









Eshraghian J K, Ward M, Neftci E O, et al. Training spiking neural networks using lessons from deep learning[J]. Proceedings of the IEEE, 2023.
3.神经编码( The Neural Code)
光是当视网膜将光子转化为脉冲时我们所看到的;气味是当鼻子将挥发分子处理成脉冲时我们所闻到的;触觉感知是当我们的神经末梢将压力转化为脉冲时我们所感受到的。大脑以脉冲作为全球通用货币(global currency of the spike)。如果所有脉冲都被同等对待,那么它们如何传递意义呢?就脉冲编码而言,神经网络中的两个部分必须分别处理(见图7):
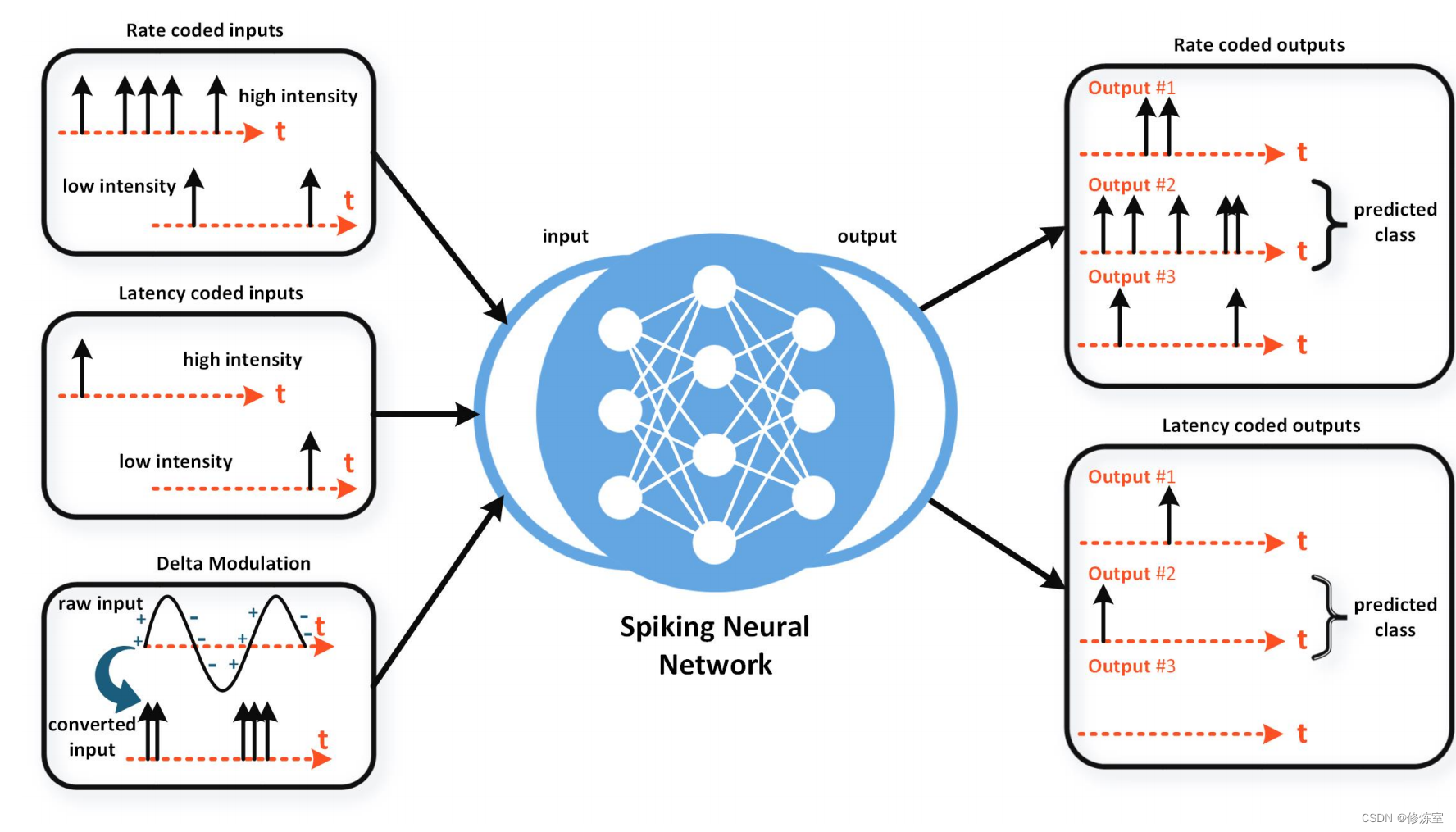
图7:输入数据到SNN可以被转换为发放率、发放时间,或者数据可以进行Δ调制。另外,输入到网络的数据也可以在不转换的情况下传递,这在实验中代表了应用于神经元输入层的直流或可变电流源。网络本身可以被训练以使正确的类别具有最高的发放率或最先发放,还有许多其他编码策略。
- 输入编码:将输入数据转换为脉冲,然后传递给神经网络。
- 输出解码:训练网络的输出以一种有意义且信息丰富的方式产生脉冲。
3.1 输入编码(Input encoding)
输入数据到SNN不一定要被编码成脉冲。将连续值作为输入是可以接受的,就像光的感知始于大量光子撞击我们的光感受器细胞一样。
静态数据,如图像,可以被视为直流(DC)输入,其中相同的特征在每个时间步传递到SNN的输入层。但这并没有充分利用SNN从时间数据中提取含义的方式。一般来说,关于输入数据,有三种编码机制被广泛应用:
- 频率编码(Rate coding) 将输入强度转换为 发放频率 或 脉冲计数 。
- 潜伏期(或时间)编码(Latency coding) 将输入强度转换为脉冲 时间 。
- Δ调制(Delta modulation) 将输入强度的时间 变化 转换为脉冲,否则保持静默。
这是一个非详尽的列表,这些编码方式并不一定彼此独立。
3.1.1 频率编码输入( Rate Coded Inputs)
感觉周围特征是如何将关于世界的信息编码成脉冲的呢?当强光照射到我们的光感受器细胞上时,视网膜会触发一系列脉冲传递到视觉皮层。Hubel和Wiesel关于视觉处理的诺贝尔奖获奖研究表明,更亮的输入或光的有利方向对应于更高的发放率[58]。作为一个基本(rudimentary)的例子,一个明亮的像素被编码为高发放率,而一个黑暗的像素则会导致低频率的发放。测量神经元的发放率可以变得非常微妙(nuanced)。最简单的方法是将输入刺激应用于神经元,计算它产生的总动作电位数,并将其除以试验的持续时间。虽然简单直接,但问题在于 神经元在时间上动态变化 。不能保证试验开始时的发放率与试验结束时的发放率接近。
另一种方法是在非常短的时间间隔∆t内计算脉冲数。对于足够小的∆t,脉冲计数可以限制为0或1,将可能的总结果数量限制为仅为两个。通过多次重复这个实验,可以找到在∆t内发生的脉冲数的平均值(在试验中)。这个平均值必须等于或小于1,被解释为神经元在短时间间隔内发放的 观察概率 。为了将其转换为依赖于时间的发放率,试验平均值被时间间隔的持续时间除以。这种速率编码的概率解释可以分布在多个神经元上,其中从一组神经元中计算脉冲的方法支持一种群体编码。这种表示对于顺序神经网络非常方便。在RNN中,每个离散时间步可以被认为持续一个简短的时间∆t,在这个时间内要么发生脉冲,要么不发生脉冲。关于这是如何实现的正式示例在附录B.1中提供。可以使用snnTorch中的spikegen模块对数据进行速率编码:
from snntorch import spikegen
import torch
steps = 100 # 时间步数
X = torch.rand(10) # 10个随机输入的向量
S = spikegen.rate(X, num_steps=steps) # 以速率编码X
print(X.size()) # 输出X的大小
>> torch.Size([10])
print(S.size()) # 输出S的大小
>> torch.Size([100, 10])
3.1.2 潜伏期编码输入( Latency Coded Inputs)
潜伏期(或时间)编码关注脉冲发生的时机。 脉冲的总数不再重要 。相反,脉冲发生的时间才是重要的。例如,一个首次脉冲时间机制将明亮的像素编码为早期脉冲,而暗输入则最后脉冲,或者根本不脉冲。与频率编码相比,潜伏期编码机制赋予每个单独脉冲更多的含义。
神经元可以对感觉刺激作出非常广泛的动态范围的响应。在视网膜中,神经元可以检测到单个光子到数百万个光子的涌入。为了处理如此广泛变化的刺激,感觉转导系统很可能使用对数依赖性(logarithmic dependency)来压缩刺激强度。因此,在文献中,脉冲时间与输入特征强度之间的对数关系是无处不在的。
虽然感觉通路似乎将速率编码的脉冲列传输到我们的大脑,但实际上大脑内部进行的处理可能主要是时间编码。详细内容请参见第3.2.3节。
from snntorch import spikegen
import torch
steps = 100 # 时间步数
X = torch.rand(10) # 10个随机输入的向量
S = spikegen.latency(X, num_steps=steps) # 以潜伏期编码X
print(X.size()) # 输出X的大小
>> torch.Size([10])
print(S.size()) # 输出S的大小
>> torch.Size([100, 10])
3.1.3 Δ调制输入(Delta Modulated Inputs)
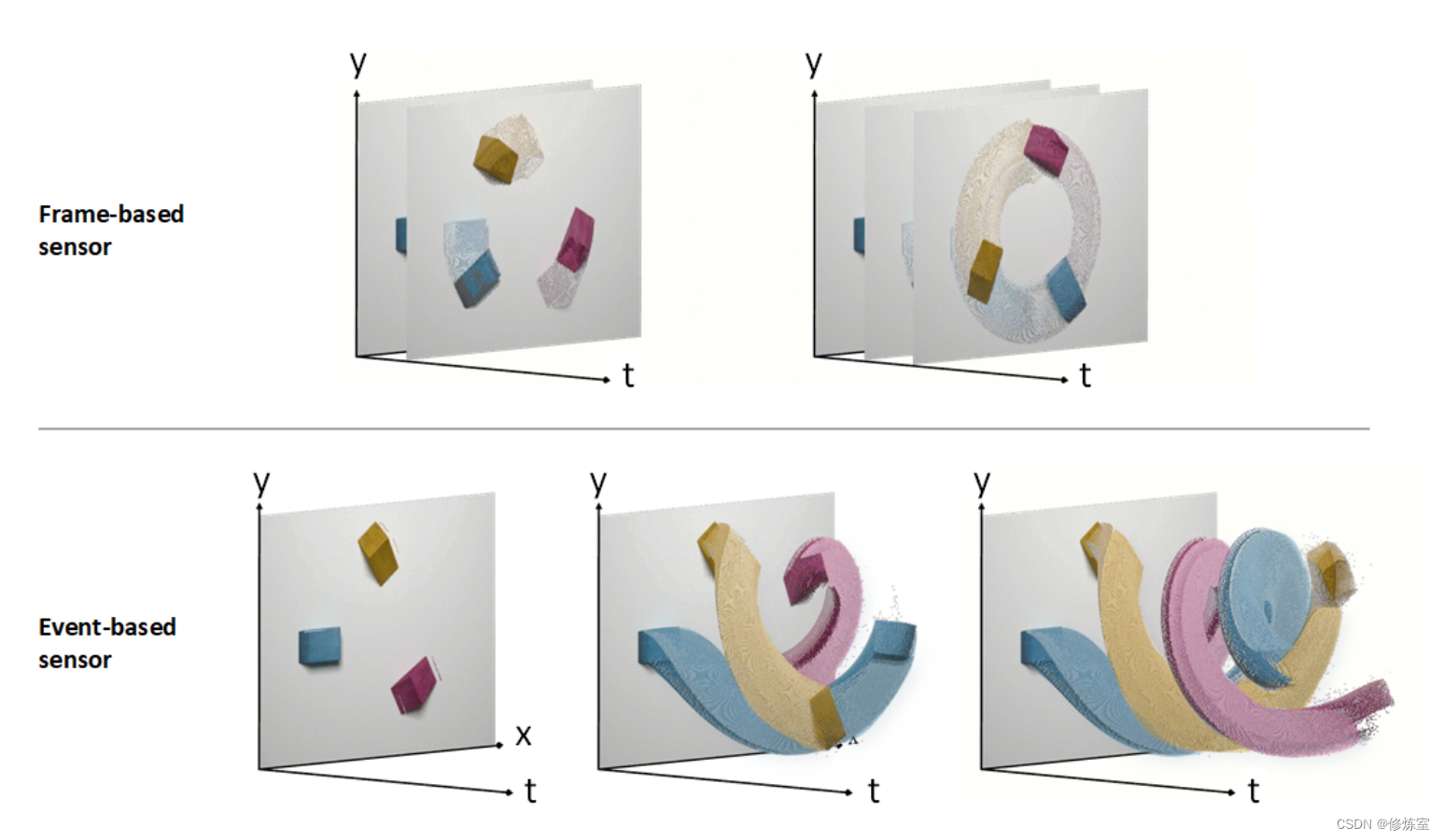
Δ调制基于神经元对变化的需求,这是硅视网膜摄像头运作的基础原理,该摄像头只在一段时间内输入强度发生足够的变化时才生成输入。如果你的视野没有变化,那么你的光感受器细胞就不太容易发放(firing)。在计算上,这将对时间序列输入进行处理,并将阈值矩阵的差异馈送到网络中。虽然具体的实现可能有所不同,但一个常见的方法要求差异既为正,又大于某个预定义的阈值才会生成脉冲。这种编码技术也称为“阈值越过”(‘threshold crossing’)。另外,强度的变化可以在多个时间步中跟踪,并且其他方法考虑了负变化。有关说明,请参见图4,其中“背景”在一段时间内没有被捕获。只有移动的块被记录下来,因为这些像素正在变化。
假设变量 X 存储了一个批量的视频,每个样本有 100 帧,可以使用 spikegen 模块应用 Δ 调制:
from snntorch import spikegen
import torch
print(X.size()) # 输出 X 的大小
>> torch.Size([100, 128, 1, 28, 28]) # 时间,X 批量大小,X 通道,X x-维度, X y-维度
S = spikegen.delta(X, num_steps=steps) # 将 X 转换为 Δ 调制的脉冲存储在 S 中
print(S.size()) # 输出 S 的大小
>> torch.Size([100, 128, 1, 28, 28]) # 大小不变,只有元素有变化
前面的技术倾向于将数据转换为脉冲。但更高效的方法是以“预编码”的形式直接捕获数据。DVS 相机中的每个像素和硅耳蜗中的每个通道都使用 Δ 调制来记录视觉或音频场景中的变化。神经形态学基准数据集的一些示例在表1中描述。NeuroBench 中描述了一系列与神经形态学相关的数据集。
表 1:使用基于事件的摄像机和耳蜗模型记录的神经形态数据集示例。
| 视觉数据集 | 描述 |
|---|---|
| ASL-DVS | 使用 DAVIS 摄像头记录的美国手语的 100,800 个样本。 |
| DAVIS Dataset | 包括室内和室外场景的脉冲、帧和惯性测量单元记录。 |
| DVS Gestures | 在 3 种不同的光照条件下记录的 11 种不同手势。 |
| DVS Benchmark | 用于目标跟踪、动作识别和物体识别的 DVS 基准数据集。 |
| MVSEC | 室内和室外场景的立体摄像头的脉冲、帧和光流。 |
| N-MNIST | 使用扫视运动从屏幕上转换数字的经典 MNIST 数据集的脉冲版本。 |
| POKER DVS | 在 DVS 前快速翻转的 4 种类别的扑克牌。 |
| DSEC | 用于驾驶场景的立体事件摄像头数据集。 |
| 音频数据集 | 描述 |
|---|---|
| N-TIDIGITS | 从 TIDIGITS 数据集中转换为脉冲的语音记录,使用硅耳道模型。 |
| SHD | 使用模拟耳道模型转换的海德堡数字数据集的脉冲版本。 |
| SSC | 使用模拟耳道模型转换的语音命令数据集的脉冲版本。 |
实用提示:输入编码
如果你从一个非脉冲数据集开始,应用这些输入编码机制几乎总会导致准确性/性能下降。信息损失是肯定的。通常更明智的做法是应用文献中普遍存在的预处理技术;例如,如果你有 EEG 数据, 傅立叶变换 通常是合适的。另外,SpikeGPT 引入了二进制嵌入,可以‘学习’一系列输入标记的最佳脉冲编码方式。如果你必须将数据编码成脉冲,我们发现 速率编码 对准确性/损失最小化的影响要小于延迟编码。在理想情况下,你的传感器应该自然地将数据捕获为脉冲,而不必经过转换和压缩步骤。
3.2 输出编码(Output Decoding)
将输入数据编码成脉冲可以被视为感觉周边如何向大脑传递信号。另一方面,解码这些脉冲可以揭示大脑如何处理这些编码信号。在训练 SNN 的背景下,编码机制不会限制解码机制。将我们的注意力从 SNN 的输入转移到输出神经元的发放行为,我们如何解释输出神经元的发放行为呢?
- 速率编码(Rate coding) 选择具有最高 发放率(firing rate) 或 脉冲计数(spike count) 的输出神经元作为预测类别。
- 延迟(或时间)编码 (Latency (or temporal) coding)选择 最先 发放脉冲的输出神经元作为预测类别。
- 总体编码(Population coding) 对每个类别应用上述编码方案(通常是速率编码)与 多个神经元 。
3.2.1 速率编码的输出(Rate Coded Outputs)
考虑一个多类别分类问题,其中 N C N_C NC 是类别数。一个非脉冲神经网络会选择具有最大输出激活的神经元作为预测类别。对于速率编码的脉冲网络,使用发放频率最高的神经元。由于每个神经元都被模拟相同数量的时间步长,因此只需选择 发放脉冲次数最多 的神经元。
3.2.2 潜伏期编码的输出(Latency Coded Outputs)
神经元可能以多种方式将数据编码为脉冲的时间。与编码输入时的情况类似,表示正确类别的神经元可能会 首先发放脉冲 。这解决了速率编码中需要多次脉冲的能量负担问题。在硬件上,需要更少的脉冲减少了内存访问的频率,这是深度学习加速器中的另一个计算负担。
从生物学上讲,神经元按照首次发放脉冲的原则运行是否有意义?如果我们的大脑没有不断重置到某种初始状态,我们如何定义“首次”?从概念上讲,这是相当容易解决的。潜伏期或时间编码的概念源于我们对突然输入刺激的反应。例如,当观察静态、不变的视觉场景时,视网膜会经历快速但微妙的眼球运动。投射到视网膜上的场景每隔几百毫秒就会改变一次。很可能,第一个脉冲必须与这种眼球运动产生的参考信号相对应。
3.2.3 速率编码 vs. 潜伏期编码
神经元是将信息编码为速率、潜伏期或其他形式的话题存在很大争议。我们在这里并不试图破译神经编码,而是旨在提供有关何时SNN可能从一种编码中获益而不是另一种编码的直觉。
速率编码的优势(Rate Codes)
- 容错性(Error tolerance):如果一个神经元没有发放脉冲,理想情况下会有更多的脉冲来减轻这种错误的负担。
- 更多的脉冲促进更多的学习(More spiking promotes more learning):额外的脉冲为通过误差反向传播进行学习提供更强的梯度信号。正如将在第4节中描述的那样,缺乏脉冲可能会妨碍学习收敛(更常被称为“死神经元问题”)。
潜伏期编码的优势(Latency Codes)
- 能耗(Power consumption):生成和传输更少的脉冲意味着在定制硬件中动态功耗的减少。由于稀疏性,它还降低了内存访问频率,因为对于全零输入向量的向量-矩阵乘积会返回零输出。
- 速度(Speed):人类的反应时间大约在 250 ms 左右。如果人脑中神经元的平均发放率约为10Hz(这很可能是一个高估),那么在这个反应时间窗口内只能处理大约2-3个脉冲。相比之下,潜伏期编码依赖于一个脉冲来表示信息。速率编码的这个问题可以通过与种群编码相结合来解决:如果一个单独的神经元在一个短暂的时间窗口内的脉冲数量有限,那么就使用更多的神经元。这会进一步加剧速率编码的能耗问题。
潜伏期编码的能耗优势也得到了生物学观察的支持,自然会优化效率。Olshausen和Field在“‘What is the other 85% of V1 doing?’”一文中系统地证明,速率编码最多只能解释初级视皮层(V1)中15%的神经元的活动。如果我们的神经元不加区别地默认为速率编码,那么这将消耗比时间编码(temporal code)高一个数量级的能量。我们的皮层神经元的平均发放率必然是相当低的,这得到了时间编码(temporal code)的支持。
在基于梯度的SNN中,较少探讨的编码机制包括使用脉冲来表示预测或重建误差。大脑可以被视为一台根据其预测采取行动的预期机器。当这些预测与现实不符时,会触发脉冲来更新系统。
有人声称真正的编码方式必须介于速率编码和时间编码之间[109],而其他人则认为这两者可以共存,只是根据观察的时间尺度不同而已:速率是针对长时间尺度观察的,而延迟是针对短时间尺度观察的[110]。一些人完全否定了速率编码[111]。这是深度学习从业者可能对大脑的运作方式不太关心,而更喜欢专注于什么是最有用的领域之一。
[109] Shigeru Shinomoto and Shinsuke Koyama. A solution to the controversy between rate and temporal coding.Statistics in Medicine, 26(21):4032–4038, 2007.
[110] MR Mehta, AK Lee, and MA Wilson. Role of experience and oscillations in transforming a rate code into a temporal code. Nature, 417(6890):741–746, 2002.
[111] Romain Brette. Philosophy of the spike: Rate-based vs. spike-based theories of the brain. Frontiers in Syst.Neuroscience, 9:151, 2015.
总结
问题二:脉冲神经网络中编码方式是怎样的?
在脉冲神经网路中,常见的编码方式包括:
- 速率编码(Rate Coding):将输入强度转换为神经元的
发送速率或者脉冲计数。例如在亮度较高的输入会导致神经元以更高的频率发送脉冲,而较暗的输入则会导致较低频率的脉冲发放。 - 延迟编码(Latency Coding):将输入强度转换为脉冲发放的
时间,即 脉冲的延迟时间 。例如,亮度较高的输入可能会导致神经元最先发放脉冲,而较暗的输入则可能最后发送脉冲,或者根本不发送脉冲 - 增量调制(Delta Modulation):将输入强度的变化转换为脉冲信号。只有输入的强度变化超过预定义的阈值时,才会发送脉冲。这种编码方式类似于对变化敏感,只有输入发生变化时才会有脉冲发放。
编码方式可以根据不同的需求和任务选择,每种编码方式都有其优势和使用场景。
问题三:输入强度是什么?
输入强度可以指输入数据的某种特征或属性,具体取决于所处理的问题和数据类型。在视觉领域中,输入强度可能表示像素的亮度;在声音领域中,可能表示声音的振幅或频率等。在脉冲神经网络中,输入强度通常是指需要转换为脉冲信号的输入数据的某种特征值
问题四:编码方式的优势和使用场景是什么?
速率编码(Rate Coding)
优势
1、容错性高。即使某个神经元未能发送脉冲,任然还有许多其他的脉冲可以减轻这种错误的影响
2、此外更多的脉冲可以提供更强的梯度信号,有助于学习的过程
使用场景
适用于需要考虑 长时间尺度 的任务,例如需要对输入数据进行积累和平滑处理的情况。
关于“使用场景:适用于需要考虑长时间尺度的任务,例如需要对输入数据进行积累和平滑处理的情况”,一个具体的例子是 视觉对象识别 。在这种情况下,输入数据可能是连续的视频流,需要在一定时间窗口内积累和处理信息以识别对象。通过使用
速率编码,可以对输入数据进行累积处理,并在长时间尺度上获得关于对象的信息。
延迟编码(Latency Coding)
优势
1、节省能源。由于生成和传输的脉冲数量较少,因此在专门的硬件中会导致较少的动态功耗。
2、此外,由于脉冲的稀疏性,内存访问频率也会降低
使用场景
使用与需要 快速响应和处理 的任务,例如需要在短时间串口内进行决策和响应的情况。
增量调制(Delta Modulation)
优势
1、对变化敏感,仅在输入发生变化时才会有脉冲发放,节省了冗余信息的传输和处理
使用场景
适用于需要关注数据变化的任务,例如需要识别和响应动态变化的模型或事件的情况。
问题五:未能发送脉冲可能有哪些情况?
未能发送脉冲可能的情况包括
- 神经元的阈值尚未达到
- 神经元处于绝不应期(神经元在发送脉冲后一段时间内无法再次发送脉冲的时间段)
- 神经元受到抑制性信号

















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









