






点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要9分钟
跟随小博主,每天进步一丢丢


转载自:知乎
链接:https://zhuanlan.zhihu.com/p/74515580
本文解读ACL 2019最新收录的论文:What does BERT learn about the structure of language?
链接:https://hal.inria.fr/hal-02131630/document
作者是来自于法国Inria机构的Ganesh Jawahar,Benoît Sagot和Djamé Seddah。探索BERT深层次的表征学习是一个非常有必要的事情,一是这可以帮助我们更加清晰地认识BERT的局限性,从而改进BERT或者搞清楚它的应用范围;二是这有助于探索BERT的可解释性,自从各国政府人工智能战略的相继发布,神经网络的可解释性问题成为了一个不可忽略的问题。
Frege早在1965年的组合原则里谈到,复杂表达式的意义由其子表达式的意义以及意义如何组合的规则共同决定。本文思路与分析卷积神经网络每层学习到的表征类似,主要是探索了BERT的每一层到底捕捉到了什么样的信息表征。作者通过一系列的实验证明BERT学习到了一些结构化的语言信息,比如BERT的低层网络就学习到了短语级别的信息表征,BERT的中层网络就学习到了丰富的语言学特征,而BERT的高层网络则学习到了丰富的语义信息特征。
1. BERT
BERT是构建于Transformer之上的预训练语言模型,它的特点之一就是所有层都联合上下文语境进行预训练。训练方法是通过预测随机隐藏(Mask)的一部分输入符号(token)或者对输入的下一个句子进行分类,判断下一个句子是否真的属于给定语料里真实的跟随句子。
作者使用了bert-base-uncased作为实验的基础,它由12层编码网络组成,每层的隐藏状态(hidden)尺寸为768,并且有12个注意力头(110M参数)。在所有的实验中,作者在每一层网络都使用第一个输入符号(‘[CLS]’)的输出来计算BERT的表征,这个输出通过自注意力机制汇聚了所有真实符号的信息表征。
2. 短语句法
基于循环神经网络LSTM的语言模型在2018年就曾被Peters et al.揭示了能够捕捉短语级别的结构信息,那么BERT在这一方面是否捕捉了短语级别的结构信息呢?为了探索这一疑惑,作者跟随Peters et al.的方法,首先给定一个输入符号序列 ,然后通过结合第一个和最后一个隐藏向量
计算第
层的跨度表征
。

(图2-1. BERT第1、2、11、12层跨度计算的二维t-SNE图)

(图2-2. BERT不同层的跨度表征聚类图)
图2-1是利用t-SNE对跨度表征可视化的结果,t-SNE是一个用于可视化高维数据的非线性降维算法,我们可以观察到BERT在低层网络捕捉了短语级别的结构信息,然后随着网络层数的加大,短语级别的结构信息逐渐消失。举个例子,底层网络会将块(如“to demonstrate”)的潜在分类(如“VP”)映射到一起。
作者进一步通过聚类算法k-means量化这个证明。如图2-2所示,作者使用归一化互信息(Normalized Mutual Information,NMI)展示了低层网络在编码短语级别的结构信息上优于高层网络。
3. 探测任务
探测任务(Probing Tasks)能够帮助挖掘编码在神经网络模型中的语言学信息。作者使用探测任务来评估每层神经网络编码不同类型语言学特征的能力。
作者使用十个句子级别的探测任务,这些探测任务被分为三组:
1)表层任务:句子长度(SentLen)探测,单词在句子中存在探测(WC);
2)句法层任务:词序敏感性(BShift),句法树深度(TreeDepth),句法树顶级成分序列(TopConst);
3)语义层任务:时态检查(Tense),主语数量(SubjNum),名词动词随机替换敏感度(SOMO),协作分句连词的随机交换(CoordInv)。
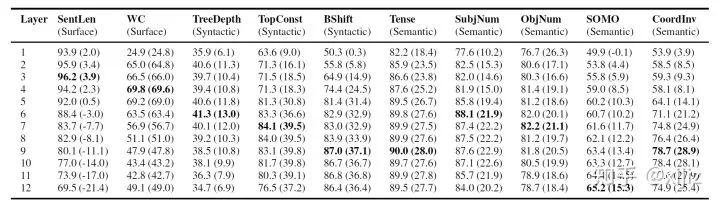
(图2-3. 探测任务在BERT不同网络层的性能表现(括号里的值是未训练与训练过的BERT的差值))
如图2-3所示,BERT编码了丰富的语言学层次信息:表层信息特征在底层网络,句法信息特征在中间层网络,语义信息特征在高层网络。作者也发现未训练版本BERT的高层网络在预测句子长度任务(SentLen)上超过了训练过的版本,这暗示着未训练的BERT模型可能包含足够的信息去预测基本的表层特征。
4. 主谓一致
主谓一致(Subject-verb agreement)是一个探测神经网络模型是否编码句法结构的代理任务。当句子中有更多相反编号(attractors)的名词插入到主语和动词中时,预测动词编号的任务会逐渐变得困难。作者在BERT的每一层网络使用不同的激励(Stimuli)来测试BERT是否学习到较好的句法结构信息。
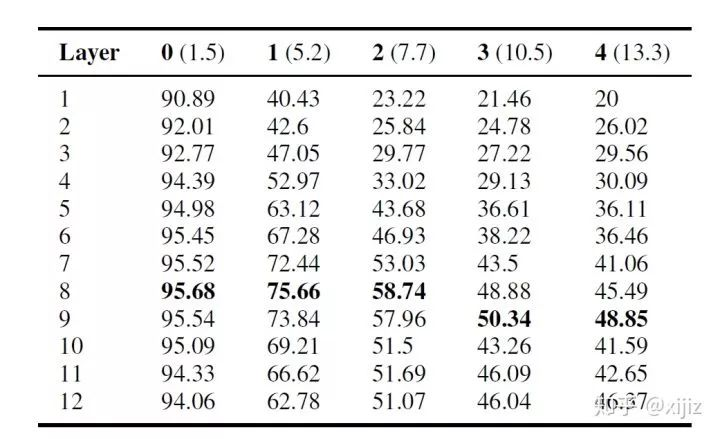
(图2-4. BERT每一层主谓一致得分情况表)
如图2-4所示,该表是主谓一致得分表,第二列到第六列是在主语和动词插入的名词数量,括号里面的数字是主语到谓语动词的平均距离。结果表明在大多数情况下,中间层网络表现得更好,这也印证了上一部分句法特征主要在BERT中间层进行编码的假设。
有趣的是,随着插入名词的增多,BERT更高层的网络也逐渐能够处理长程依赖问题,效果要比低层网络更好,这证明BERT只有有更深的层数才能在大多数自然语言处理(NLP)上更有竞争力。
5. 组合结构
为了进一步探索BERT是否能够学习到组合结构的特征,作者使用Tensor Product Decomposition Networks(TPDN)来对BERT进行调查,TPDN通过基于使用张量乘积和的预先选择的角色设计(role scheme)来组合输入符号表示。一个单词的角色设计可以是基于从语法树根节点到它自身的路径,比如LR代表根节点的左孩子的右孩子。
作者假设,对于一个给定的角色设计,如果一个TPDN模型能够很好地被训练去估计一个神经网络学到的表征,那么这个角色设计就很可能能够确定这个神经网络模型学到的组合性特征。对于BERT的每层网络,作者使用五种不同的角色方案:left-to-right,right-to-left,bag-of-words,bidirectional以及tree。
作者使用SNLI语料库的premise句子来训练TPDN模型,并使用均方误差(MSE)作为损失函数。

(图2-5. 均方误差图)
如图2-5所示,该图是TPDN以及BERT表征和角色设计之间的均方误差,这表明尽管BERT只使用了注意力机制,但是它的高层网络依然学习到了某种树形结构。
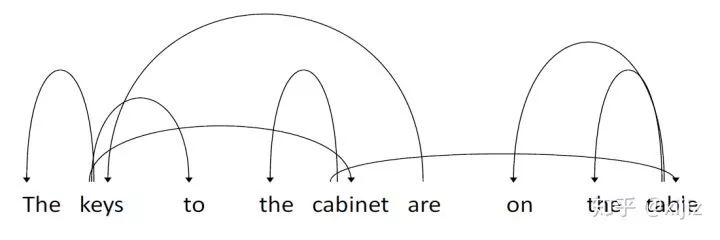
(图2-6. 依赖解析树示意图)
受到这个研究的启发,作者从自注意力机制权重中推导出了依赖树。如图2-6所示,该图展示了通过BERT第二层网络第11个注意力头的自注意力推导出句子“The keys to the cabinet are on the table”的依赖树,根节点从are开始。我们可以从图中看出一些限定词依赖,比如“the keys”,“the cabinet”以及“the table”;也可以看出主语谓语依赖,比如“keys”和“are”。
推荐阅读:
【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器

我就知道你“在看”


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









