






点击下面卡片,关注我呀,每天给你送来AI技术干货!
知乎:潘小小
职位:字节跳动AI Lab NLP算法工程师
方向:多语言机器翻译
深度学习自然语言处理公众号出品

文本预训练系列是我的专栏《小小的机器世界》中的一个重要子系列,系列里包含了文本预训练历程中有重要影响和意义的预训练框架的详细讲解,每篇都从insight的角度进行了深入的讲解。本篇目的是从预训练模型的发展历程中,挖掘出一些作者们思路的脉络。希望读者看完本文后可以理解预训练发展的动力,以及论文的作者们是如何从现有模型的优缺点出发,改进预训练目标(pre-training objective)而发明新模型的。在后续的文章中,我还会介绍多语言预训练的相关工作,敬请期待。
从GPT和BERT到XLNet
从BERT和XLNet到MPNet
NLU任务的预训练 VS NLG任务的预训练
在开头先列出本文中涉及到的名词缩写
PTM: Pre-train Model, 预训练模型
LM: Language Model,语言模型
AR: Auto-Regressive,自回归
AE: Auto-Encoding,自编码
CLM: Causual Language Model
MLM: Masked Language Model
PLM: Permuted Language Model
NLU: Natural Language Understanding
NLG: Natural Language Generation
1. 什么是预训练
如果想用一句话讲清楚“预训练“做了一件什么事,那我想这句话应该是“使用尽可能多的训练数据,从中提取出尽可能多的共性特征,从而能让模型对特定任务的学习负担变轻。“
要想深入理解预训练,首先就要从它产生的背景谈起,第一部分回答了这样2个问题:预训练解决了什么问题,怎样解决的。
1.1. 预训练诞生的背景
“预训练“方法的诞生是出于这样的现实:
标注资源稀缺而无标注资源丰富: 某种特殊的任务只存在非常少量的相关训练数据,以至于模型不能从中学习总结到有用的规律。
比如说,如果我想对一批法律领域的文件进行关系抽取,我就需要投入大量的精力(意味着时间和金钱的大量投入)在法律领域的文件中进行关系抽取的标注,然后将标注好的数据“喂”给模型进行训练。但是即使是我标注了几百万条这样的数据(实际情况中,在一个领域内标注几百万条几乎不可能,因为成本非常高),和动辄上亿的无标注语料比起来,还是显得过于单薄。“预训练”这时便可以派上用场。

现实中,特定任务的标注数据量远远少于无标注数据的量:右边的黑色柱子代表特定领域标注的语料量,蓝色柱子代表无标注数据的语料量,它们之间的差距比图示还要悬殊得多。
1.2. 预训练思想的本质
如果用一句话来概括“预训练”的思想,那么这句话可以是
模型参数不再是随机初始化,而是通过一些任务(如语言模型)进行预训练
将训练任务拆解成共性学习和特性学习两个步骤
上面的两句分别从两个不同的角度来解释了预训练思想的本质。第一句话从模型的角度,第二句话从数据的角度。下面展开讲讲第二种解释。
【学习任务的分解】
“预训练“的做法一般是将大量低成本收集的训练数据放在一起,经过某种预训方法去学习其中的共性,然后将其中的共性“移植”到特定任务的模型中,再使用相关特定领域的少量标注数据进行“微调”,这样的话,模型只需要从”共性“出发,去“学习”该特定任务的“特殊”部分即可。
其实举一个最简单的身边的例子大家就懂了,让一个完全不懂英文的人(我们称ta为)去做英文法律文书的关键词提取的工作会完全无法进行,或者说ta需要非常多的时间去学习,因为ta现在根本看不懂英文。但是如果让一个英语为母语但是没接触过此类工作的人(我们称ta为B)去做这项任务,ta可能只需要相对比较短的时间学习就可以上手这项任务。在这里,英文知识就属于“共性”的知识,这类知识不必要只通过英文法律文书的相关语料进行学习,而是可以通过大量英文语料,不管是小说、书籍,还是自媒体,都可以是学习资料的来源。
因此,可以将预训练类比成学习任务分解:在上面这个例子中,如果我们直接让A去学习这样的任务,这就对应了传统的直接训练方法。如果我们先让A变成B,再让ta去学习同样的任务,那么就对应了“预训练+微调”的思路。
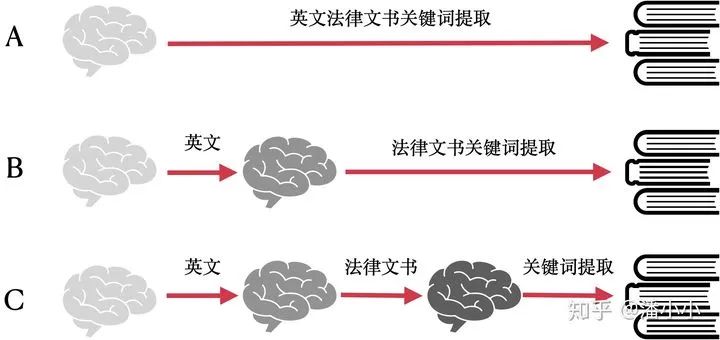
A是传统的训练思路,B和C都是预训练+微调的训练思路
在上面的例子中,B的学习路径是先学习英文,再学习法律文书关键词提取。而图中的C是将“法律文书关键词提取”任务进一步分解成为“法律文书”+“关键词提取”,先学习英文的法律文书领域的知识,再去学习如何在英文的法律文书领域做关键词提取。
很显然,从“英文法律文书”出发的学习速度 > 从“英文”出发的学习速度 > 从0出发的学习速度。其实采用“预训练”思路的B和C,不仅仅是学习速度高于A,更重要的是,他们的学习效果往往好于A。
这就和机器学习领域的“预训练”不谋而合。
2. 预训练的发展历程
NLP进入神经网络时代之后。NLP领域中的预训练思路可以一直追溯到word2vec的提出[1]。
第一代预训练模型专注于word embedding的学习(word2vec),神经网络本身关于特定任务的部分参数并不是重点。其特点是context-free,也即word embedding,每个token的表示与上下文无关,比如“苹果”这个词在分别表示水果和公司时,对应的word embedding是同样的。
第二代预训练模型以context-aware为核心特征,也就是说“苹果”这个词在分别表示水果和公司时,对应output是不一样的,其中具有代表性的有ELMo[2], GPT[3], BERT[4]等。
需要提一点的是,早期的PTMs研究者们在模型结构上做的尝试比较多,比如ELMo使用了双向LSTM。然而在Transformer出现后,研究者们研究的重点就从模型结构转移到了训练策略上。比如GPT和BERT都是基于Transformer结构的: GPT基于Transformer decoder,而BERT基于Transformer encoder。因此,本篇文章也是侧重于解释不同的训练策略。
3. NLU任务的预训练 VS NLG任务的预训练
NLP领域主要分为自然文本理解(NLU)和自然语言生成(NLG)两种任务。何为理解?我看到一段文字,我懂了它的意思,但是只需要放在心里----懂了,但不需要说出来。何为生成?我看到一段文字,我懂了它的意思,并且能够用语言组织出我理解的内容----懂了,还需要说出来。
3.1. 文本理解(NLU)和文本生成(NLG)任务
常见的NLU benchmark有GLUE[5]: 包含九项NLU任务,语言均为英语。涉及到自然语言推断、文本蕴含、情感分析、语义相似等多个任务。
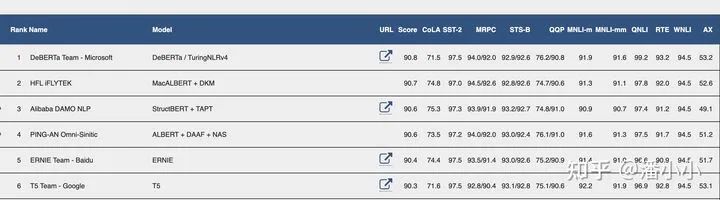
GLEU leaderboard前几位(https://gluebenchmark.com/leaderboard)
常见的NLG任务则有: 机器翻译,摘要生成,对话系统,等等。
Machine Translation
(Abstractive) Summarization
Dialogue (chit-chat and task-based)
Creative writing: storytelling, poetry-generation
Freeform Question Answering (i.e. answer is generated, not extracted from text or knowledge base)
Image captioning
4. 预训练方法
4.1. 两种基本范式:自回归(AR)预训练和自编码(AE)预训练
在预训练语言模型的学习过程中,我们往往最早会接触到GPT和BERT。实际上,GPT和BERT代表了两种最基本的预训练范式,它们分别被称作“自回归预训练“(如GPT)和“自编码预训练”(如BERT),各自适用于不同类型的下游任务,其中GPT往往更适合文本生成任务,BERT往往更适合文本理解任务。两者都是基于Transformer结构的部分参数。
GPT对应了decoder的预训练,而BERT对应了encoder的预训练。
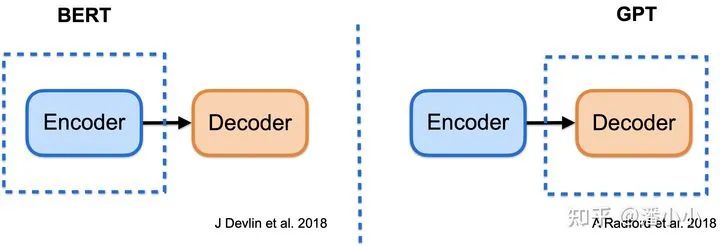
4.1.1. GPT --> AR/LM,适用于NLG任务
GPT这一缩写来自于Generative Pre-Training,也就是生成式预训练,这个名称已经预示着GPT擅长文本生成任务。
GPT的优化目标是单向(从左到右或者从右到左)建模序列的联合概率,是传统意义上的语言模型,后预测的词以先预测的词为条件,比较适合文本生成任务,但是缺陷是只使用了单向的语言表征信息,无法获取双向上下文信息表征,而文本理解任务中经常需要用到双向的上下文信息(比如,完形填空),因此,这就带来了pre-train阶段和下游NLU任务的不一致。
4.1.2. BERT --> AE/MLM,适用于NLU任务
BERT的全称为Bidirectional Encoder Representations from Transformers,名称中强调了“双向表示”,预示着BERT是双向建模的。BERT双向建模的方式就是将一些位置的token替换成特殊的[MASK]字符,并且在目标端去预测这些被替换的字符。BERT的特点在于它在预训练阶段已经使用了双向上下文信息,因此特别适合NLU任务。
4.2. 从GPT和BERT出发: XLNet, MPNet
由GPT和BERT这两个基本的预训练范式出发,后面一些工作致力于将两者的优点结合,做出一个既适用于NLG又适用于NLU的“大一统”预训练模型。其中的代表有:
XLNet, 提出Permuted Language Model (PLM),将GPT的从左向右建模扩展成乱序建模,来弥补GPT无法获取双向上下文信息的缺陷[6]。
MPNet, 在XLNet基础上进一步弥合pre-train阶段和下游任务fine-tune阶段的预训练目标,试图统一PLM和MLM[7]
4.3. MASS
MASS = Soft mix (BERT, GPT)[8]
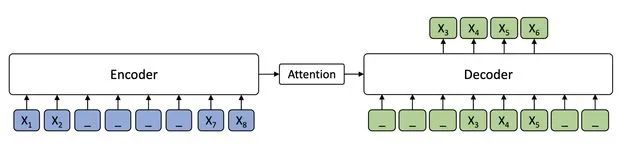
4.4. BART
2020年,FAIR提出了BART预训练,其特征在于它使用了"Arbitrary Noise Transformation"。包含5种Noise[8]
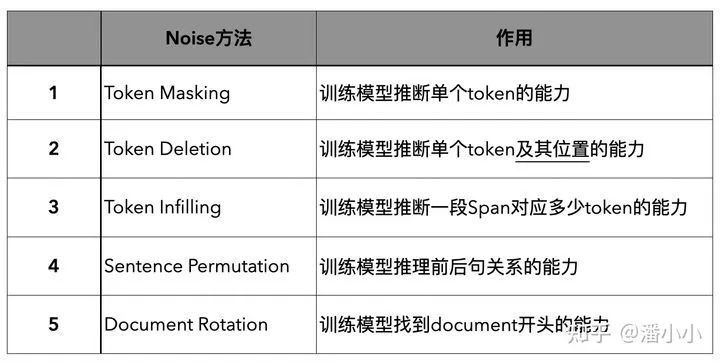
BART使用的5种Noise
5. 总结
我在下面的表格里总结了一下上面提到的PTMs的训练目标、模型结构、论文提出的背景是为了针对性地解决什么场景的问题、受哪些前期工作的影响。
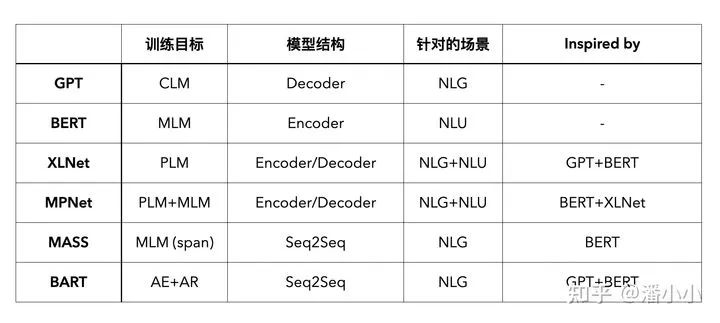
** Encoder/Decoder指的是,训练目标不是Encoder的(双向建模),也不是Decoder的(单向建模),但是模型结构和Encoder或者Decoder是一样的。



作者:潘小小
字节跳动AI-Lab NLP算法工程师,目前专注多语言机器翻译,法国留学文艺女青年,现居上海。知乎id: 潘小小
参考
Efficient Estimation of Word Representations in Vector Space, 2013 https://arxiv.org/abs/1301.3781
ELMo https://www.aclweb.org/anthology/N18-1202/
GPT https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
BERT https://www.aclweb.org/anthology/N19-1423/
GLUE https://www.aclweb.org/anthology/W18-5446/
【论文串讲】从GPT和BERT到XLNet https://zhuanlan.zhihu.com/p/182377100
【论文串讲】从BERT和XLNet到MPNet https://zhuanlan.zhihu.com/p/197675066
【论文精读】生成式预训练之MASS https://zhuanlan.zhihu.com/p/360998333
nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet) https://zhuanlan.zhihu.com/p/76912493
NLP算法面试必备!史上最全!PTMs:NLP预训练模型的全面总结 https://zhuanlan.zhihu.com/p/115014536
多项NLP任务新SOTA,Facebook提出预训练模型BART https://zhuanlan.zhihu.com/p/90173832
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









