







公众号:尤而小屋
作者:Peter
编辑:Peter
吴恩达机器学习-9-降维PCA
在本文中主要介绍的是数据降维相关的内容,重点讲解了PCA算法
- 为何实施降维
- 数据压缩
- 数据可视化
- PCA算法
- PCA和线性回归算法的区别
- PCA算法特点
- Python实现PCA
- sklearn中实现PCA
为何降维
在现实高维数据情况下,会有数据样本稀疏、距离计算困难等问题,被称为维数灾难。
解决的方法就是降维,也称之为“维数约简”,即通过某种数据方法将原始高维属性空间转成一个低维“子空间”。在这个子空间中,样本密度大大提高,将高维空间中的一个低维“嵌入”。
降维Dimensionality Reduction
数据降维主要是有两个动机:
- 数据压缩
Data Compression - 数据可视化
Data Visualization
数据压缩Data Compression
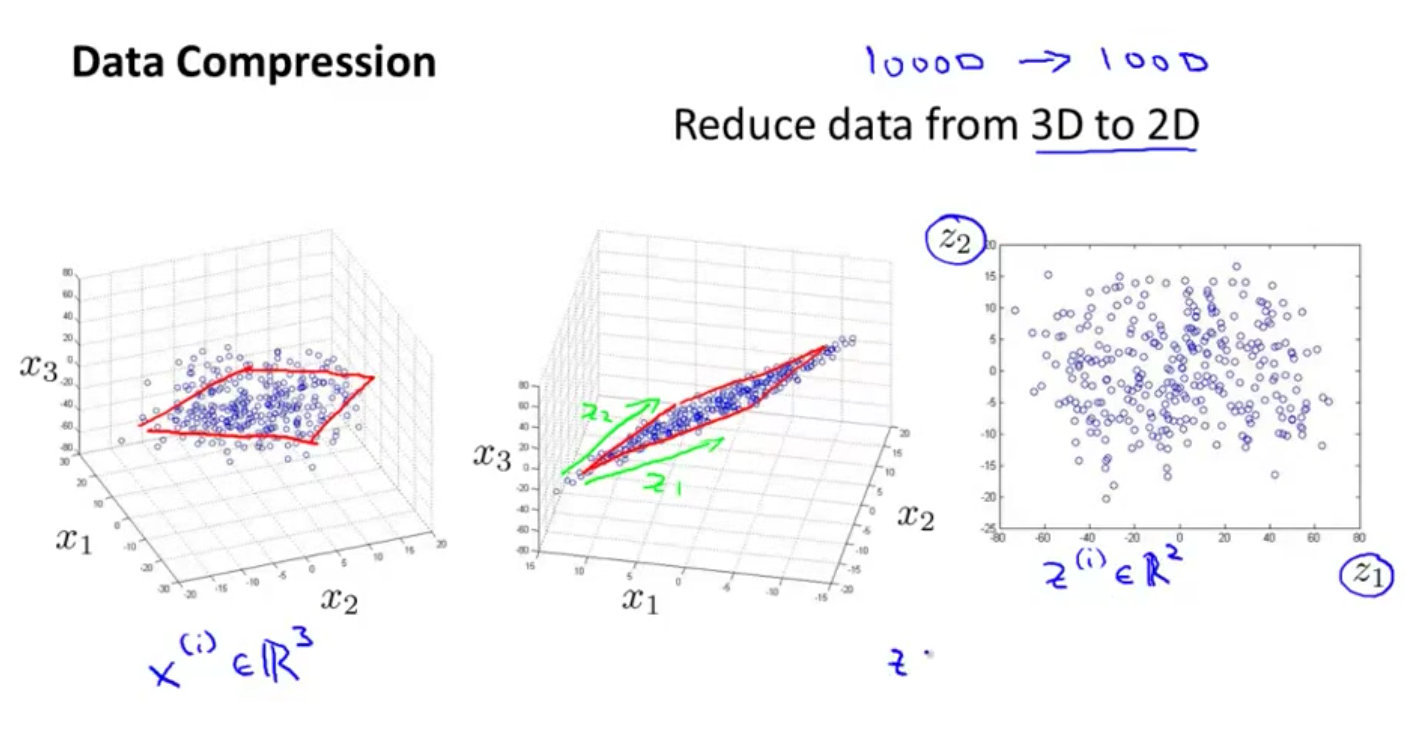
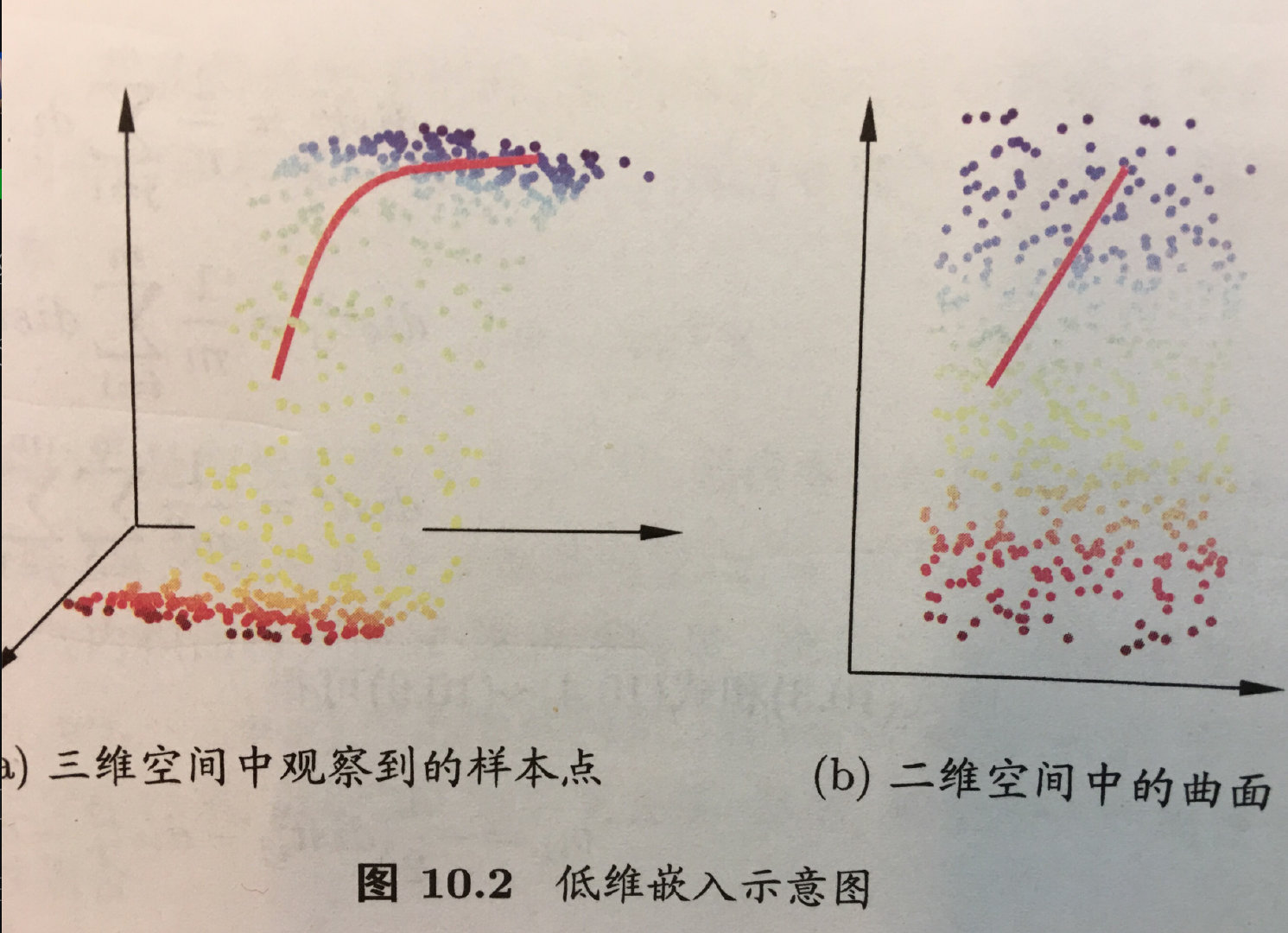
上图解释:
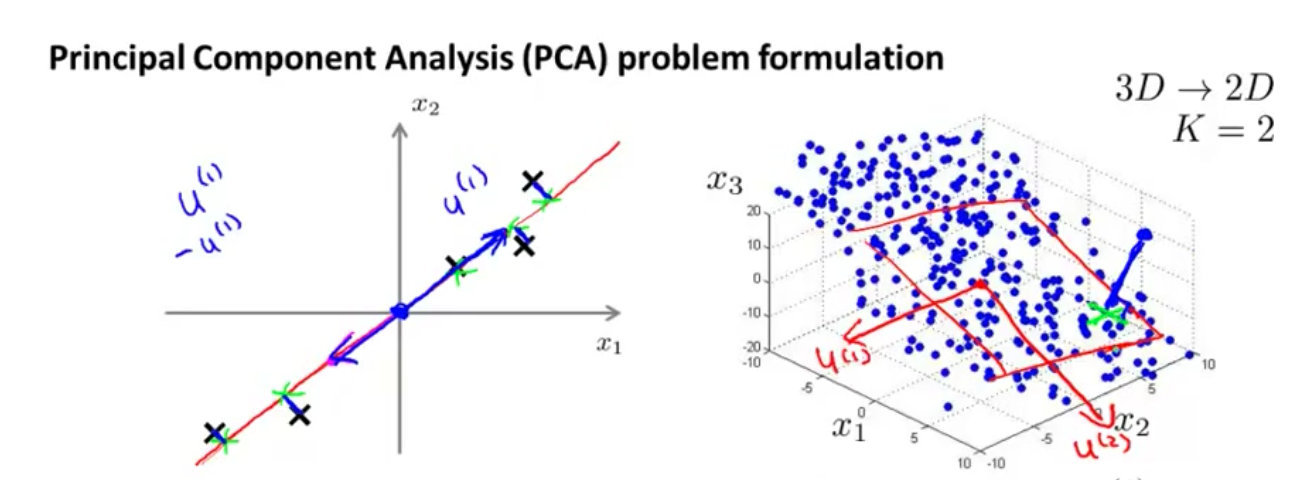
- 在一个三维空间中的特征向量降至二维的特征向量。
- 将三维投影到一个二维的平面上,迫使所有的数据都在同一个平面上。
- 这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将
1000维的特征降至100维。
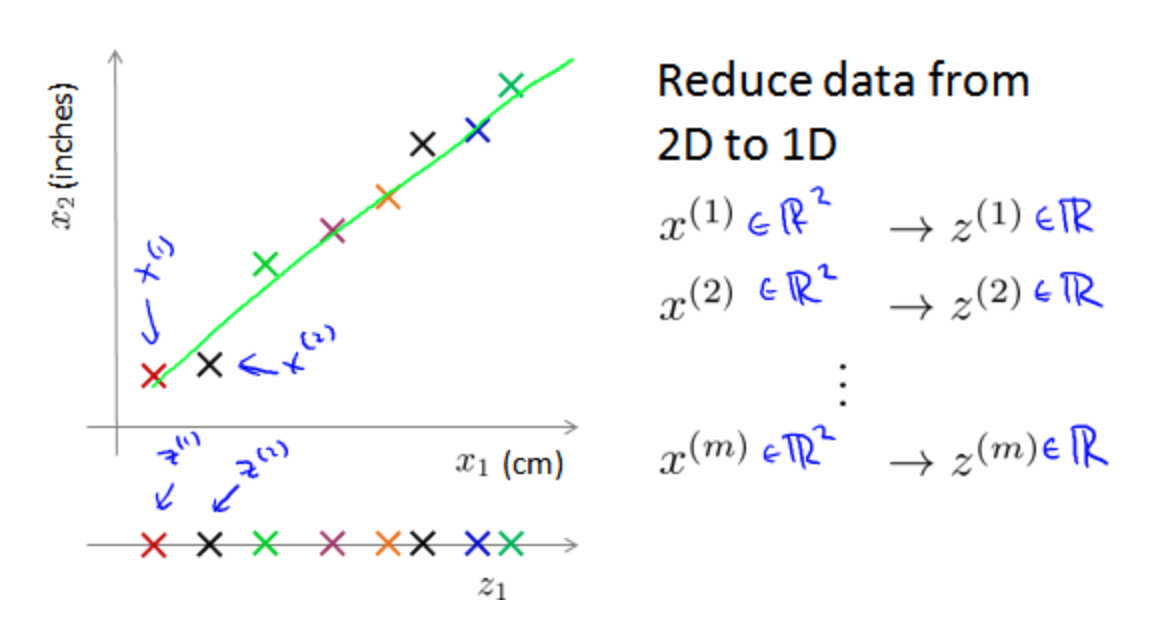
数据可视化Data Visualization
降维能够帮助我们进行数据的可视化工作。
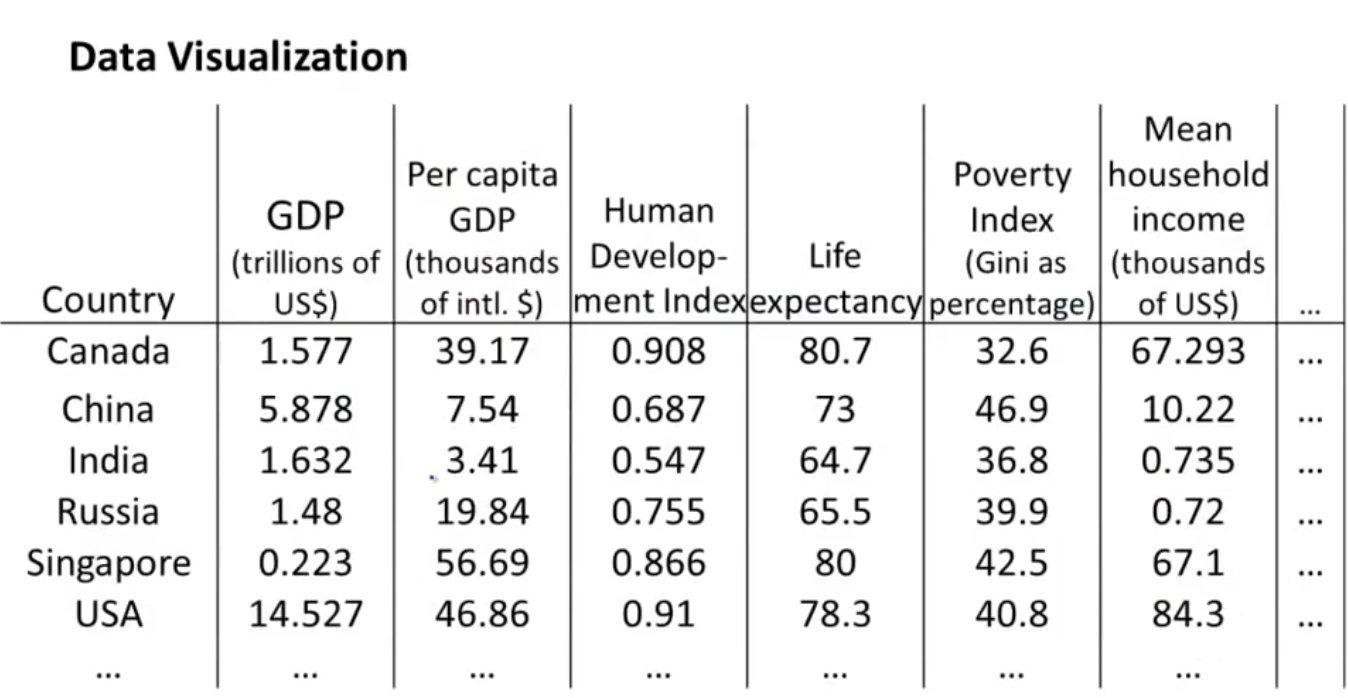
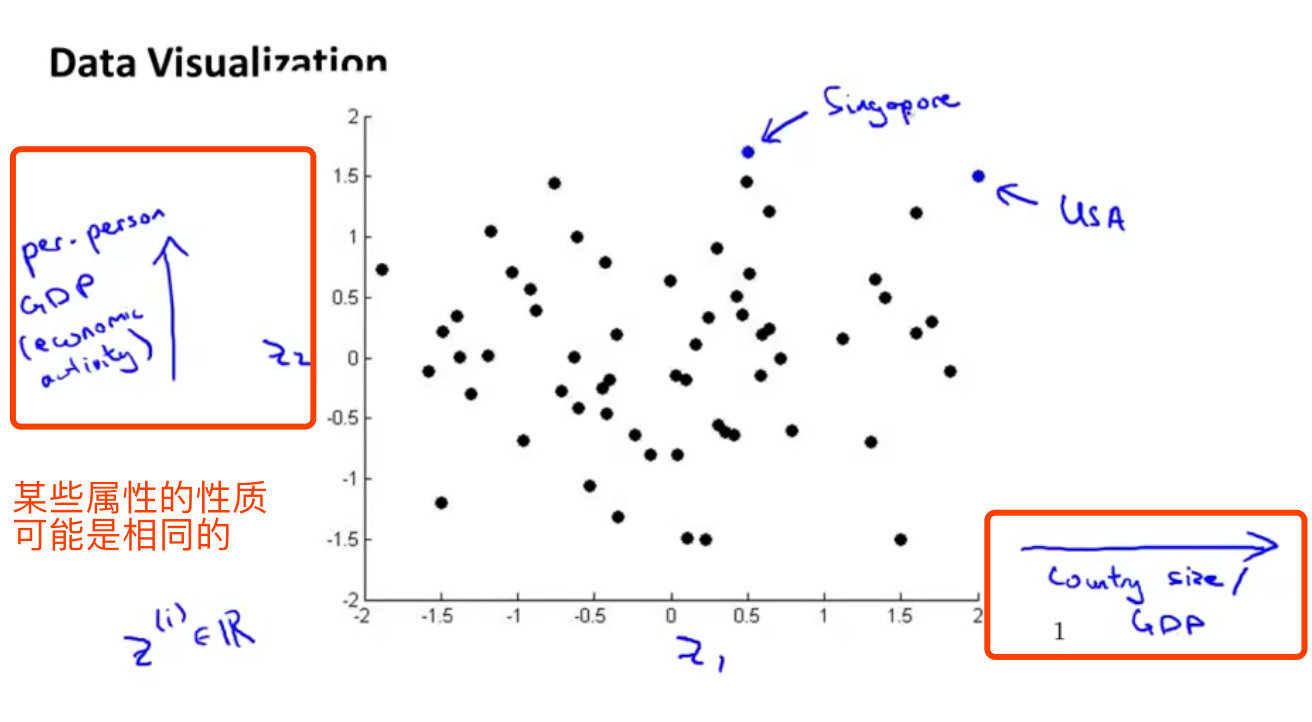
上面图的解释:
- 假设给定数据,具有多个不同的属性
- 某些属性表示的含义可能相同,在图形中可以放到同一个轴上,进行数据的降维
PCA- Principal Component Analysis
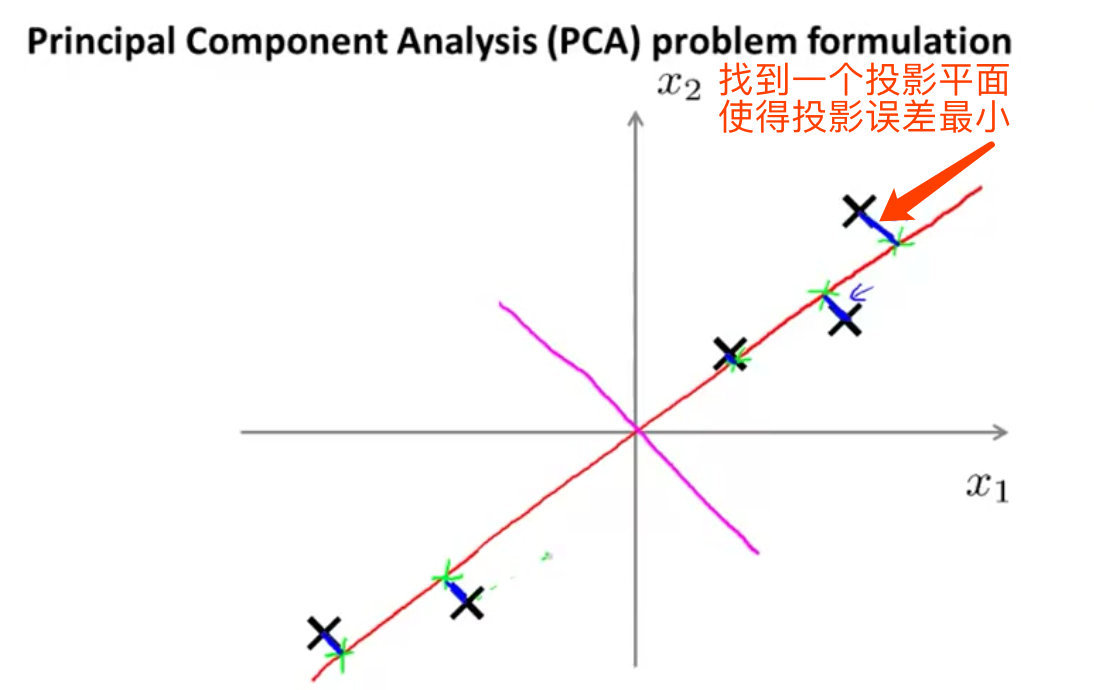
在PCA中,要做的是找到一个方向向量(Vector direction),当把所有的数据都投射到该向量上时,PCA的关键点就是找到一个投影平面使得投影误差最小化。
方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。
PCA与线性回归的区别
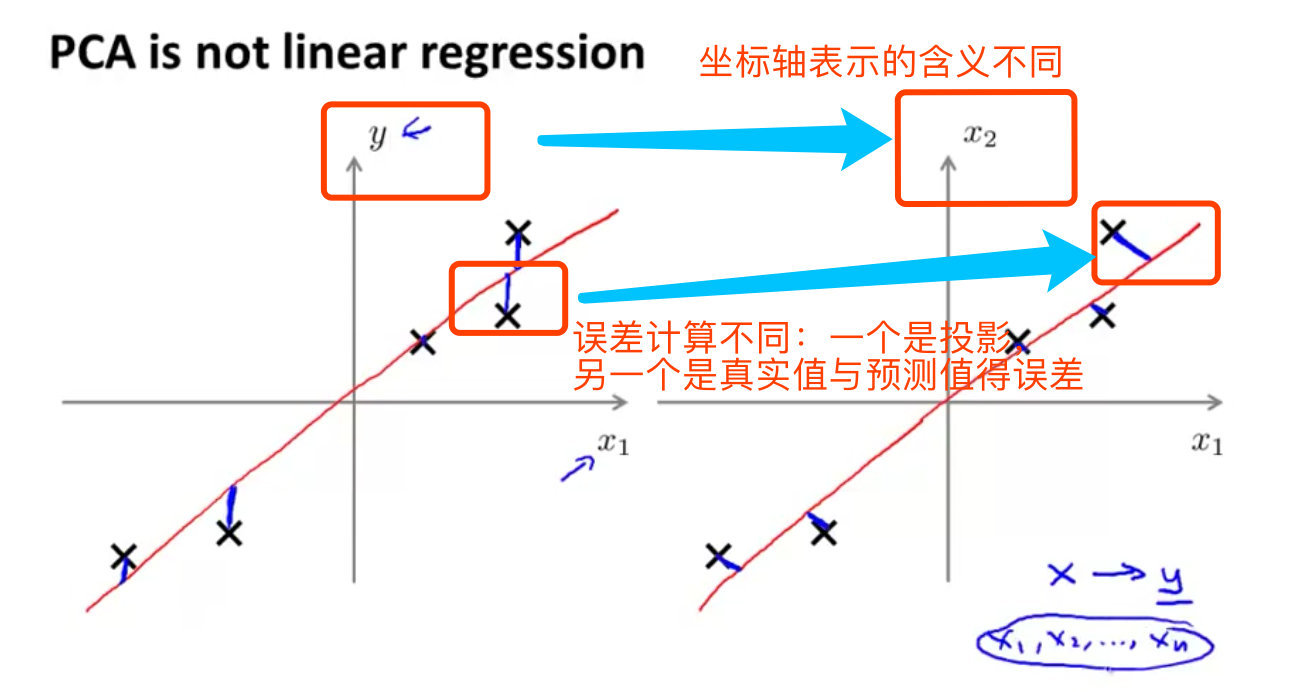
- 线性回归中的纵轴是预测值,
PCA中是特征属性 - 误差不同:
PCA是投射误差,线性回归是尝试最小化预测误差。 - 线性回归的目的是预测结果,`PCA·是不做任何分析。
PCA算法
主成分分析中,首先对给定数据进行规范化,使得数据每一变量的平均值为0,方差为1。
之后对数据进行正交变换,用来由线性相关表示的数据,通过正交变换变成若干个线性无关的新变量表示的数据。
新变量是可能的正交变换中变量的方差和(信息保存)最大的,方差表示在新变量上信息的大小。将新变量一次成为第一主成分,第二主成分等。通过主成分分析,可以利用主成分近似地表示原始数据,便是对数据降维。
PCA算法中从n维到k维的过程是
-
均值归一化。计算所有特征的均值,令 x j = x j − μ j x_j=x_j-\mu_j xj=xj−μj,如果特征不在一个数量级上,需要除以标准差
-
计算协方差矩阵 covariance matrix
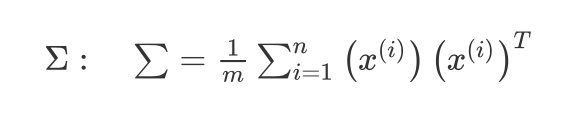
Σ : ∑ = 1 m ∑ i = 1 n ( x ( i ) ) ( x ( i ) ) T \Sigma: \quad \sum=\frac{1}{m} \sum_{i=1}^{n}\left(x^{(i)}\right)\left(x^{(i)}\right)^{T} Σ:∑=m1i=1∑n(x(i))(x(i))T
- 计算协方差矩阵 ∑ \sum ∑的特征向量 eigenvectors

在西瓜书中的描述为

主成分个数确定
关于PCA算法中主成分个数k的确定,一般是根据公式:
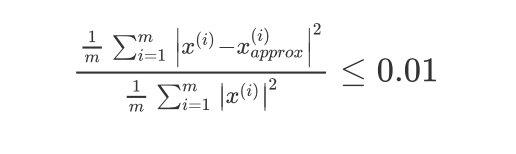
1 m ∑ i = 1 m ∣ x ( i ) − x a p p r o x ( i ) ∣ 2 1 m ∑ i = 1 m ∣ x ( i ) ∣ 2 ≤ 0.01 \frac{\frac{1}{m} \sum_{i=1}^{m}\left|x^{(i)}-x_{a p p r o x}^{(i)}\right|^{2}}{\frac{1}{m} \sum_{i=1}^{m}\left|x^{(i)}\right|^{2}} \leq 0.01 m1∑i=1m∣∣x(i)∣∣2m1∑i=1m∣∣∣x(i)−xapprox(i)∣∣∣2≤0.01
不等式右边的0.01可以是0.05,或者0.1等,都是比较常见的。当为0.01的时候,表示保留了99%的方差数据,即大部分的数据特征被保留了。


当给定了个数k,协方差矩阵S中求解出来的各个特征值满足公式:
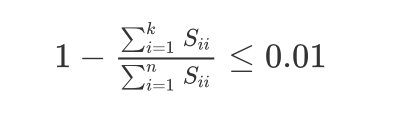
1 − ∑ i = 1 k S i i ∑ i = 1 n S i i ≤ 0.01 1- \frac{\sum^k_{i=1}S_{ii}}{\sum^n_{i=1}S_{ii}} \leq0.01 1−∑i=1nSii∑i=1kSii≤0.01
也就是满足:
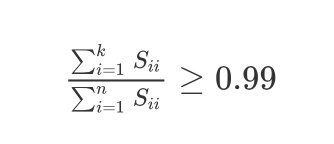
∑ i = 1 k S i i ∑ i = 1 n S i i ≥ 0.99 \frac{\sum^k_{i=1}S_{ii}}{\sum^n_{i=1}S_{ii}} \geq 0.99 ∑i=1nSii∑i=1kSii≥0.99
这个和上面的公式是等价的。
重建的压缩表示
重建的压缩表示Reconstruction from Compressed Representation指的是将数据从低维还原到高维的过程。
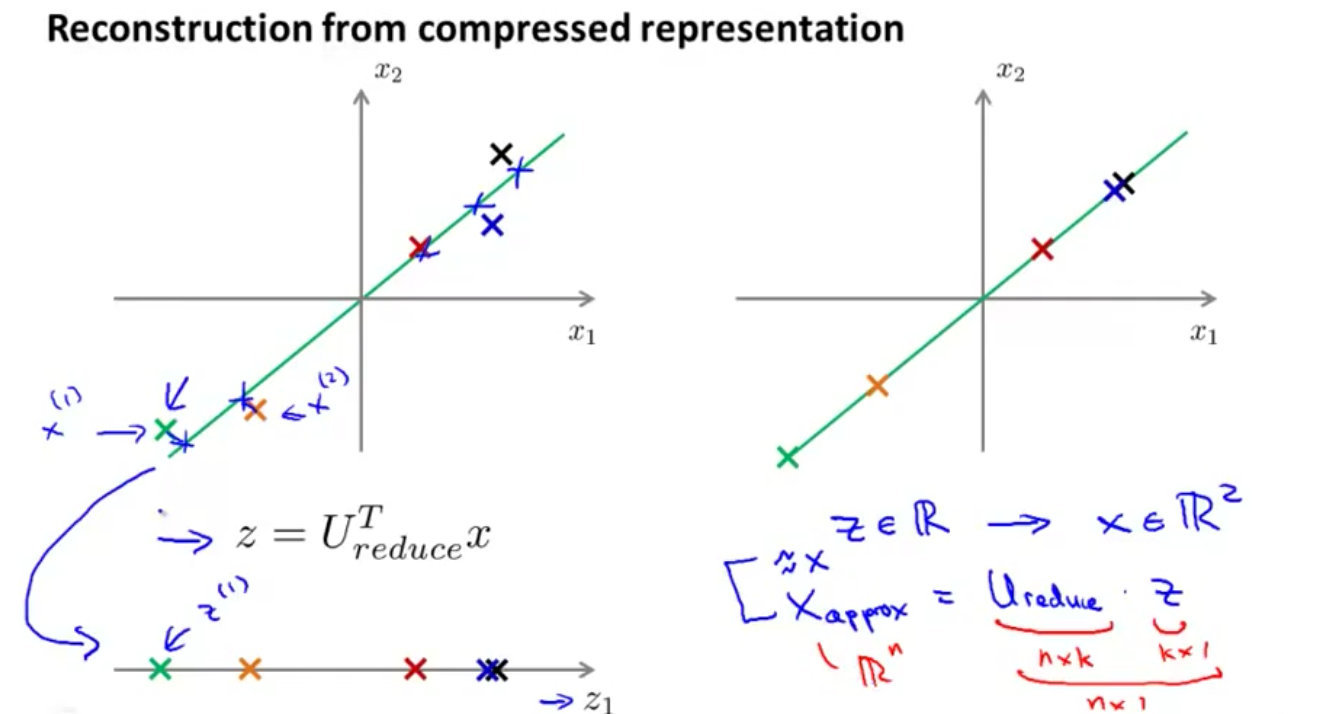
上图中有两个样本 s ( 1 ) , x ( 2 ) s^{(1)},x^{(2)} s(1),x(2)。通过给定的实数 z z z,满足 z = U r e d u c e T x z={U_{r e d u c e}^{T}} x z=UreduceTx,
将指定的点位置映射到一个三维曲面,反解前面的方程:
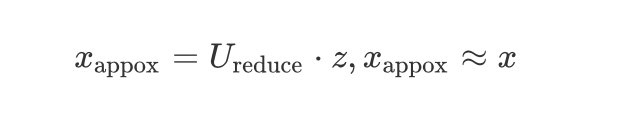
x appox = U reduce ⋅ z , x appox ≈ x x_{\text {appox}}=U_{\text {reduce}} \cdot z, x_{\text {appox}} \approx x xappox=Ureduce⋅z,xappox≈x
PCA特点
PCA本质上是将方差最大的方向作为主要特征,让这些特征在不同正交方向上没有相关性。PCA是一种无参数技术,不需要进行任何参数的调节
Python实现PCA
利用numpy、pandas、matplotlib库实现PCA算法
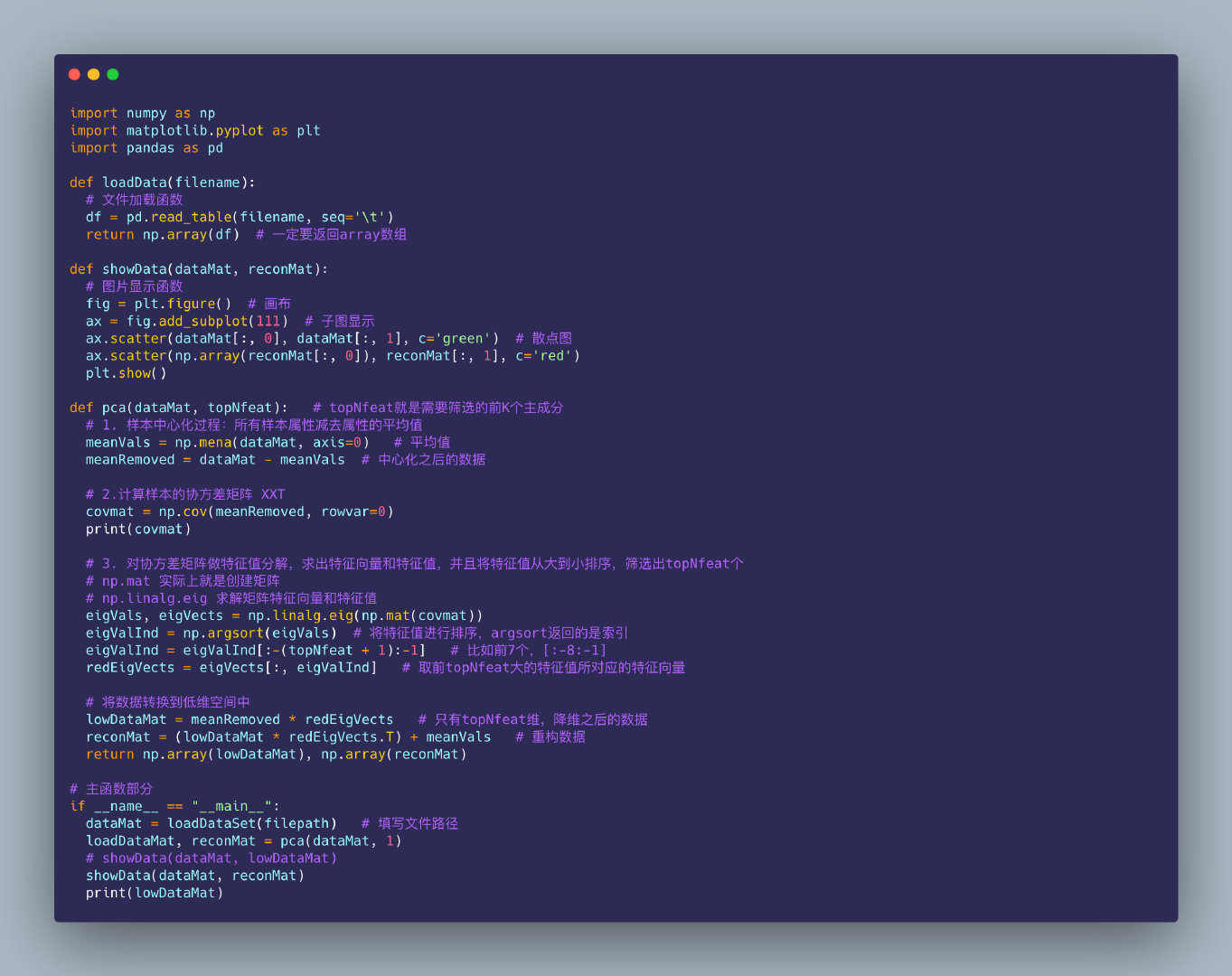
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
def loadData(filename):
# 文件加载函数
df = pd.read_table(filename, seq='\t')
return np.array(df) # 一定要返回array数组
def showData(dataMat, reconMat):
# 图片显示函数
fig = plt.figure() # 画布
ax = fig.add_subplot(111) # 子图显示
ax.scatter(dataMat[:, 0], dataMat[:, 1], c='green') # 散点图
ax.scatter(np.array(reconMat[:, 0]), reconMat[:, 1], c='red')
plt.show()
def pca(dataMat, topNfeat): # topNfeat就是需要筛选的前K个主成分
# 1. 样本中心化过程:所有样本属性减去属性的平均值
meanVals = np.mena(dataMat, axis=0) # 平均值
meanRemoved = dataMat - meanVals # 中心化之后的数据
# 2.计算样本的协方差矩阵 XXT
covmat = np.cov(meanRemoved, rowvar=0)
print(covmat)
# 3. 对协方差矩阵做特征值分解,求出特征向量和特征值,并且将特征值从大到小排序,筛选出topNfeat个
# np.mat 实际上就是创建矩阵
# np.linalg.eig 求解矩阵特征向量和特征值
eigVals, eigVects = np.linalg.eig(np.mat(covmat))
eigValInd = np.argsort(eigVals) # 将特征值进行排序,argsort返回的是索引
eigValInd = eigValInd[:-(topNfeat + 1):-1] # 比如前7个,[:-8:-1]
redEigVects = eigVects[:, eigValInd] # 取前topNfeat大的特征值所对应的特征向量
# 将数据转换到低维空间中
lowDataMat = meanRemoved * redEigVects # 只有topNfeat维,降维之后的数据
reconMat = (lowDataMat * redEigVects.T) + meanVals # 重构数据
return np.array(lowDataMat), np.array(reconMat)
# 主函数部分
if __name__ == "__main__":
dataMat = loadDataSet(filepath) # 填写文件路径
loadDataMat, reconMat = pca(dataMat, 1)
# showData(dataMat, lowDataMat)
showData(dataMat, reconMat)
print(lowDataMat)
sklearn中实现PCA
Linear dimensionality reduction using Singular Value Decomposition of the data to project it to a lower dimensional space. The input data is centered but not scaled for each feature before applying the SVD.
实现模块
在scikit-learn中,与PCA相关的类都在sklearn.decomposition包中。最常用的PCA类就是sklearn.decomposition.PCA。
白化:对降维后的数据的每个特征进行归一化,让方差都为1
class sklearn.decomposition.PCA(n_components=None, # 降维后的特征数目,直接指定一个整数
copy=True,
whiten=False, # 判断是否进行白化,默认是不白化
svd_solver='auto', # 指定奇异值分解SVD的方法
tol=0.0,
iterated_power='auto',
random_state=None)
demo
在这里讲解一个例子,利用PCA算法来进行IRIS数据的分类
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 3D模块
from sklearn import decomposition # 压缩模块
from sklearn import datasets
np.random.seed(5)
centers = [[1,1], [-1,-1], [1,-1]]
iris = datasets.load_iris() # 导入数据
X = iris.data # 样本空间
y = iris.target # 输出
fig = plt.figure(1, figsize=(4,3))
plt.clf()
ax = Axes3D(fig, rect=[0,0,.95,1], elev=48, azim=134)
plt.cla()
pca = decomposition.PCA(n_components=3)
pca.fit(X)
X = pca.transform(X)
for name, label in [('Setosa', 0), ('Versicolour', 1), ('Virginica', 2)]:
ax.text3D(X[y == label, 0].mean(),
X[y == label, 1].mean() + 1.5,
X[y == label, 2].mean(), name,
horizontalalignment = 'center',
bbox = dict(alpha=.5, edgecolor='w', facecolor='w'))
y = np.choose(y, [1,2,0]).astype(np.float)
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=y, cmap=plt.cm.nipy_spectral, edgecolor='k')
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
plt.show()















 6752
6752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









