







 本文探讨预训练语言模型在情绪分析中的应用,包括社交媒体和新闻情绪分析,以及BBT大模型在细粒度情绪计算上的进展。通过来源提示法和参数增大,模型在金融文本情绪分析中展现出更强的专业性和准确性。BBT大模型提供了情绪分析API和下游任务评测数据集,以促进金融人工智能的发展。
本文探讨预训练语言模型在情绪分析中的应用,包括社交媒体和新闻情绪分析,以及BBT大模型在细粒度情绪计算上的进展。通过来源提示法和参数增大,模型在金融文本情绪分析中展现出更强的专业性和准确性。BBT大模型提供了情绪分析API和下游任务评测数据集,以促进金融人工智能的发展。
预训练语言模型:
情绪分析的多样化应用场景

情绪分析,是目前预训练语言模型被最为广泛运用在量化投资领域的工具之一。量化投资需要将文本数量化,“情绪”便顺理成章,成为很好的中转媒介。在过往时间里,我们在语言预训练领域,尤其文本数据量化,有着长足的积累,在使用过程中,也发现了许多大家共同关心的问题,本文就不同场景下的情绪分析任务,进行系列的探讨,也期望对“情绪分析”这样一个大家已熟知的人工智能场景产生更深刻的理解。
1.情绪分析API介绍
我们目前已推出了社交媒体语言情绪分析,新闻情绪分析,两种BBT(BigBang Transformer乾元大模型,详情可见往期文章)大模型情绪类下游任务,后期还会推出研究报告情绪分析,公告情绪分析等多项情绪类的API接口。
图1:产品结构
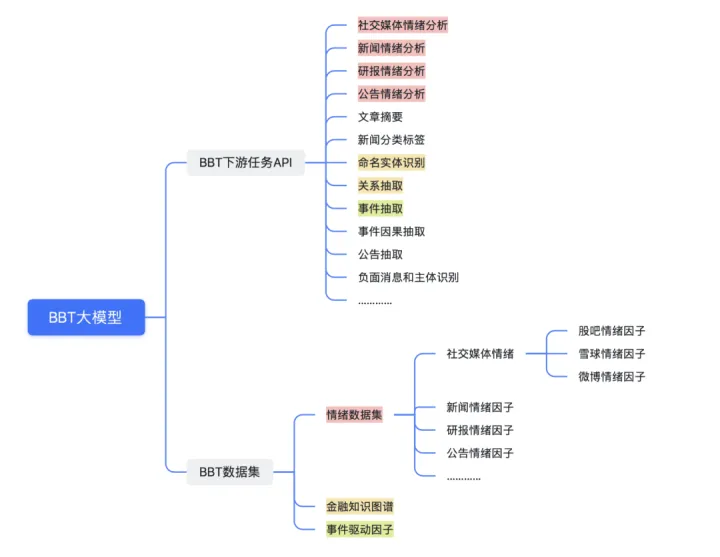
这些接口通过输入的语料来源不同进行区分,以输入为整体进行情绪判断,最长1024个字节输入限制,基本适用各种场景下的文本。
2.细粒度情绪分析(Aspect Based Sentiment Analysis):结合BBT语言大模型的主体识别能力,进行细粒度情绪计算
我们已发布产品的情绪计算默认对文本最主要主体进行情绪判断或不带主体的纯语言内涵情绪判断。我们在研发下游任务的过程中发现,如果以主体+情绪,这样的情绪组为输出会复杂化对情绪分析规则的制定,例如“A公司和B公司合作拿到大笔订单”,那么对于A,B来说 都是利好消息,但如果是“A比B抢先拿到大笔订单”,那么对A来说就是利好,对B就是消极消息,但这两句话文本和描述的事件却非常相似。这仅仅是一些还比较明确的规则,当涉及到例如收购,合并等更复杂的商业事件中,多主体将
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











