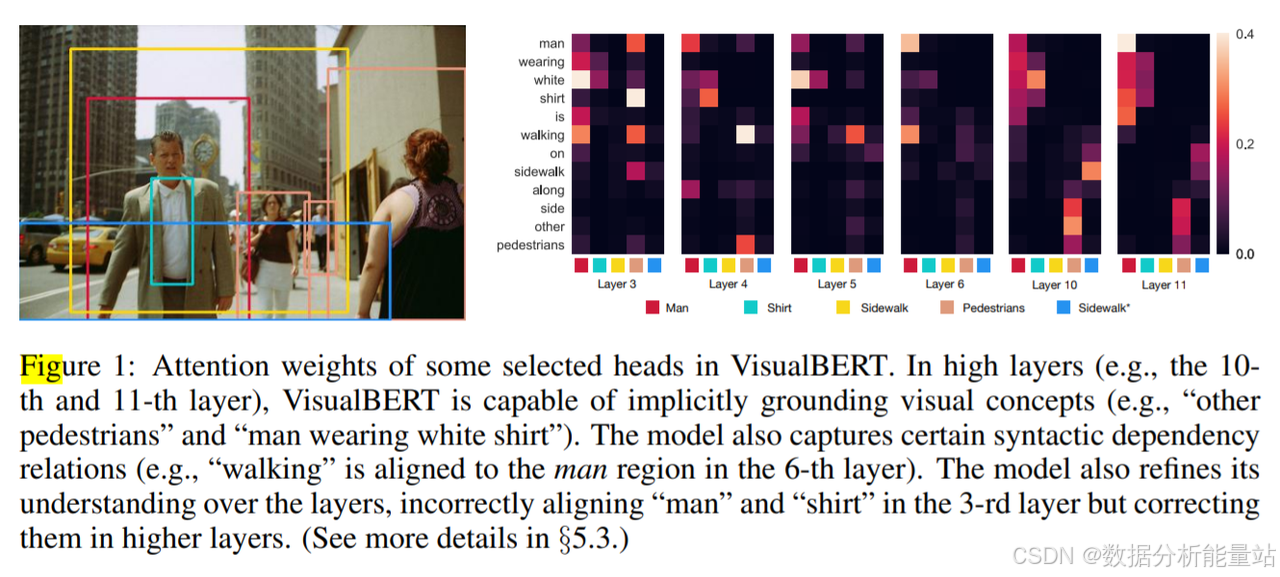
注意力机制分析:进一步的定量和定性分析显示,通过预训练,VisualBERT 学会了如何分配注意力权重,以内部对齐单词和图像区域。模型能够基于图像接地实体,并编码单词和图像区域之间的某些依赖关系,从而提高对图像详细语义的理解。
2 RELATED WORK
连接视觉和语言的研究历史悠久,涉及多个任务和模型。这些任务包括:
视觉问题回答(VQA):文献:Antol et al., 2015; Goyal et al., 2017;任务:回答关于给定图像的问题。
文本接地(Phrase Grounding):文献:Kazemzadeh et al., 2014; Plummer et al., 2015;任务:将文本中的短语与图像中的特定区域对齐。
视觉推理(Visual Reasoning):文献:Suhr et al., 2019; Zellers et al., 2019;任务:根据图像和上下文进行逻辑推理。
模型设计
为了解决上述任务,研究人员开发了多种模型,这些模型通常包括以下几个组件:
-
文本编码器:用于处理文本数据,提取文本特征。
-
图像特征提取器:用于处理图像数据,提取图像特征。常用的提取器包括 Faster-RCNN(Ren et al., 2015)。
-
多模态融合模块:用于将文本和图像特征结合起来,通常包含注意力机制。
-
答案分类器:用于生成最终的答案或输出。
具体模型
Visual Genome:
-
文献:Krishna et al., 2017
-
贡献:提供了详细的图像注释,包括对象、属性和关系,增强了 VQA 系统中的对象检测器(Anderson et al., 2018)。
注意力机制:
-
文献:Santoro et al., 2017; Norcliffe-Brown et al., 2018; Cadene et al., 2019
-
贡献:探索使用注意力模块来建模图像中对象之间的关系。
图模型:
-
文献:Li et al., 2019
-
贡献:明确构建一个图来编码对象关系。
VisualBERT 是一个通用的多模态模型,旨在捕捉图像和文本中的丰富语义。它的设计灵感来源于 BERT(Devlin et al., 2019),一个基于 Transformer 的自然语言处理模型。VisualBERT 的主要特点包括:
-
自注意力机制:作用:允许模型捕捉对象之间的隐式关系。
-
预训练:
-
目标:在图像描述数据上进行预训练,以学习图像和文本之间的关联。
-
任务:
-
掩码语言建模(MLM):部分文本被掩盖,模型学习基于剩余的文本和视觉上下文预测被掩盖的单词。
-
图像文本匹配(ITM):模型被训练以确定提供的文本是否与图像匹配。
-
-
-
通用性和适应性:
-
特点:VisualBERT 是通用的,可以轻松适应新任务或整合到其他特定任务的模型中。
-
相关工作
-
VideoBERT:
-
文献:Sun et al., 2019
-
贡献:将视频转换为与一系列图像配对的口头单词,并应用 Transformer 学习联合表示。
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











