






每天给你送来NLP技术干货!
来自:哈工大讯飞联合实验室
作者:赵峻瑶
本期我们面向句子表示学习任务(Sentence Representation Learning),对近期具有代表性的句子表示学习方法进行鉴赏。
•••
引言
句子向量表示是将一句文本经过特征提取后得到一个定长的向量,使该向量在语义空间内准确表示该句文本的语义。句子表示模型可以作为多数NLP任务的基石,结合分类层或匹配方法即可作为对应任务的基本方案。可应用的任务场景:句子检索,相似句判断,语义推断等等。
句子表示学习旨在拉近相似句表示之间的距离,拉开不相似句子表示之间的距离,同时希望句子表示向量能够均匀分布在表示空间。
根据句子表示学习方法各自的特点,本期将近期方法按以下方式划分,并选择各类别下具有代表性的工作展开介绍。
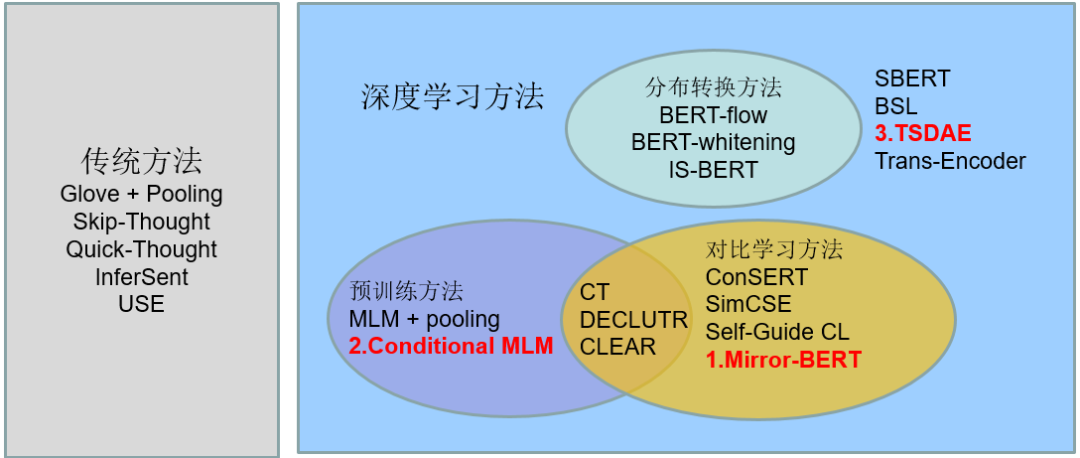
Fast, Effective, and Self-Supervised: Transforming Masked Language Models into Universal Lexical and Sentence Encoders
剑桥大学的Fangyu Liu等人在EMNLP2021上发表的一篇文章,为了解决在没有监督数据情况下,预训练的掩码语言模型(MLM)在通用的基于词和句子的编码上效果不佳的问题,该工作使用对比学习方法对预训练MLM进行自监督微调,不依赖监督数据将已有的预训练MLM转化为一个有效的词句编码器。
1.1 方法概述
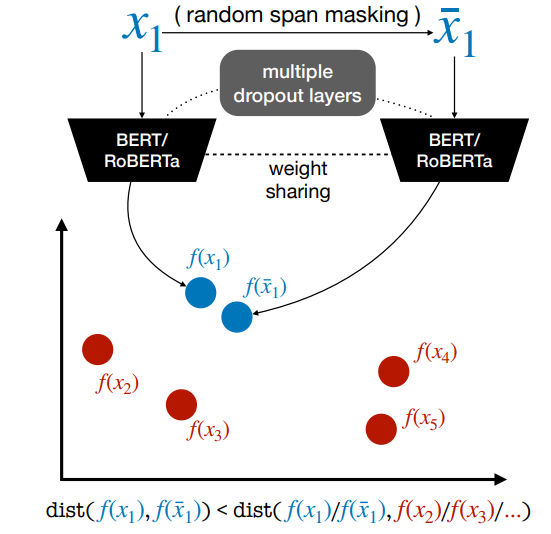
在特征层面进行微小的变化得到正例相似句
本文提出了一种命名为Mirror-BERT的对比学习框架,对近期出现的不同对比学习方法进行归纳总结。
对比学习训练,使用InfoNCE[1]损失函数作为训练目标,旨在一个batch内拉近和当前句子相似句子的表示,推开不相似句子的表示,由余弦相似度来度量句子表示之间的距离:
在对比学习中,构造出多样且高质量的正例对是关键,这里列出了图一中近期各对比学习方法使用的正例构造方法,主要分为2个层面:
文本输入层面的修改
随机删除词(ConSERT[2],CLEAR[3])
随机删除连续词(ConSERT,CLEAR,Mirror-BERT)
打乱输入顺序(ConSERT,CLEAR)
同义词替换(CLEAR)
特征层面构造不同视角
随机掩盖某一维特征(ConSERT)
两次不同的Dropout结果(ConSERT,SimCSE,Mirror-BERT)
增加噪声扰动(ConSERT)
由2个不同模型提供不同视角的特征(Self-Guide Contrastive Learning[4],CT[5])
本文Mirror-BERT主要使用了随机删除连续词和dropout策略来构造正例,dropout也被其他工作证明为简单有效的对比学习正例构造方式。从近期对比学习的相关工作来看,不对原句做过多的破坏能保证构造正例的质量,在不考虑训练效率的情况下,额外训练一个模型提供另一视角下的句子表示也被证明有效。
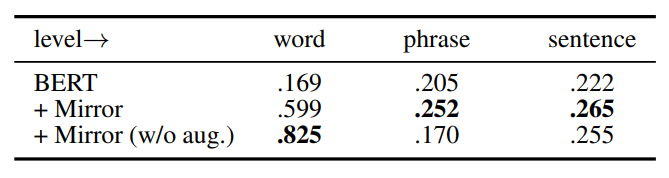
1.2 实验评估
本文考察了Mirror-BERT在词和句子的通用表示效果,分别在Multi-SimLex和STS数据集上进行测试,训练使用对应数据集下10k的无标签训练集。
表1 Multi-SimLex词相似度评估实验。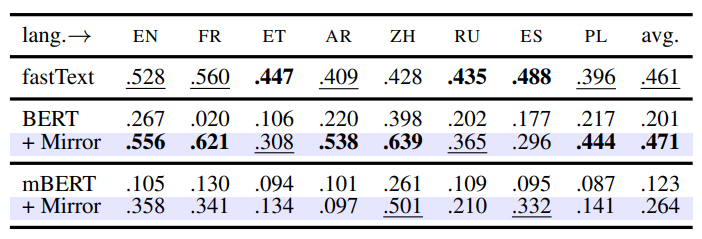
表2 STS句子相似度评估实验。
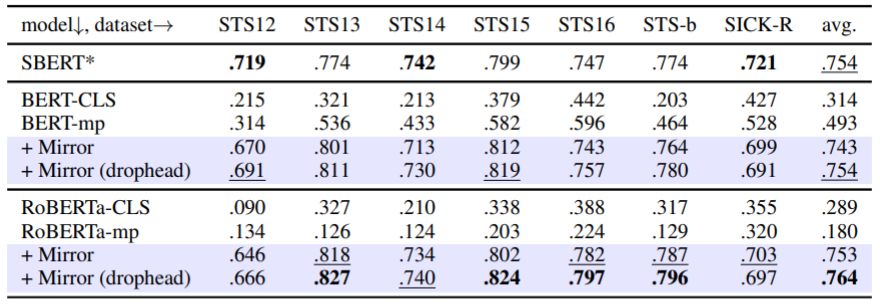
从表1,表2中可以看到Mirror-BERT能将已有的预训练MLM转化成强大的词或句子编码器,且对多语种MLM也有效。在句子相似评估实验中,还实验了drophead策略,即随机掩盖一些自注意力head,取得了更优的效果,这说明Mirror-BERT是一种通用的强化MLM句子表示能力的自监督学习框架,也适用于其他正例构造方法。SBERT是由SNLI和MultiNLI的监督数据进行训练的方法,BERT+Mirror(drophead)已经能够在平均效果上与其持平,并在个别数据集上有所超越,说明Mirror-BERT在通用的相似句评估任务上十分有效。
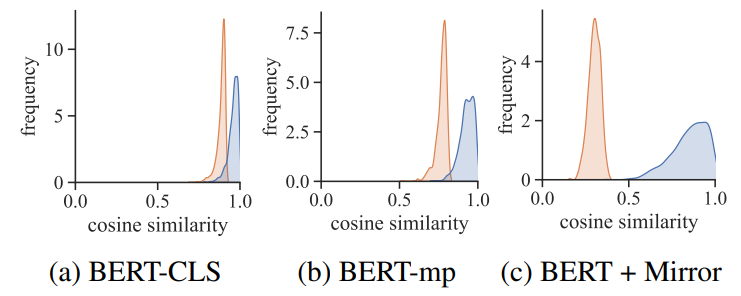
图3 各项同性定性分析。
为了验证Mirror-BERT是否在表示空间下更具有各向同性,首先在图3画出了不同方法正负例对之间的相似度分布,橙色表示负例,蓝色表示正例,可以看出Mirror-BERT方法得到的正例相似分数和负例相似分数间隔更大。从定量分析的角度还根据各项同性分数来进行计算,计算公式如下:
从表3的定量分析结果也可以得出,Mirror-BERT更具有各向同性,且只用Mirror-BERT这种微调方式来推开负例,在词和句子级别上也对各向同性分数有所提升。
表4 Mirror-BERT在无语义语料训练,在Multi-SimLex测试的结果。
1.3 结论
本文提出了Mirror-BERT,一种简单、高效的自监督的转换方法,将MLM转换成通用的词和句子编码器。该转换方法有效原因是MLM本身掌握了一定的知识,通过这种微调将这些知识得以充分运用,针对语义相似任务效果显著提升,模型的各向同性也得到提升。
Universal Sentence Representation Learning with Conditional Masked Language Model
斯坦福大学的Ziyi Yang等人在EMNLP2021上发表的一篇文章,为了强化掩码语言模型MLM在预训练过程中对整句的归纳能力,借鉴Skip-Thought和T5的思想,提出一种Conditional MLM预训练任务,在预训练阶段引入对整句归纳的偏置,使预训练后得到的模型更适合于对句子的编码。
2.1 方法概述
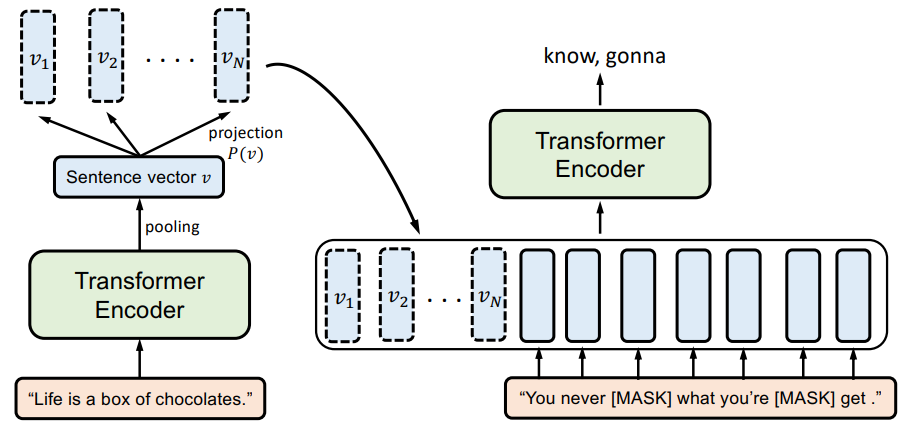
为了在预训练任务中引入对整句归纳的偏置,本文设计了如图4的CMLM模型结构和对应的预训练策略:
先由Transformer编码器对前一句进行编码和池化,得到句子级的向量,再映射到N维的序列表示,和后续待复原的句子的embedding拼接,再经过一个参数共享的Transformer编码器,在待复原的句子上进行原始的MLM预训练。
为了使模型学到双向的信息,50%概率交换前后两句,本文的训练策略下,待复原句子中约31.3%的token被掩盖。
这里第一点是强化模型在预训练中将整句总结成定长向量,以及基于该句子向量的信息进行推理的能力。预测时直接由CMLM模型对输入文本进行编码得到向量。
在多语种预训练时增加了双语检索对齐的损失,使用Additive Margin Softmax,计算公式如下:
是正例之间的间距,B是batch大小,并设置了3种结合双语检索任务的方式:
CMLM+BR:多任务学习CMLM和BR两个目标,BR的损失权重设置为0.2。
CMLM->BR:先预训练CMLM,再训练双语检索任务。
CMLM->CMLM+BR:先预训练CMLM,再多任务训练。
2.2 实验评估
实验设置:英语实验使用SentEval benchmark的分类任务和语义相似任务数据,多语种实验使用XEVAL数据,由SentEval翻译到其他14种语言。CMLM的维度N设置为15,双语检索损失的margin 设置为0.3,batch大小B设置为2048。在分类测试集上模型只微调输出层,在部分零样本学习的测试集上直接用余弦相似度作为输出。
表5 SentEval分类任务实验结果。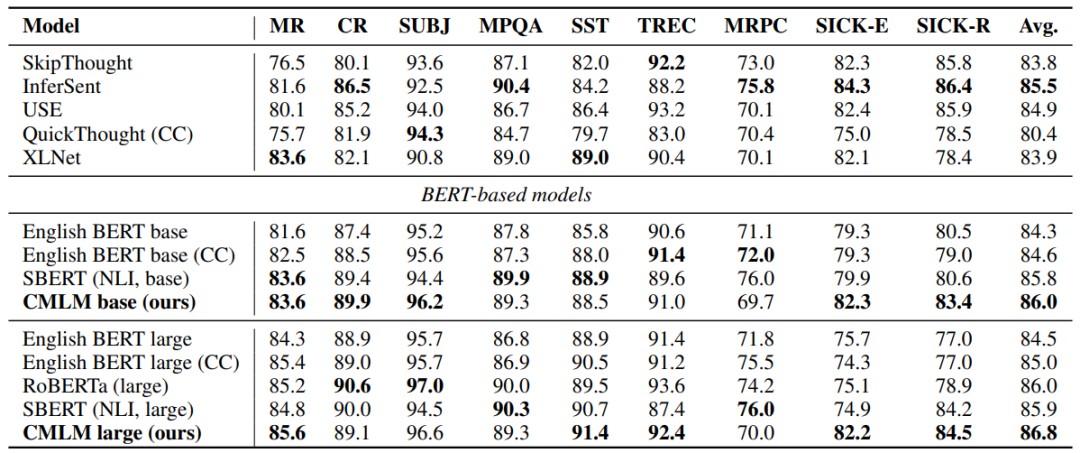
表6 SentEval语义相似任务实验结果,计算Spearman相关系数,其中SICK-R是零样本测试集,直接使用余弦相似度作为输出。

从表5和表6中能够看到比原始的MLM模型都有明显的提升,也比SBERT使用SNLI的监督数据进行微调的方法在平均效果上要好,说明在预训练阶段加入归纳和推理的偏置能够增强编码器对句子的表示能力。
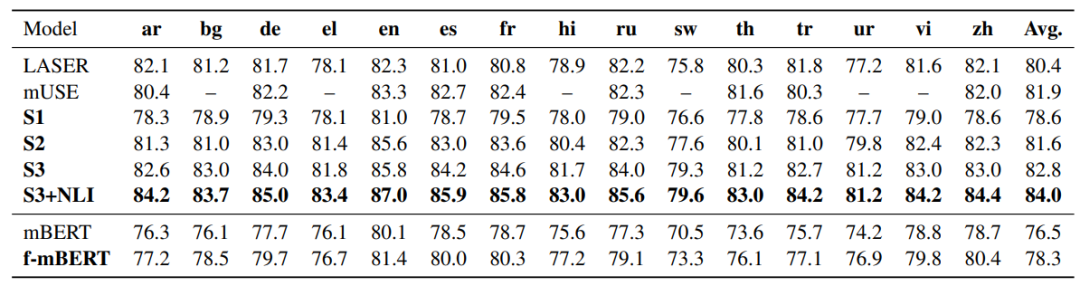
表7中的结果说明S3方法效果最优,且增加多语种的NLI监督数据能对多语种CMLM有着较大提升。这里还对mBERT增加CMLM和BR的微调进行实验,在mBERT的基础上也有了一定的提升,说明该方法同样是一个有效的自监督微调框架,能将已有的MLM模型进行微调,更适应于基于句子表示的匹配任务。
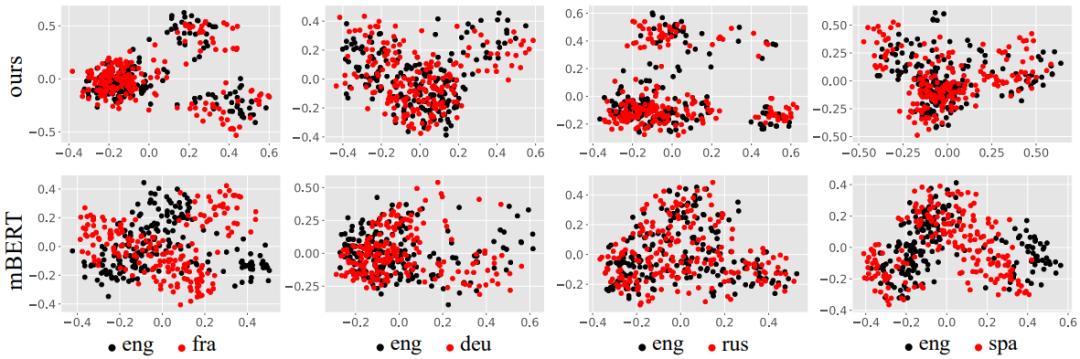
图5 多语种CMLM和mBERT的跨语言句子编码在Tatoeba数据集上的可视化结果。
从图5中可以看到CMLM句子表示的对齐性更具有跨语言性,即语义相近的句子不分语种,在法语和俄语上更为明显,而mBERT还是会存在于对齐性与语种相关的现象,同语义的句子在两个语种下得到的表示距离并不足够近。
2.3 结论
本文提出了一种Conditional MLM预训练方法以及多语种训练方法,基于相邻句子表示,来预测当前句子中被掩盖的token,将对整句文本的归纳能力和基于整句信息的推理能力在预训练过程中进行强化。在多语种设置下结合平行语料在预训练中加入跨语言对齐的loss,能够有效提升多语种句子编码质量,并且使同语义的句子在不同语种下有更好的对齐性。
TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding
达姆施塔特工业大学的Kexin Wang等人在Findings of EMNLP 2021上发表的一篇工作,为了解决语义相似监督数据稀缺的问题,提出一种基于Transformer的序列降噪自编码器(TSDAE)的无监督方法,来提升句子表示能力,并且还讨论了当前语义相似度评估方案的不合理之处,提出了新的评估方案。
3.1 方法概述
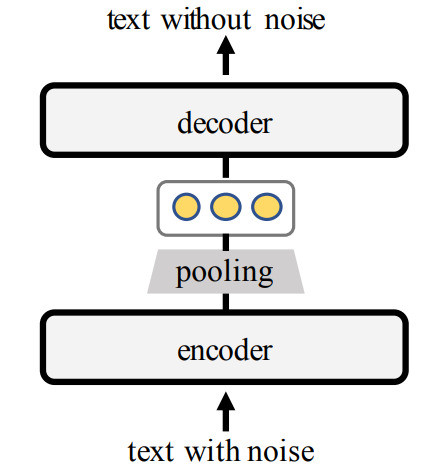
图6 TSDAE模型结构。
TSDAE模型结构为2个参数共享的Transformer构成的降噪自编码器,为了增强模型的句子编码能力和基于编码的推理能力,这里解码器只依赖于句子的编码[CLS]处的表示恢复原句。引入噪声使用随机删除和交换单词两种策略,模型的训练目标是基于噪声输入恢复原始输入:
现有的语义相似评估方法存在的问题有:
STS数据集的构造过于通用,大部分来自新闻和图片描述,不依赖明确的知识即可做好,也不清楚在目标领域下的任务效果如何。
人工构造的分数分布过于均匀,相似的数据和不相似的数据对数量接近,这和真实世界中的应用场景存在较大偏差,真实场景中一般仅有一小部分是相似的,例如检索场景,相似文本过滤场景,都需要从库中找到极少的相似文本。
同时考虑到真实场景也存在一小部分标注数据,本文设置了以下3种评估设置:
无监督学习评估:只使用目标任务中的无标注数据。
领域迁移评估:使用NLI和STS benchmark的监督数据,和目标任务的无监督数据。
预训练能力评估:有更大集合的无监督数据和目标任务中少量的标注数据。
3.2 实验评估
针对上述的语义相似评估问题,本文使用了表8中新的测试集进行评估,各测试集简介如下:
AskUbuntu:相似问题检索,从20个候选问题列表中进行精排。
CQADupStack:从候选池中检索出重复问题。
SciDocs:科学论文检索,给定检索,从30个候选中选出5个最相关的论文。
TwitterPara:判断给定的文本对是否是语义一致。
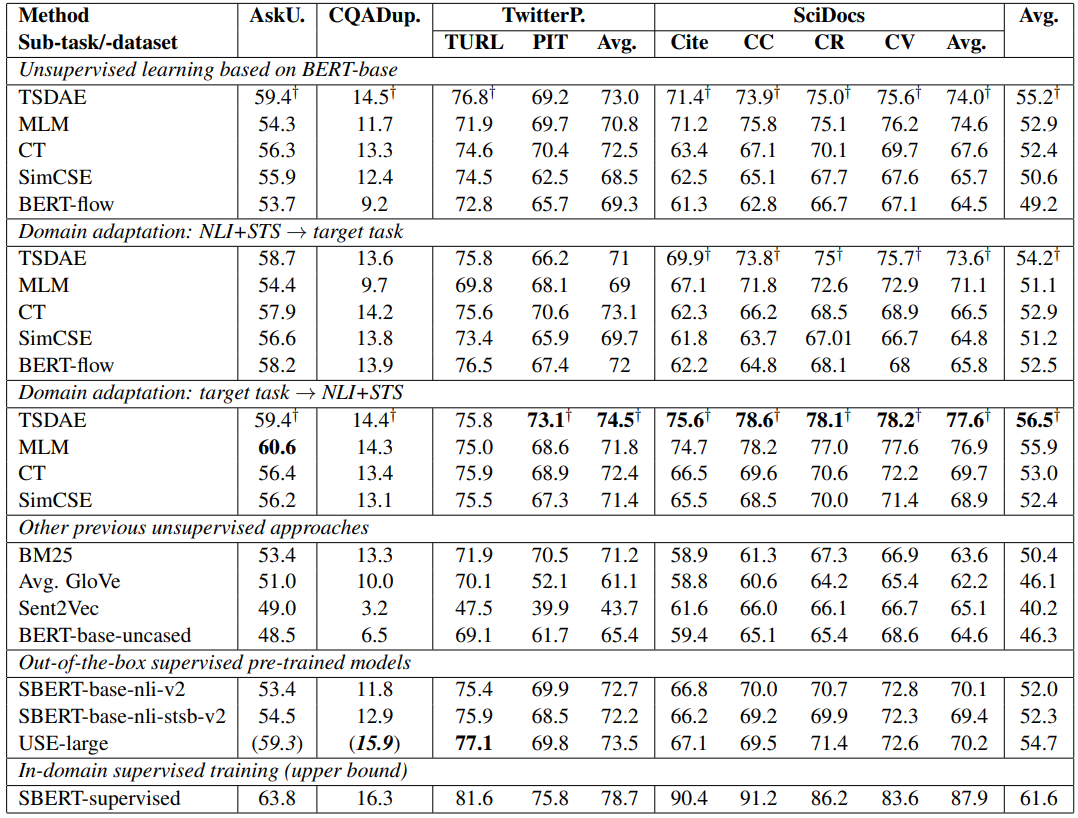
表10 STS benchmark测试结果,计算Spearman相关系数的平均,对比表9中的具体任务平均指标。
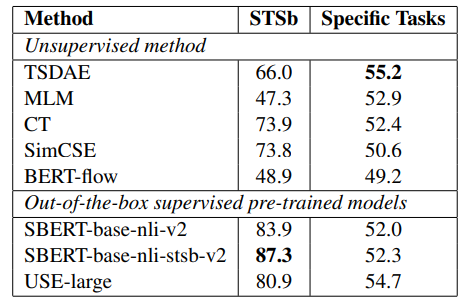
在STS数据上,CT和SimCSE效果远超过其他,但是在具体任务的新数据集上效果不是最优,这说明STS测试集与真实下游场景效果存在偏差。TSDAE在多个数据集上的指标得出比其他Unsupervised方法更优,可能得益于SDAE在训练时降噪恢复带来的鲁棒性,因为在CT和SimCSE的训练过程中都是使用未做显式修改的句子做输入的。
领域迁移设置下有两种策略,先用目标任务无监督数据训练,再用监督数据微调和先用监督数据微调,再用目标任务无监督数据,所有方法基本都比只用无监督数据效果有所提升,但前者效果更优。
Out-of-the-box设置是使用预训练模型在集外监督数据上训练的方法,直接在目标数据集上测试,USE-large在AskU.和CQADup.数据上的带括号的结果是直接使用了训练集,可见无监督设置下的TSDAE是比SBERT在集外监督数据上训练效果更优。
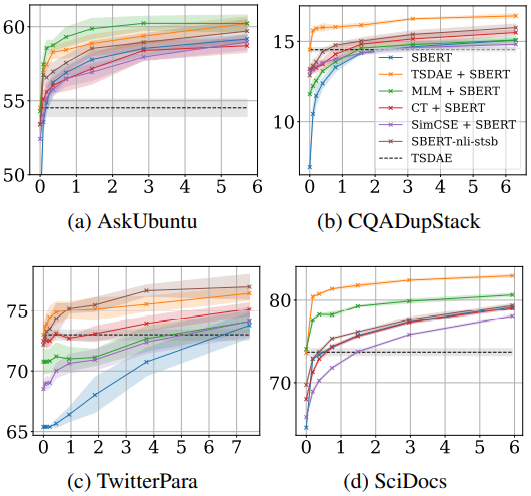 图7 预训练评估设置下对比不同方法的效果随微调数据量的变化。
图7 预训练评估设置下对比不同方法的效果随微调数据量的变化。
预训练评估设置下是先由各自模型结构在同样的语料下进行预训练,再由SBERT的训练方式在监督数据上进行微调,观察效果随微调数据量的变化。其中,TSDAE+SBERT方式微调效果在CQADup.和SciDocs2个数据集上效果最佳,说明TSDAE对于句子表示学习同样是一种有效的预训练结构,且能够有效借助监督数据进行效果提升。
表11 TSDAE各预训练模型打底效果。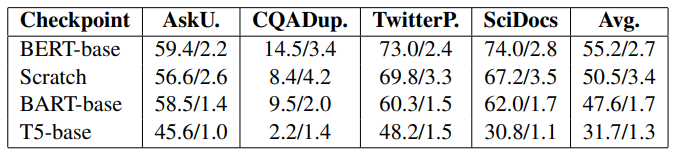
3.3 结论
本文提出了一种基于Transformer的序列降噪自编码器TSDAE来进行句子表示学习,该方法是一种有效利用降噪自编码器特点的无监督句子表示学习方法,能够增强模型对句子信息的总结和基于句子编码进行推理的能力,并且可以作为预训练框架从无标注数据中获取编码句子的知识,有效快速地迁移到目标领域。此外本文提出了新的句子表示模型的评估方法,使用具体领域下的数据集和相应的评估设置进行评估,能够取得与真实场景更吻合的效果。
本期总结
通过对近期句子表示学习方法的学习,从这些方法中发现了一些共有的结论:
在已有预训练模型上,进行合理的无监督微调,能够将模型在预训练过程中得到的知识运用于对句子的表示,微调后甚至超过有监督方法(SBERT)在其他通用领域监督训练的效果。
预训练阶段模型如果能够强化对句子编码的偏置,能够有效提升下游任务中的句子表示效果。这一点取决于合理的模型结构以及训练任务设置,并且训练任务适用于预训练以及预训练后的微调。
NLP中对比学习或其他无监督方法,大部分依赖于数据增强,相似正例的构造,目前没有发现同义词替换效果(CLEAR中验证)高于简单的删除、打乱和dropout,并且回译方法还无人实验,初步推测过于大幅度的破坏原句会引入过多噪声,增加任务难度导致模型效果下降。
参考文献
[1]Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. ArXiv preprint, abs/1807.03748.
[2]Yuanmeng Yan, Rumei Li, Sirui Wang, Fuzheng Zhang, Wei Wu, and Weiran Xu. 2021. ConSERT: A contrastive framework for self-supervised sentence representation transfer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5065–5075, Online. Association for Computational Linguistics.
[3]Zhuofeng Wu, Sinong Wang, Jiatao Gu, Madian Khabsa, Fei Sun, and Hao Ma. 2020. Clear: Contrastive learning for sentence representation. ArXiv preprint, abs/2012.15466.
[4]Taeuk Kim, Kang Min Yoo, and Sang-goo Lee. 2021. Self-guided contrastive learning for BERT sentence representations. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 2528–2540, Online. Association for Computational Linguistics.
[5]Fredrik Carlsson, Magnus Sahlgren, Evangelia Gogoulou, Amaru Cuba Gyllensten, and Erik Ylipää Hellqvist. 2021. Semantic re-tuning with contrastive tension. In International Conference on Learning Representations, ICLR 2021, Vienna, Austria, May 3-7, 2021, pages 1–21. International Conference on Learning Representations.
原文:赵峻瑶
编辑:HFL编辑部
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









