







神经编码方式
Rate Coded Input Conversion(速率编码输入转换)
概念
速率编码实际上就是用概率来表示 脉冲发生的频率 。输入信号的强度(像素值)越大,表示在每个时间步长上发生脉冲的
概率越高。
Rate Coding 是一种将输入特征转换为脉冲序列的编码方式。在这种编码方式下,脉冲的发放频率与输入特征的强度成正比。也就是说,输入特征越强,神经元发放脉冲的频率就越高。
B.1 速率编码输入转换
以下是将输入样本转换为速率编码脉冲序列的示例。设
X
∈
R
m
×
n
X \in \mathbb{R}^{m \times n}
X∈Rm×n 是MNIST数据集中的一个样本,其中
m
=
n
=
28
m = n = 28
m=n=28 。我们希望将
X
X
X 转换为一个速率编码的三维张量
R
∈
R
m
×
n
×
t
R \in \mathbb{R}^{m \times n \times t}
R∈Rm×n×t,其中
t
t
t 是时间步数。原始样本
X
i
j
X_{ij}
Xij 的每个特征 单独编码 ,归一化后的像素强度(在0到1之间)表示在任意给定时间步长上发生脉冲的概率。这可以视为一次伯努利试验,这是二项分布的特例
R
i
j
k
∼
B
(
n
,
p
)
R_{ijk} \sim B(n, p)
Rijk∼B(n,p),其中试验次数
n
=
1
n = 1
n=1,成功(脉冲)的概率
p
=
X
i
j
p = X_{ij}
p=Xij。明确地说,发生脉冲的概率为:
P ( R i j k = 1 ) = X i j = 1 − P ( R i j k = 0 ) (23) P(R_{ijk} = 1) = X_{ij} = 1 - P(R_{ijk} = 0) \tag{23} P(Rijk=1)=Xij=1−P(Rijk=0)(23)
对每个时间步长的每个特征从伯努利分布中抽样,将用1和0填充三维张量
R
R
R。对于一个MNIST图像,一个纯白像素
X
i
j
=
1
X_{ij} = 1
Xij=1 对应100%的脉冲概率。一个纯黑像素
X
i
j
=
0
X_{ij} = 0
Xij=0 则永远不会产生脉冲。值为
(
X
i
j
=
0.5
(X_{ij} = 0.5
(Xij=0.5 的灰色像素则有相等的概率采样到‘1’或‘0’。随着时间步数
t
→
∞
t \rightarrow \infty
t→∞ ,脉冲比例预计会趋近于 0.5。
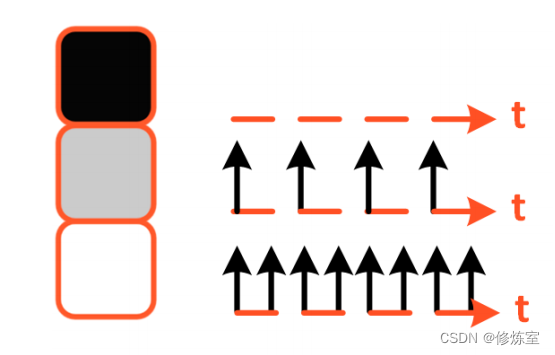
图S.2:速率编码输入像素。输入像素强度越大,对应的发放速率越高。
转换过程
-
输入样本:假设我们有一个来自 MNIST 数据集的输入样本 X ∈ R m × n X \in \mathbb{R}^{m \times n} X∈Rm×n ,其中 m = n = 28 m = n = 28 m=n=28 。
-
生成脉冲序列:我们希望将 X X X 转换为一个三维张量 R ∈ R m × n × t R \in \mathbb{R}^{m \times n \times t} R∈Rm×n×t ,其中 t t t 是时间步的数量。原始样本的每个特征 X i j X_{ij} Xij 都会单独编码。
-
伯努利试验:每个特征的归一化像素强度(介于 0 和 1 之间)代表在任何给定时间步中脉冲发生的概率。这可以看作是一次伯努利试验,其中成功(即发放脉冲)的概率是 p = X i j p = X_{ij} p=Xij。
-
概率公式:
P ( R i j k = 1 ) = X i j = 1 − P ( R i j k = 0 ) P(R_{ijk} = 1) = X_{ij} = 1 - P(R_{ijk} = 0) P(Rijk=1)=Xij=1−P(Rijk=0) -
样本生成:在每个时间步对每个特征进行伯努利试验,生成一个 0 或 1 的值,从而填充三维张量 R R R 的对应位置。
-
图示:下图展示了不同像素强度对应的发放频率。纯白像素(值为 1)对应 100% 的发放概率,纯黑像素(值为 0)对应 0% 的发放概率,灰色像素(值为 0.5)有 50% 的发放概率。
1. 为什么说是发生脉冲的概率?如何理解?
在脉冲神经网络(SNN)中,神经元通过脉冲(或“尖峰”)进行通信。每个脉冲表示神经元的激活,传递信息。速率编码是一种将输入数据转换为脉冲序列的方式,其中输入值的大小决定了脉冲发生的概率。
具体来说,输入样本
X
i
j
X_{ij}
Xij 的每个像素值都被归一化为0到1之间的值。这归一化的像素值可以理解为 在每个时间步长上发生脉冲的概率 。例如:
- 如果 X i j = 1 X_{ij} = 1 Xij=1,表示该像素在每个时间步长上都有100%的概率产生脉冲。
- 如果 X i j = 0.5 X_{ij} = 0.5 Xij=0.5,表示该像素在每个时间步长上有50%的概率产生脉冲。
- 如果 X i j = 0 X_{ij} = 0 Xij=0,表示该像素在每个时间步长上没有脉冲。
假设我们有一个像素值0.75,表示这个像素在每个时间步长有75%的概率产生一个脉冲。你可以想象每秒钟这个像素发出脉冲的频率很高,但不是每次都发。每次我们在时间步长上随机决定是否发出脉冲,75%的时候会发,25%的时候不会发。
归一化的像素值是什么?
在MNIST数据集中,每个图像都是由28x28的像素组成。每个像素的值介于0到255之间,表示不同的灰度等级。为了方便处理,我们通常会把这些值缩放到0到1之间,这就是归一化。例如,像素值255(纯白)变成1,像素值0(纯黑)变成0,像素值128(灰色)变成0.5。
2. 为什么可以视为一次伯努利试验,伯努利试验是什么?又为什么是二项分布的特例?
伯努利试验是指只有两种可能结果的随机试验,通常称为“成功”和“失败”。在我们的例子中,“成功”表示发生脉冲(记为1),“失败”表示不发生脉冲(记为0)。
伯努利试验的数学定义如下:
- 设 (X) 是一个随机变量,表示一次试验的结果。
- (X) 取值1的概率为 (p),取值0的概率为 (1 - p)。
因此,伯努利随机变量 (X) 的概率分布是:
P
(
X
=
1
)
=
p
P(X = 1) = p
P(X=1)=p
P
(
X
=
0
)
=
1
−
p
P(X = 0) = 1 - p
P(X=0)=1−p
在速率编码中,每个像素值 X i j X_{ij} Xij 被视为在每个时间步长上进行一次伯努利试验,成功的概率 p = X i j p = X_{ij} p=Xij。
二项分布是由 (n) 次独立的伯努利试验的结果组成的分布。每次试验都有成功的概率 (p),失败的概率 (1 - p)。
二项分布的数学定义如下:
- 设 (Y) 是一个随机变量,表示 (n) 次独立的伯努利试验中成功的次数。
- (Y) 的概率分布是:
P ( Y = k ) = ( n k ) p k ( 1 − p ) n − k P(Y = k) = \binom{n}{k} p^k (1 - p)^{n - k} P(Y=k)=(kn)pk(1−p)n−k
其中 ( n k ) \binom{n}{k} (kn) 是组合数,表示从 (n) 次试验中选取 (k) 次成功的方式数。
在速率编码中,每个时间步长上我们进行一次伯努利试验,这意味着每个像素的脉冲生成可以视为 (n = 1) 的二项分布。因为 (n = 1),二项分布就退化为伯努利分布。
数学推导
单个时间步的脉冲生成
在单个时间步 k k k 上,位置 ( i , j ) (i, j) (i,j) 的脉冲状态 R i j k R_{ijk} Rijk 是一个伯努利随机变量。这意味着:
- R i j k = 1 R_{ijk} = 1 Rijk=1 表示在该时间步上有脉冲发生,其概率为 p = X i j p = X_{ij} p=Xij。
- R i j k = 0 R_{ijk} = 0 Rijk=0 表示在该时间步上没有脉冲发生,其概率为 1 − p = 1 − X i j 1 - p = 1 - X_{ij} 1−p=1−Xij。
数学表示为:
P
(
R
i
j
k
=
1
)
=
p
=
X
i
j
P(R_{ijk} = 1) = p = X_{ij}
P(Rijk=1)=p=Xij
P
(
R
i
j
k
=
0
)
=
1
−
p
=
1
−
X
i
j
P(R_{ijk} = 0) = 1 - p = 1 - X_{ij}
P(Rijk=0)=1−p=1−Xij
多个时间步的脉冲生成
当我们考虑多个时间步时,每个时间步的脉冲状态仍然是独立的伯努利试验。
假设我们有
t
t
t 个时间步,那么在这
t
t
t 个时间步内,每个时间步上都会进行一次伯努利试验。这
t
t
t 个时间步内位置
(
i
,
j
)
(i, j)
(i,j) 的脉冲发生次数可以表示为:
∑
k
=
1
t
R
i
j
k
\sum_{k=1}^{t} R_{ijk}
k=1∑tRijk
平均脉冲发生概率
为了理解随着时间步数 (t) 的增加,脉冲发生次数的行为,我们来看平均脉冲发生次数:
1 t ∑ k = 1 t R i j k \frac{1}{t} \sum_{k=1}^{t} R_{ijk} t1k=1∑tRijk
根据大数定律(Law of Large Numbers),随着 t t t 增加,这个平均值会趋近于单个伯努利试验的成功概率 (p),即:
lim t → ∞ 1 t ∑ k = 1 t R i j k = p = X i j \lim_{t \to \infty} \frac{1}{t} \sum_{k=1}^{t} R_{ijk} = p = X_{ij} t→∞limt1k=1∑tRijk=p=Xij
概率编码的本质
-
速率编码(Rate Code):
速率编码实际上就是用概率来表示 脉冲发生的频率 。输入信号的强度(像素值)越大,表示在每个时间步长上发生脉冲的概率越高。 -
输入强度和脉冲数量的关系:
- 输入强度越大(例如像素值越高),对应的在每个时间步长上发生脉冲的 概率越高 。这意味着在给定的一段时间内,总的脉冲数量也会更多。
- 反之,输入强度越小(例如像素值越低),在每个时间步长上发生脉冲的概率越低,总的脉冲数量也会更少。
这种方法通过使用概率来模拟脉冲神经网络中的脉冲发放,使得输入信号强度与神经元发放脉冲的频率成正比,直观地反映出输入信号的大小。
Latency Coded Input Conversion(延迟编码输入转换)
概念
Latency Coding 是另一种编码方式,其中脉冲发放的时间与输入特征的强度相关。输入特征越强,脉冲发放的时间越早。
B.2 延迟编码输入转换
U
(
t
)
=
I
i
n
R
+
[
U
0
−
I
i
n
R
]
e
−
t
τ
(
2
)
U(t) = I_{in}R + \left[ U_0 - I_{in}R \right] e^{- \frac{t}{\tau}} (2)
U(t)=IinR+[U0−IinR]e−τt(2)
使用RC电路模型可以推导出输入特征强度与脉冲时间之间的对数关系。从输入电流对膜电位的通解(方程(2))开始,并将初始条件
U
0
=
0
U_0 = 0
U0=0 置零,我们得到:
U ( t ) = I in R ( 1 − e − t τ ) (24) U(t) = I_{\text{in}}R \left(1 - e^{-\frac{t}{\tau}}\right) \tag{24} U(t)=IinR(1−e−τt)(24)
推导过程
我们从电路模型的基本公式开始:
-
电路模型公式:
膜电位 (U(t)) 随时间的变化可以表示为:
U ( t ) = I in R ( 1 − e − t τ ) U(t) = I_{\text{in}}R \left(1 - e^{-\frac{t}{\tau}}\right) U(t)=IinR(1−e−τt)
这里:
- I in I_{\text{in}} Iin 是输入电流。
- R R R 是电阻。
- τ \tau τ 是时间常数,通常表示为 τ = R C \tau = RC τ=RC,其中 C C C 是电容。
- e e e 是自然对数的底数(约等于2.71828)。
-
设置阈值条件:
假设当膜电位达到阈值 θ \theta θ 时神经元发出脉冲,我们需要找到使 U ( t ) = θ U(t) = \theta U(t)=θ 的时间 t t t。
设 U ( t ) = θ U(t) = \theta U(t)=θ,代入电路模型公式:
θ = I in R ( 1 − e − t τ ) \theta = I_{\text{in}}R \left(1 - e^{-\frac{t}{\tau}}\right) θ=IinR(1−e−τt)
计算 U ( t ) = θ U(t) = \theta U(t)=θ 时间的目的
在脉冲神经网络中,神经元的工作原理可以用电路模型来描述。当电流输入神经元时,它会使膜电位(电压)逐渐上升。当膜电位达到某个阈值 θ \theta θ 时,神经元会发出一个脉冲(或尖峰)。因此,我们需要计算从电流开始输入到膜电位达到阈值 θ \theta θ 所需的时间 $t,这样我们就能知道脉冲何时发生。
-
解方程:
我们需要解这个方程以找到 t t t。首先,把方程变形以便于求解 t t t:
θ = I in R ( 1 − e − t τ ) \theta = I_{\text{in}}R \left(1 - e^{-\frac{t}{\tau}}\right) θ=IinR(1−e−τt)
两边同时除以 I in R I_{\text{in}}R IinR:
θ I in R = 1 − e − t τ \frac{\theta}{I_{\text{in}}R} = 1 - e^{-\frac{t}{\tau}} IinRθ=1−e−τt
-
隔离指数项:
为了隔离指数项 e − t τ e^{-\frac{t}{\tau}} e−τt,我们可以两边减去1,然后乘以-1:
e − t τ = 1 − θ I in R e^{-\frac{t}{\tau}} = 1 - \frac{\theta}{I_{\text{in}}R} e−τt=1−IinRθ
也可以写成:
e − t τ = I in R − θ I in R e^{-\frac{t}{\tau}} = \frac{I_{\text{in}}R - \theta}{I_{\text{in}}R} e−τt=IinRIinR−θ
-
取自然对数:
为了消去指数,我们对方程两边取自然对数( ln \ln ln):
− t τ = ln ( I in R − θ I in R ) -\frac{t}{\tau} = \ln\left(\frac{I_{\text{in}}R - \theta}{I_{\text{in}}R}\right) −τt=ln(IinRIinR−θ)
-
求解 (t):
最后,把 − t τ -\frac{t}{\tau} −τt 乘上 − τ -\tau −τ:
t = τ ln ( I in R I in R − θ ) t = \tau \ln\left(\frac{I_{\text{in}}R}{I_{\text{in}}R - \theta}\right) t=τln(IinR−θIinR)
输入电流越大, U ( t ) U(t) U(t) 充电到 θ \theta θ 的速度越快,脉冲发生得越早。稳态电位 I in R I_{\text{in}}R IinR 设为输入特征 x x x:
t
(
x
)
=
{
τ
ln
(
x
x
−
θ
)
,
if
x
>
θ
∞
,
otherwise
(26)
t(x) = \begin{cases} \tau \ln \left( \frac{x}{x - \theta} \right), & \text{if } x > \theta \\ \infty, & \text{otherwise} \end{cases} \tag{26}
t(x)={τln(x−θx),∞,if x>θotherwise(26)
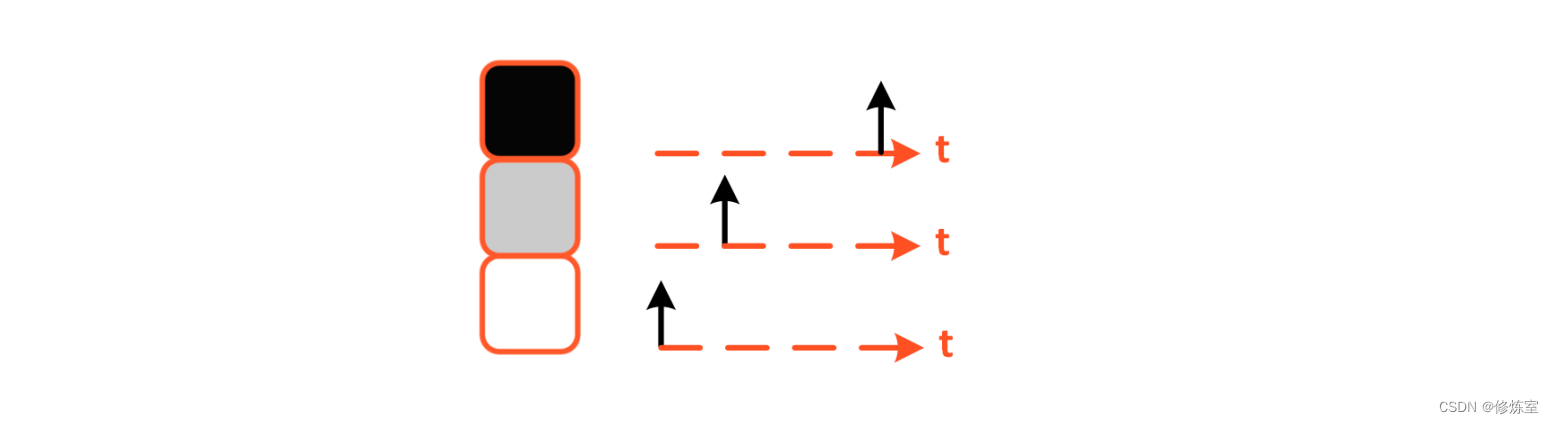
图S.3:延迟编码输入像素。输入像素强度越大,对应的脉冲时间越早。
Rate Coded Outputs
概念
Rate Coded Outputs 描述了如何从脉冲序列中确定输出类别。对于每个输出神经元,我们计算在给定时间步数内发放的脉冲数量,并据此确定输出类别。
B.3 速率编码输出
一种基于向量化实现的从脉冲编码的输出脉冲序列确定预测类别的方法如下描述。设 S [ t ] ∈ R N C \mathbf{S}[t] \in \mathbb{R}^{N_C} S[t]∈RNC 为一个随时间变化的向量,表示每个输出神经元在不同时间步上的脉冲发放情况【每个元素表示一个神经元的脉冲发放状态(0 表示没有脉冲,1 表示有脉冲)】,其中 N C N_C NC 为输出类别的数量。设 c ∈ R N C \mathbf{c} \in \mathbb{R}^{N_C} c∈RNC 为 每个输出神经元的脉冲计数 ,可以通过在 T T T 个时间步上对 S [ t ] \mathbf{S}[t] S[t] 求和得到:
c = ∑ j = 0 T S [ t ] (27) \mathbf{c} = \sum_{j=0}^{T} \mathbf{S}[t] \tag{27} c=j=0∑TS[t](27)
带有最大计数的
c
\mathbf{c}
c 的索引对应于预测的类别:
y
^
=
arg
max
i
c
i
(28)
\hat{y} = \arg\max_{i} c_i\tag{28}
y^=argimaxci(28)
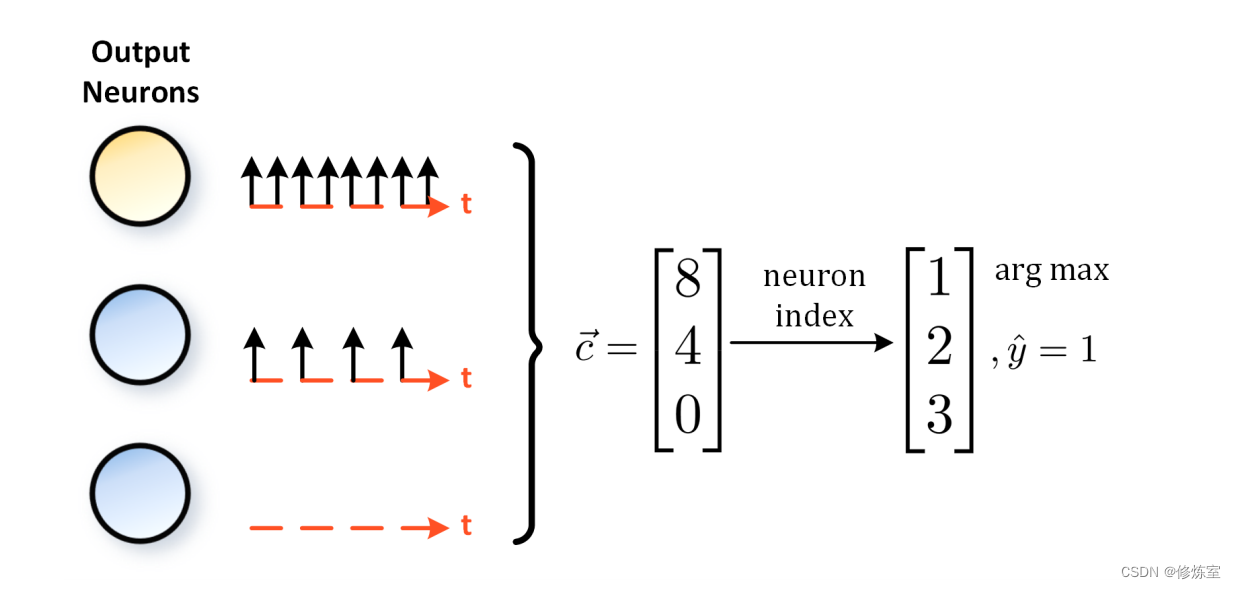
图 S.4: 脉冲编码的输出。 c ∈ R N C \mathbf{c} \in \mathbb{R}^{N_C} c∈RNC 表示每个输出神经元的脉冲计数,其中上面的例子显示第一个神经元总共发放了 8 次脉冲。 y ^ \hat{y} y^ 表示预测输出神经元的索引,其中表明第一个神经元是正确的类别。
这个方法的核心是通过对每个输出神经元在给定时间步
T
T
T 内的脉冲发放次数进行求和,从而确定哪个神经元的脉冲次数最多,对应的即为预测类别。具体过程如下:
-
时间变化的脉冲向量 S [ t ] \mathbf{S}[t] S[t]:
- 这是一个 N C N_C NC 维的向量,表示每个输出神经元在时间 t t t 的脉冲发放状态。
-
脉冲计数向量 c \mathbf{c} c :
- 通过对时间步 T T T 内的 S [ t ] \mathbf{S}[t] S[t] 进行求和,得到每个输出神经元的脉冲总数。
-
预测类别:
- 通过找到 c \mathbf{c} c 中脉冲计数最多的神经元的索引来确定预测类别,即:
y ^ = arg max i c i (28) \hat{y} = \arg\max_{i} c_i \tag{28} y^=argimaxci(28)
在上面的例子中,三个输出神经元的脉冲计数分别为 8, 4 和 0,因此预测类别为第一个神经元。
“每个输出神经元在不同时间步上的脉冲发放情况”指的是在每个时间步 (t) 上,每个输出神经元是否发放脉冲的状态。这通常表示为一个向量,其中每个元素表示一个神经元的脉冲发放状态(0 表示没有脉冲,1 表示有脉冲)。
时间变化的脉冲向量 S [ t ] \mathbf{S}[t] S[t]
- 这是一个 N C N_C NC 维的向量,表示每个输出神经元在时间 t t t 的脉冲发放状态。这里的维度 N C N_C NC 是输出神经元的数量。
- 向量 S [ t ] \mathbf{S}[t] S[t] 的每个元素可以是0或1。比如,如果有三个输出神经元,那么 S [ t ] \mathbf{S}[t] S[t] 可能是 [1, 0, 1],表示第一个和第三个神经元在时间 t t t 发放了脉冲,而第二个神经元没有发放脉冲。
具体来说,这个向量用于表示每个输出神经元在某个特定时间步是否发放了脉冲。这种表示方式方便了计算,因为可以在一个向量中同时表示多个神经元的状态,而不需要单独处理每个神经元。
为什么是向量?
使用向量的原因是:
- 并行计算:向量化表示允许我们在一个时间步内并行处理所有输出神经元的脉冲状态,这在计算上更加高效。
- 简洁表示:向量化可以简洁地表示多个神经元的状态,而不需要单独记录每个神经元的状态。
- 矩阵运算:在神经网络的训练和推理过程中,很多操作都是基于矩阵和向量的,这种表示方式便于进行线性代数运算。
向量的方向问题
在这种情况下,向量的方向并没有特定的物理意义。这里的向量只是一个数学工具,用于方便地表示多个神经元的状态集合。向量中的每个元素只是表示对应神经元是否发放了脉冲,而不是表示某个物理方向。
预测类别的理解
在这里,预测类别是指脉冲神经网络(SNN)的最终输出结果。具体来说,通过计算每个输出神经元在一定时间内发射的脉冲次数,脉冲次数最多的神经元的索引就是预测类别。例如,如果我们有三个输出神经元,并且脉冲计数向量 (\mathbf{c}) 为 ([8, 4, 0]),那么预测类别就是索引为0的那个神经元对应的类别。
累积脉冲计数向量 c \mathbf{c} c:
c \mathbf{c} c 是通过对所有时间步 T T T 内的脉冲向量 S [ t ] \mathbf{S}[t] S[t] 进行求和得到的。公式如下:
c = ∑ t = 0 T S [ t ] \mathbf{c} = \sum_{t=0}^{T} \mathbf{S}[t] c=t=0∑TS[t]
例如,假设在一个时间区间内, S [ t ] \mathbf{S}[t] S[t] 的值如下:
- S [ 0 ] = [ 1 , 0 , 0 ] \mathbf{S}[0] = [1, 0, 0] S[0]=[1,0,0]
- S [ 1 ] = [ 1 , 1 , 0 ] \mathbf{S}[1] = [1, 1, 0] S[1]=[1,1,0]
- S [ 2 ] = [ 1 , 0 , 0 ] \mathbf{S}[2] = [1, 0, 0] S[2]=[1,0,0]
- S [ 3 ] = [ 1 , 0 , 0 ] \mathbf{S}[3] = [1, 0, 0] S[3]=[1,0,0]
- S [ 4 ] = [ 1 , 1 , 0 ] \mathbf{S}[4] = [1, 1, 0] S[4]=[1,1,0]
- S [ 5 ] = [ 1 , 0 , 0 ] \mathbf{S}[5] = [1, 0, 0] S[5]=[1,0,0]
- S [ 6 ] = [ 1 , 1 , 0 ] \mathbf{S}[6] = [1, 1, 0] S[6]=[1,1,0]
- S [ 7 ] = [ 1 , 1 , 0 ] \mathbf{S}[7] = [1, 1, 0] S[7]=[1,1,0]
那么我们可以对每个时间步的 S [ t ] \mathbf{S}[t] S[t] 进行求和,得到脉冲计数向量 c \mathbf{c} c:
c = ∑ t = 0 7 S [ t ] = [ 8 , 4 , 0 ] \mathbf{c} = \sum_{t=0}^{7} \mathbf{S}[t] = [8, 4, 0] c=t=0∑7S[t]=[8,4,0]
这表示第一个输出神经元在这段时间内发射了8次脉冲,第二个输出神经元发射了4次脉冲,第三个输出神经元没有发射脉冲。

















 3832
3832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









