









 本文深入解析OpenGL渲染管线,从CPU与GPU的并行计算特点,到OpenGL规范与库的实现,再到现代可编程渲染管线的各个阶段:顶点着色器、细分着色器、几何着色器、光栅化、片段着色器以及逐片元操作。文章详细介绍了每个阶段的工作原理,以及如何通过编程控制图形渲染效果。
本文深入解析OpenGL渲染管线,从CPU与GPU的并行计算特点,到OpenGL规范与库的实现,再到现代可编程渲染管线的各个阶段:顶点着色器、细分着色器、几何着色器、光栅化、片段着色器以及逐片元操作。文章详细介绍了每个阶段的工作原理,以及如何通过编程控制图形渲染效果。
OpenGL渲染管线
OpenGL本身并不是一个API,他仅仅是一个由Khronos组织制定并维护的规范;OpenGL规范严格规定了每个函数改如何执行,以及他们的输出值,至于内部具体每个函数是如何实现的,将有OpenGL库的开发者自行决定。因为OpenGL规范并没有规定实现的细节,具体的OpenGL库允许使用不同的实现,只要其功能和结果与规范相匹配。
CPU & GPU
GPU具有高并行结构(highly parallel structure),所以GPU在处理图形数据和复杂算法方面拥有比CPU更高的效率;CPU大部分面积为控制器和寄存器,与之相比,GPU拥有更多的ALU(逻辑运算单元)用于数据处理,而非数据高速缓存和流控制,这样的结构适合度密集行为数据进行并行处理;CPU执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的并行(OS教程上的时间轮转算法),而GPU具有多个处理器核,在一个时刻可以并行处理多个数据。

GPU采用流式并行计算模式,可对每个数据进行独立的计算,所谓“对数据进行对立计算”,即流内任意元素的计算不依赖于其他同类型数据,例如:计算一个顶点的世界坐标位置,不依赖于其他顶点的位置。而所谓“并行计算”是指“多个数据可以同时被使用,多个数据并行运算的时间和1个数据单独执行的时间时一样的”;在提取2D图像上每个像素点的颜色值,在CPU上运算的C++代码通过循环语句一次便利像素;而在GPU上,则只需要一个语句就足够了。
程序的主函数都在CPU上执行,图形的渲染在GPU上执行,GPU亦可进行通用编程,但这样的程序也需要在CPU上执行代码来操控GPU;下图中PCle的带宽大约时内存速度的三分之一,这个层次上的性能优化主要思路:
减少程序对PCI传输带宽的占用,增加主程序(CPU)以及着色器(GPU)访问储存器的局部性(增加缓存命中率或更多的使用寄存器)

着色器程序在GPU上执行,OpenGL主程序在CPU上执行,主程序向显存输入顶点数据,启动渲染过程,并对渲染过程进行控制;了解到这一点就知道了显示列表以及glfinish函数存在的原因了:
显示列表:将一组绘制指令放到GPU上,CPU只要发一条“执行这个显示列表”这些指令就执行,而不必CPU每次渲染都发送大量指令到GPU,从而节约PCI带宽(因为PCI总线比显存慢);
glFinish:让CPU等待GPU将已发送的渲染指令执行完。
GPU提供了大规模并行机制,特别适合执行高度并行的渲染过程;GPU的线程数可以达到上百万个或者更多,如何运行如此多的线程,CUDA架构模型如下:

Host和Device分别表示CPU和GPU的编程视图,基本思路是将线程按两次层次分组,多个线程(Thread)组成Block,多个Block组成Grid,Grid的存储模式:

关键点是Block内提供了共享存储;因为多个线程要相互通信,共享存储模型是最方便快速的通信方式,但对众多的线程全都提供共享存储模型会影响效率(并发访问存储器,线程有上百万个之多),CUDA(OpenCL也是类似的)采用一种折衷方式:提供有限的共享存储编程,Block内提供高速共享存储,而Block间的通过全局存储(显存)的通信要慢的多。这种编程模型和GPU硬件是相对应的:

GPU主要由显存(Device Memory)和SMs(流多处理器,Stream Multiprocessors)组成,显卡的好坏基本就取决于有多少个SM了。上述编程模型和GPU模型有对应关系:
Block总是在一个SM上执行,Block内部的共享存储模型由SM硬件的共享存储器提供。线程层次上性能优化的主要思路是:尽量使 Kernel 代码(每个线程,尤其是同一个 Block 内的线程)具有相同的执行路径(即分支跳转情况尽量相同),以充分利用GPU访存及代码执行方面的并行机制。
OpenGL也定义的自己的执行模型(用 Compute Shader 进行通用计算),和CUDA执行模型非常类似;在OpenGL概念中,CUDA的Grid变成了Dispatch,Block变成了Work Group,Thread变成了Invocation,同样,Dispatch可以由三维索引的Work Group组成,Work Group可以由三维索引的Invocation组成。

固定渲染管线
早期的OpenGL使用立即渲染模式(Immediate mode,也就是固定渲染管线),这个模式下绘制图形很方便。OpenGL大多数功能都被库隐藏起来,开发者很少能控制OpenGL如何进行计算的自由。
现代可编程渲染管线
OpenGL实现了我们通常所说的“渲染管线”,他是一系列数据处理过程,并且将应用程序的数据转换到最终渲染的图像;OpenGL首先接受用户提供的几何数据(顶点和几何图元),并且将它输入到一系列着色器阶段进行处理,包括:顶点着色,细分着色,以及最后的几何着色,然后将他送入光栅化单元,光栅化单元负责对所有剪切区域内的图元生成片元数据,然后对每个生成的片元都执行一个片元着色器。

图形渲染管线的每个阶段的抽象展示
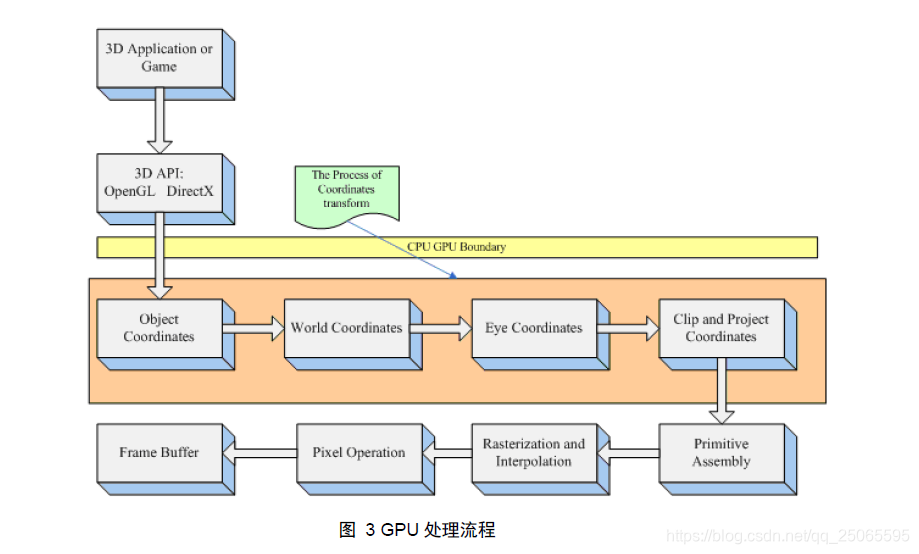
上图来自(GPU Programming And Cg Language Primer 1rd Edition)

准备传输数据,将数据传输到OpenGL
因为应用程序阶段运行于CPU上,开发者可以对其全面掌控。因些,开发者可完全决定其实现并在之后对其修改以提高运行效率。在这里的改变亦能影响后面阶段的运行效率。但如一些应用程序阶段的算法和设定可能减少将被渲染的多边形。
在应用程序阶段的最后步骤,将被渲染的几何体会输入到顶点着色器。这些几何体都是绘制图元,例如点、线和三角形等最后将输出到屏幕(或者被输出设备所用)。这是应用程序阶段中最重要的任务。
这阶段的实现是以软件为基础,这导致到不像其他阶段那样,被析分为多个子阶段。但是为了提升运行效率,该阶段经常并行运行在多个处理器核心上。在中央处理器设计方面说,这叫超标量体系结构,因为它能够在同一阶段同一时间内运行数个运算步骤。
通常在这阶段实现的运算步骤是碰撞检查。当一关于两物体的碰撞检测出来后,反应将会被生成并发送到碰撞的对象和力反馈设备上,应用程序阶段亦是处理包括键 盘、鼠标、头盔等设备输入的地方。跟据不同的输入,作出不同的反应。该阶段的其它步骤包括纹理动画或者一些不运行在其它阶段的计算。一些加速算法,例如层次化视图平截体裁剪亦是在此处实现。
我们需要通过缓冲对象来存储顶点数据(位置,纹理坐标,法线等),它会在GPU内存(通常被称为显存)中储存大量顶点数据。使用这些缓冲对象的好处是我们可以一次性的发送一大批数据到显卡上,而不是每个顶点发送一次。从CPU把数据发送到显卡相对较慢,所以只要可能我们都要尝试尽量一次性发送尽可能多的数据。当数据发送至显卡的内存中后,顶点着色器几乎能立即访问顶点,这是个非常快的过程。
将缓存数据初始化完毕之后,可以通过OpenGL的一个绘制命令来请求渲染几何图元。
顶点着色器
为了实现逼真的场景,仅渲染对象的形状和位置是不足够的,它们的外观亦需要模拟。这些描述包括第每对象材质,以及光源照射对象产生的特效。模拟材质和光源的方法有很多种,包括从最简单的颜色到精细的物理特性描述。
决定光和材质特效的操作称为着色。它包括了计算不同点的着色方程。典型的某些这类的计算运行在几何阶段的模型顶点数组上,另外一些则运行在逐象素的光珊化阶段。各类的材质数据,例如点所在位置,法向量,颜色或其它着色方程需用到的数值信息,可储存在每个顶点中。顶点着色的结果(这可能是颜色,向量,纹理坐标或其它种类的着色数据)会被送进光珊化阶段去插值。
着色阶段通常被认为是发生在世界空间。在实践中,有时则将相应的实体(例如摄像机和光源)变换到其它空间(例如模型或视觉空间)并在那运行计算更为方便。因为如果所有包含在着色计算中的对象均被变换到同一空间,则光源、摄像机和模型的相对关系是保留的。
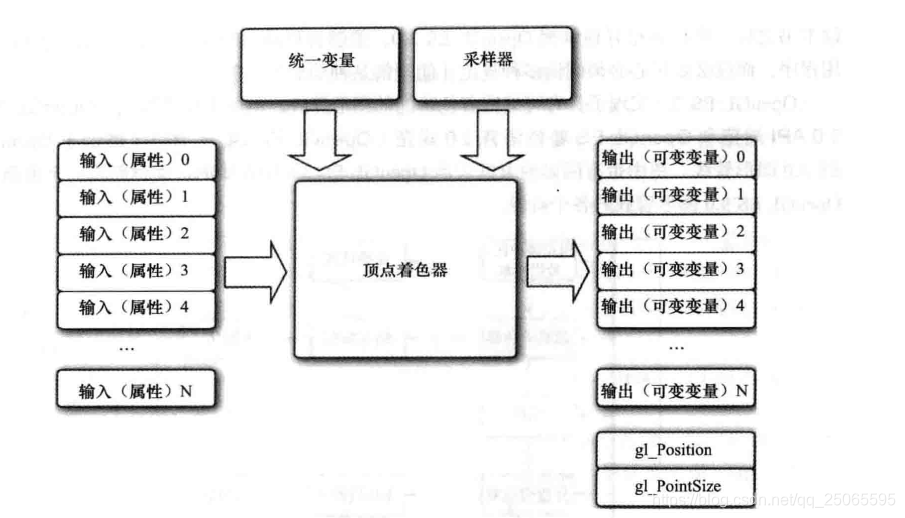
在 openGL 编程中顶点着色器是必须的,对绘制命令传输的每个顶点,OpenGL都会调用一个顶点着色器来处理顶点相关数据,顶点着色器的功能如下:
- 使用模型视图矩阵和投影矩阵进行顶点位置变换
- 法线变换,法线工规范化
- 纹理坐标生成和变换
- 计算每个顶点的光照
- 颜色计算
标准化设备坐标(Normalized Device Coordinates, NDC)
一旦你的顶点坐标已经在顶点着色器中处理过,它们就应该是标准化设备坐标了,标准化设备坐标是一个x、y和z值在-1.0到1.0的一小段空间。任何落在范围外的坐标都会被丢弃/裁剪,不会显示在你的屏幕上。下面你会看到我们定义的在标准化设备坐标中的三角形(忽略z轴):
与通常的屏幕坐标不同,y轴正方向为向上,(0, 0)坐标是这个图像的中心,而不是左上角。最终你希望所有(变换过的)坐标都在这个坐标空间中,否则它们就不可见了。
你的标准化设备坐标接着会变换为屏幕空间坐标(Screen-space Coordinates),这是使用你通过glViewport函数提供的数据,进行视口变换(Viewport Transform)完成的。所得的屏幕空间坐标又会被变换为片段输入到片段着色器中。

细分着色器
在顶点着色器中操作几何图元数据,还是有一些局限性:在运行是无法创建新的几何体(顶点着色器只是在处理当前顶点的过程中对其关联的数据进行更新,甚至无法做到对图元中其他的顶点数据进行访问)。
细分着色在OpenGL 中有两个着色阶段,用来生成几何图元的模型网格;在顶点着色阶段,需要设置所有的线段或者三角形来构成处理的模型;而在细分着色器阶段首先要指定面片,也就是顶点的有序列表;当渲染面片的时候,将首先执行细分控制着色器处理面片顶点,并设置面片中要生成多少几何数据;当细分控制着色器结束之后,第二个着色器(即细分计算着色器)将负责把生成网格的顶点放置到细分坐标指定的位置,并且将他们发送搭配光栅化阶段,或者发送给几何着色器进行更多的处理。
几何着色器
几何着色器输入是一系列顶点组成的完整的图元,并且这些输入全部是数组形式,通常来说这些输入数据来自于顶点着色器;不过如果激活细分着色器,那么几何着色器的输入将来自细分计算着色器的结果;因为几何着色器的每个请求都负责处理一个完整的图元,所以可以访问这个图元的所有顶点,进而实现一些专门的技巧。
除了增强多顶点的访问属性之外,几何着色器还可以控制输出数据的数量(如果输出的总量为0,那么几何体将被裁剪;如果输出的顶点数比原始图元要多,那么相当于进行了几何体的细化操作);几何着色器还可以产生和输入数据不同的输出图元类型(即在管线中改变几何体的类型);几何着色器还可以和 transform feedback 共同使用,将输入的顶点数据流切分为多个子数据流。
图元装配
顶点处理或者顶点着色器的输出是一些列变换后的位于Clip坐标系的顶点,这些顶点首先根据顶点之间的连接关系(点、线、多边形)进行图元装配:

剪切
图元装配之后是剪切(Clipping),见文献[1]2.22,下面是裁剪公式(文献[1]第142页):

多边形的裁剪可能产生新的顶点,这些的点的颜色值以及纹理坐标等值要被插值。除了默认的xyz分别为±1的正方体的六个面的裁剪面,用户可以指定额外的裁剪面:glClipPlane(GL_CLIP_PLANE0[1,2,...],double eqn[4]),glEnable/Disable(GL_CLIP_DISTANCE0[1,2,...]),注意指定的值会被乘以当前模型视图矩阵的逆,乘完得到的值在视觉坐标系中进行裁剪(同从顶点视觉坐标自动生成纹理坐标的参数)。
裁剪之后是透视除法(Perspective Division):

透视除法之后是视口变换(Viewport Transformation):
![]()


视口变换同时也将原来z坐标缩放到[0,1]变成Depth值,深度值默认在[0,1]且值越小离摄像机越近,可以指定深度值范围:glDepthRange(GLclampd n,GLclampd f),其中GLclampd[f]类型表示值将被钳位到[0,1]),视口变换完成后的图元将进入光栅化阶段。
光栅化
到目前为止,管线里的数据都是顶点,经过图元装配之后,哪些顶点就是一个点、哪两个顶点是直线段、哪三个或更多顶点是一个三角形或多边形,这些图元信息都已经知道了,但它们还是只是顶点而已:顶点处都还没有“像素点”、直线段端点之间是空的、多边形的边和内部也是空的,光栅化的任务就是构造这些。由于已经经过了视口变换,光栅化是在二维(附带深度值)的屏幕坐标系(Window Space)中进行的。
光栅化有两个任务:1.确定图元包含哪些由整数坐标确定的“小方块”(和屏幕像素对应,现在还不能叫片断,光栅化完成后才能叫片断),2.确定这些小方块的Depth值和Color值(从图片顶点的Depth和Color插值得到),这些颜色后来可能被其他如纹理操作修改。如下图:

光栅化在对多边形图元进行“方块化”之前,要给出多边形是front-facing还是back-facing(正面还是背面,点和直线只有正面),这是根据多边形顶点的环绕方向确定的(是顺时针还是逆时针,默认逆时针为front-facing,可由glFrontFace(GL_CCW[CW])控制)。正背面判断结果将用于选择是用顶点的正面颜色还是背面颜色来对片断颜色进行插值。随后如果glIsEnabled(GL_CULL_FACE)为真,对于方向和glCullFace(GL_FRONT[BACK])的参数相同的多边形图元,将被剔除,即直接跳过光栅化的后续操作。另外,光栅化除了直接对多边形进行填充这种方式之外,还可以只构造边或只有点,这由glPolyMode(GL_FRONT[BACK,FRONT_AND_BACK],GL_FILL[LINE,POINT])控制。
这里强调一下光栅化判断正背面和正背面光照的区别,前者是对图元的操作并依据顶点环绕方向(一个多边形图元有多个顶点,也就有多个法向量,这些向量可能不同,所以不可能依据法向量来判断图元朝向),后者是对顶点的操作并依据顶点的法向量。举个例子,如果一个三角形按照顶点环绕的右手法则方向的反方向指定法向量,并且法向量朝物体外侧,当光照为单面光照时,因为光栅化判断为背面的多边形图元其片断用顶点背面光照颜色进行插值,单面光照下,和顶点正面光照颜色相同,所以没有问题,但当光照为双面光照时,图元的沿法向量这边的“光照正面”却是光栅化依据顶点环绕方面判断的“光栅化背面”,这时,我们将看到一个灰色的好像没有光照一样的东西,从而得不到结果。所以,对三角形或多边形的由顶点法向量确定的正面(三个或更多顶点法向量确定的正面一致,指这个面)要和光栅化用顶点环绕方面的正面相同,这样才不会出现意想不到的效果。
最为复杂的纹理在光栅化阶段进行,下图是多重纹理的操作示意(文献[1]第280页):

之所以说纹理复杂,在于纹理坐标的计算上,每个片断要找到一个纹理坐标以索引纹理像素,这个计算看似简单,但出问题时将产生意想不到的效果,如下图:

图中所说的Projective和Real Space坐标就是我们所说的透视除法前后的坐标。
在光栅化对图元进行“小方块化”并对“小方块”进行插值之后,后来的纹理和雾等操作可以由片断着色器代替,片断着色器还可以对片断进行更多计算,如逐片断光照,处理后的片断将进入下一步逐片断处理。
片段着色器
片段着色器是通过编程控制屏幕上显示颜色;在这个阶段,使用着色器来计算片段的最终颜色(尽管在下一阶段逐片元操作时可能还会改变颜色一次)和它的深度值;片元着色器非常强大,我们会使用纹理映射的方式,对顶点处理阶段所计算的颜色值进行补充;如果我们觉得不应该继续绘制片段,在片段着色器中我们可以终止这个片元的处理,这一步叫做片元的丢弃(discard)
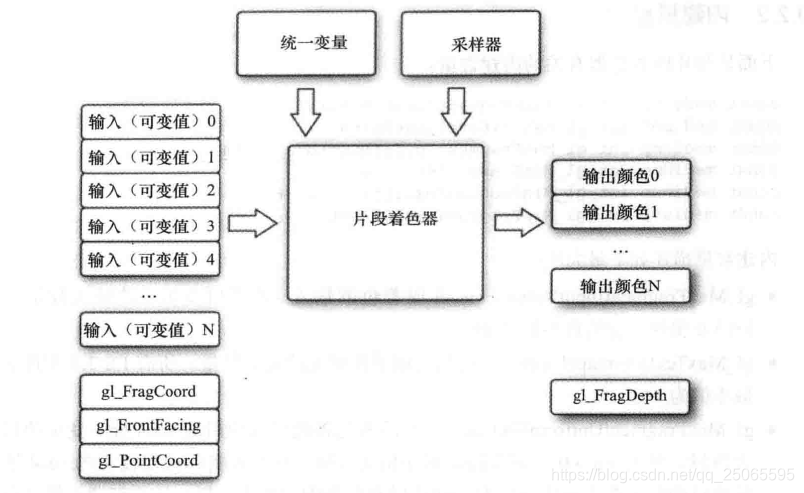
逐片元操作
光栅化的输出是一些列片断(Fragments,这些片断可能经过片断着色器处理),片断被称为“准像素”,要能想象出屏幕坐标系的一个整数坐标上只有一个像素,但可以前后“堆叠”多个片断。这些片断进入逐片断处理(Per-Fragment Operations),首先进行各种测试(下图中共5个),每步测试,不通过的片断将被丢弃从而不能进入后续操作,然后进行一些操作(如混合),最终通过所有处理的片断将被写入FrameBuffer用于最终屏幕显示,这个过程如下图:

Scissor Test对用户指定的scissor rectangle进行测试,Alpha Test用片断Alpha值进行测试(如片断Alpha值小于设定ref值时通过),Depth Buffer Test和遮挡处理有关(如片断深度值小于其同坐标的深度缓冲区元素的值时通过),Stencil Test可以根据Stencil或Depth Buffer Test结果分条件更新Stencil Buffer实现很多功能(如zfail时,片断同坐标的Stencil缓冲区元素加1,zpass时减1,第二遍渲染再设置Stencil test为片断同坐标Stencil缓冲区元素值为0时通过),如Shadow Volumes算法。上图中,框下面有小箭头连接FrameBuffer的说明该测试要访问或更新FrameBuffer的值。
所有操作均通过的片断将被写入FrameBuffer,包括RGBA缓冲、Depth缓冲,注意Stencil缓冲仅用于测试,片断没有Stencil值。还有一个缓冲叫做Accumulation Buffer,多用于运动模糊、景深模糊等,但不能直接写入,而是将RGBA缓冲整幅累积。
这些操作可以用glEnable/glDisable(GL_ALPHA/STENCIL/DEPTH_TEST)、glEnable/glDisable(GL_BLEND)等打开或关闭,对于RGBA, Depth, Stencil Buffer,可以用glColor/Depth/StencilMask(GLboolean/GLuint)进行控制是否可写。注意,缓冲区使能和缓冲区屏蔽是独立的,使能控制是否进行测试,如果不进行测试,片断将直接通过,然后对于通过测试的片断根据是否屏蔽决定是否更新缓冲区。
以上参考:
- Real Time Rendering 第三版
- OpenGL 编程指南第8版
- opengl.org
- https://learnopengl.com
- OpenGL ES 3.0 编程指南
- http://www.cnblogs.com/liangliangh/p/4116164.html
- GPU编程

















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









