







Efficient Semantic Video Segmentation with Per-frame Inference


摘要
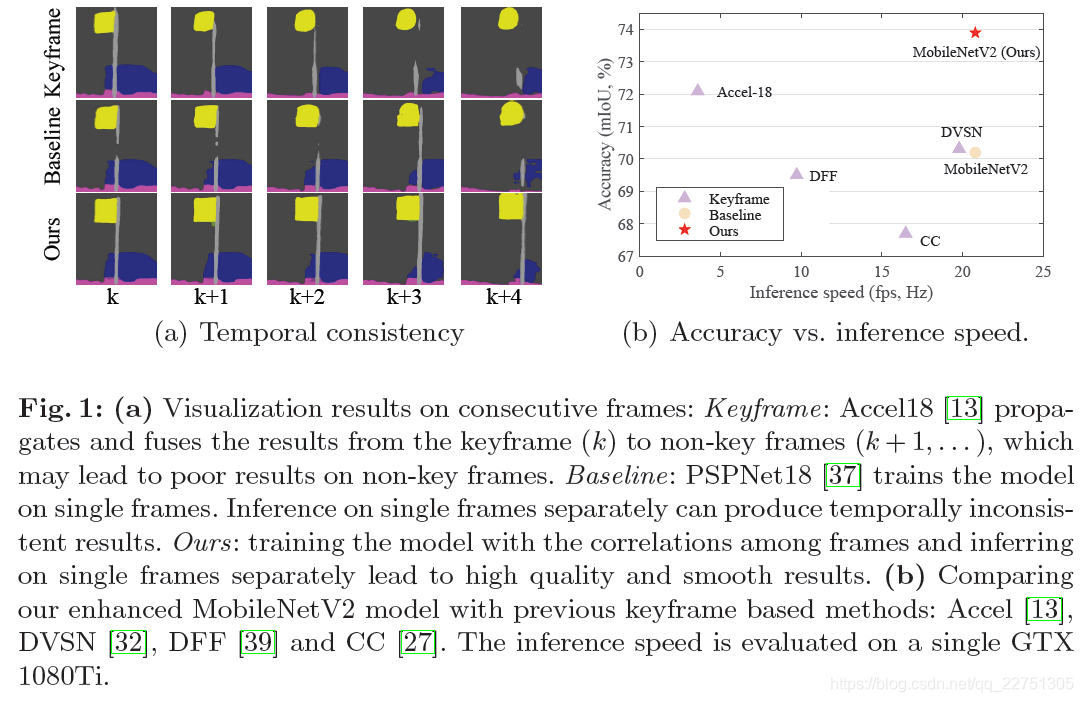
对于语义分割,大多数实时的方法都是在单帧图像上训练的,当在视频上测试时,分割结果可能会产生不一致的结果。少数方法考虑了视频流序列图像的相关性,如通过光流利用相邻帧的分割结果做反向传播,或者利用多帧信息提取图像的特征表达,这些方法可能会导致不好的影响。相反的,我们在训练的过程中,额外用一个约束来考虑帧间时序的一致性,在预测的时候,不会增加任何的计算开销。一个紧凑的模型被用来做实时预测。为了减小紧凑模型与大模型直接的性能差距,提出了一种时序上的知识蒸馏方法。权衡精度、时序一致性和效率,在Cityscapes和Camvid上,我们提出的方法在性能上超越了基于关键帧的方法和对应的基准模型。
论文贡献
- 在不引入后处理和额外计算开销的情况下,可对视频的每一帧图像进行预测,且无延时;
- 提出了一个考虑帧间一致性的损失函数(temporal loss)和一个基于帧间一致性的知识蒸馏方法;
- 实验,在视频语义分割上,取得了state-of-the-art的效果。
方法
主要包括2部分:temporal loss(图b所示),基于时序一致性的知识蒸馏策略(temporal consistency knowledge distillation strategies, 图c和d所示).
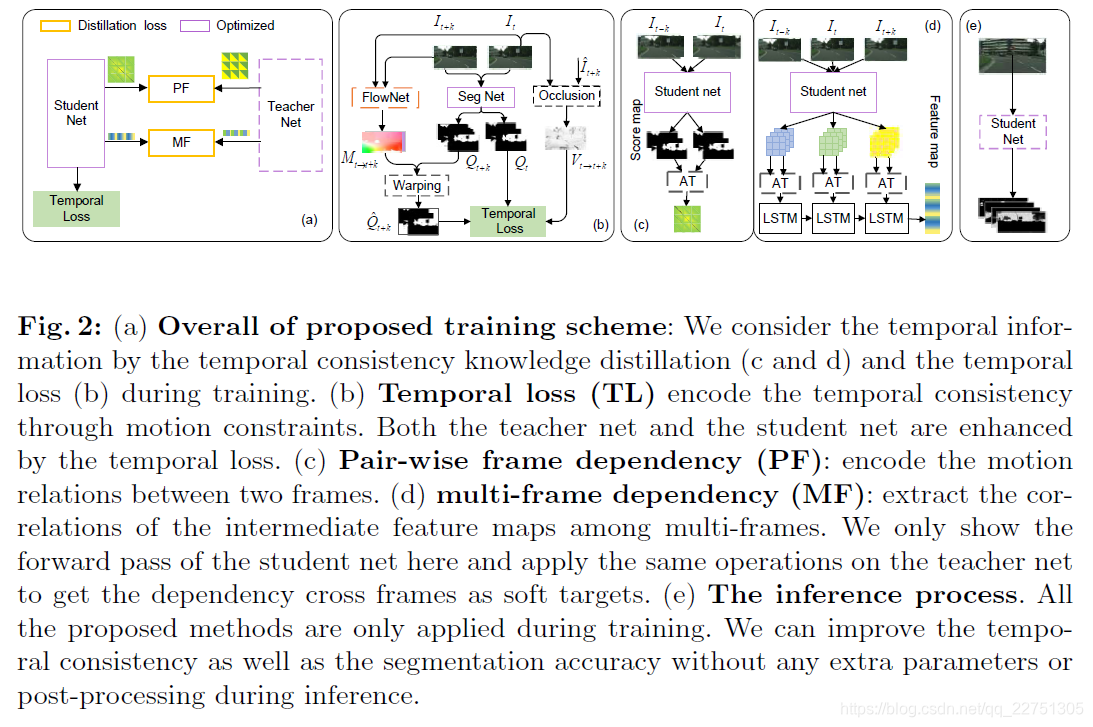
temporal loss(TL)
TL需用到光流信息,简而言之,就是前一帧的预测结果经过光流补偿后,与当前帧的预测结果要一致。,预测光流的模型为FlowNetV2,在训练过程中其权重固定。损失函数表达式如下:
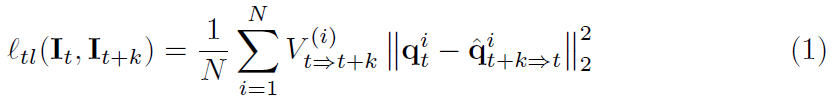
为第t帧图像位置i出的预测结果,
为第t+k帧图像经过光流变换到第t帧时位置i出的预测结果。
为一个occlusion mask,用来移除光流变换产生的误差。
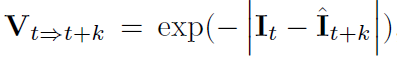
其中,是经过光流变换后的图像。
Temporal Consistency Knowledge Distillation
蒸馏策略用到了一个学生网络S和一个教师网络T,S对应实际预测用到的紧凑网络,T对应训练用到的大网络。T事先用交叉熵损失和TL损失训练好。与基于单帧的蒸馏方法不同之处在于,设计了2种新的知识蒸馏策略:pair-wise-frames dependency(PF)和multi-frame dependency(MF).在实际训练的过程中,T的中间结果和最后输出的logit将作为S对应位置的soft targets。
pair-wise-frames dependency(PF)
如figure 2(c)所示,令为2个输入tensor,
表示X1和X2逐点计算的相似度特征图,相似度采用余弦距离计算,AT为一种self-attention操作,用来计算A。令
为A中的一个像素,
分类为X1和X2中第i和第j行特征,那么
![]()
PF损失函数的定义如下:
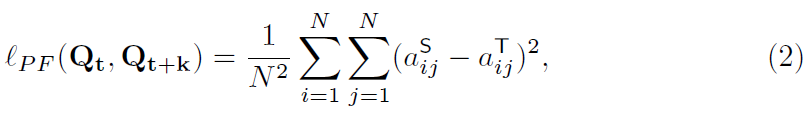
其中,分别表示第t帧和第t+k帧的分割图。
multi-frame dependency(MF)
如图figure 2(d)所示,令视频序列,对应的特征图
。
为捕捉帧间的结构信息和对齐S和T中的特征图,针对每帧都计算自身的相似度特征图(self-similarity map)。我们采用ConvLSTM来将序列的
编码为一个嵌入向量
,
表示E的维度。将前面t-1个时刻的F依次输入ConvLSTM,得到t时刻的嵌入向量
.
令分别表示T和S最后时刻的嵌入向量,那么,MF的损失函数定义如下:
![]()
Optimization
总的损失函数定义如下:
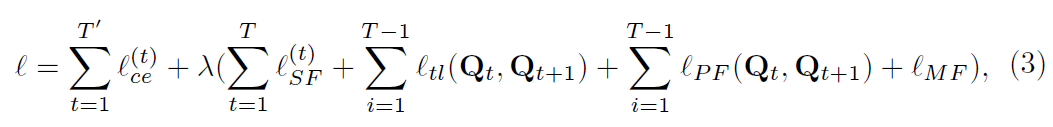
其中,T为所有用于训练的帧数,为带标注的帧数。
为0.1.
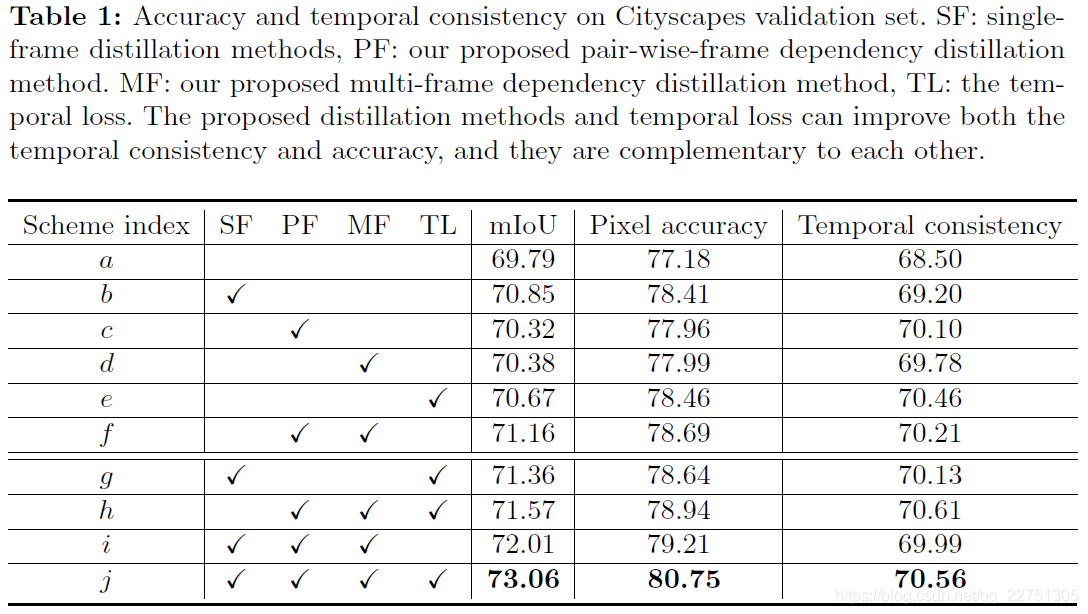
实验结果


















 1862
1862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









