







还在为多语言的文本向量发愁?担心模型太大跑不动?
Jina Embeddings V3 来了,这款 5.7 亿参数的顶级文本向量模型,在多语言和长文本检索任务上达到当前最佳水平 SOTA。内置多种 LoRA 适配器,可以根据你的需求,针对 检索、聚类、分类和匹配 的不同场景进行定制,获得更精准的向量化效果。
多语言支持: 支持 89 种语言,全面超越 multilingual-e5-large-instruct
长文本处理: 支持 8192 token 的输入长度,在 LongEmbed 基准测试中表现出色
任务定制更精准: 内置多种 LoRA 适配器,针对检索、聚类、分类和匹配等任务,生成定制化向量,效果更精准。
输出维度可定制: 默认输出维度为 1024,但你完全可以根据需要把它缩减到 32,性能几乎不受影响,这都归功于俄罗斯套娃表示学习技术的加持。
模型已开源,即刻体验:
开源模型链接: https://huggingface.co/jinaai/jina-embeddings-v3
模型 API 链接: https://jina.ai/?sui=apikey
模型论文链接: https://arxiv.org/abs/2409.10173
模型表现数据
下面就用数据来直观地感受 jina-embeddings-v3 的强大实力。
英文任务:稳居第一梯队
jina-embeddings-v3 在 MTEB 的所有英文任务中都稳居第一梯队,性能超越 OpenAI 和 Cohere 的最新闭源模型。 每个任务的详细评估结果,可以看看我们 20 页的论文:https://arxiv.org/abs/2409.10173

多语言任务表现:全面超越竞品
jina-embeddings-v3 在 MTEB 各种多语言和跨语言任务中也展现出强大的实力,在各项测评均超越 multilingual-e5-large-instruct 模型。
长文档检索任务表现:高效处理长文本
在 LongEmbed 基准测试的六个长文档检索任务中,jina-embeddings-v3 表现抢眼,大幅领先其他模型。
这也说明,相比 baai-bge-m3 使用的固定位置编码技术,和 jina-embeddings-v2 使用的 ALiBi 方法,我们采用的 RoPE 位置编码技术能够更有效地处理长文本序列。
截至 2024 年 9 月 18 日,Jina Embeddings V3 是最强大的多语言向量模型,在 MTEB 英文排行榜上参数量小于十亿的模型中排名第二。
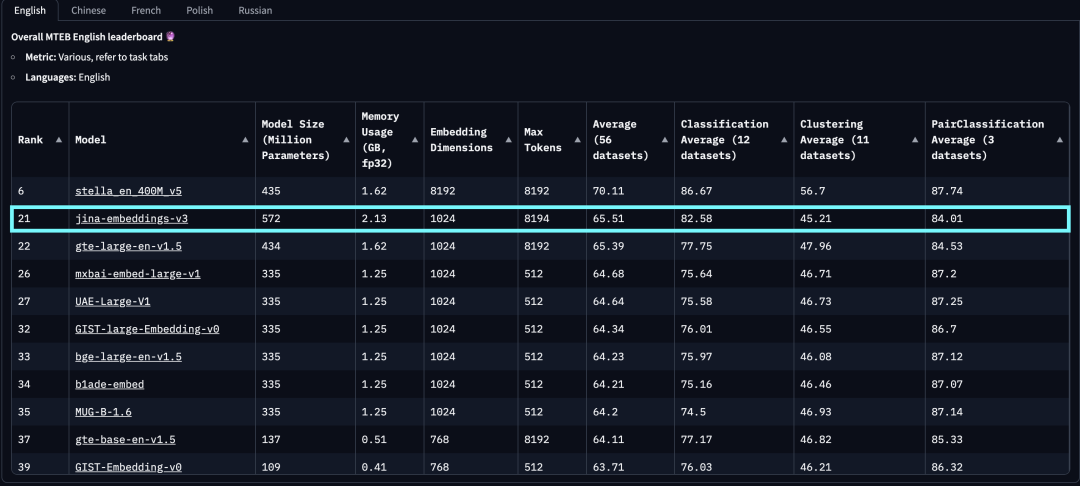
高效的参数利用
我们评估了 Jina Embeddings V3 的参数效率,并研究了向量模型的“scaling law”。通过分析 MTEB 排行榜上前 100 个向量模型,我们绘制了模型参数数量与英语任务平均 MTEB 性能之间的关系图,如下图所示:
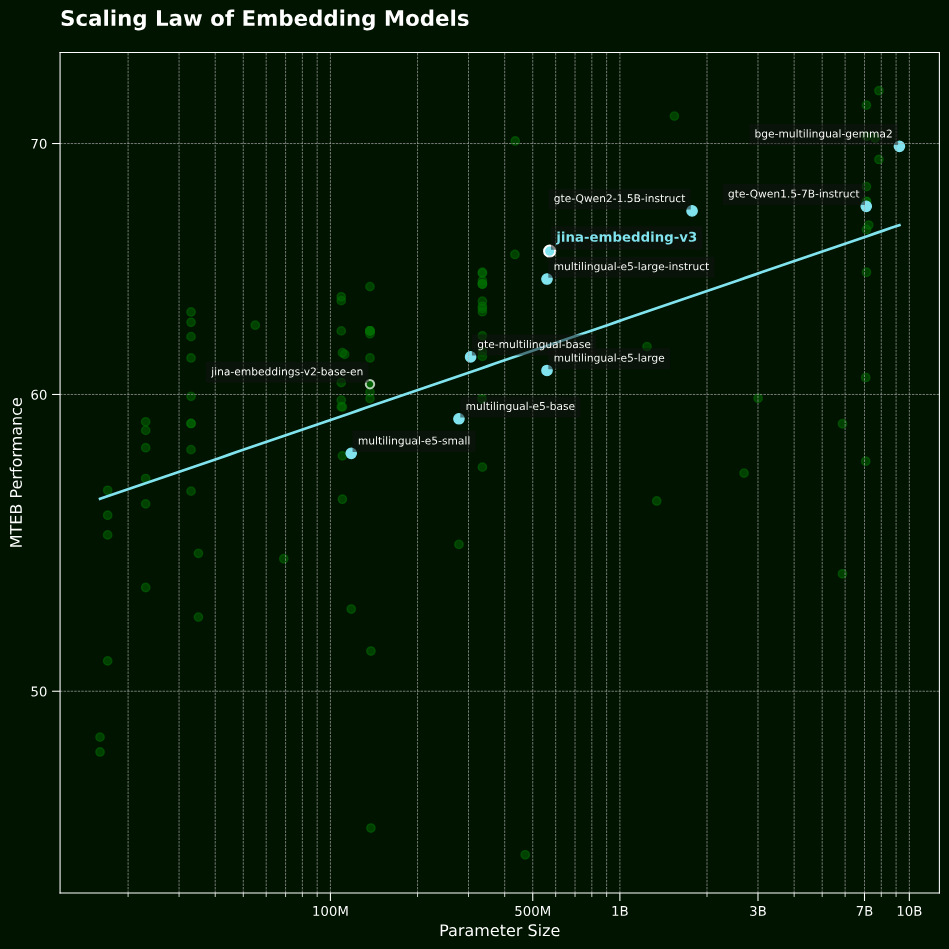
图中,横轴是模型参数规模,竖轴是在 MTEB 的性能表现。每个点代表一个向量模型,蓝色点表示多语言模型,趋势线则代表所有模型的整体趋势。
可以看到jina-embeddings-v3 在同等规模的模型中表现优异,并且超越其前代模型 jina-embeddings-v2,实现了超线性的提升。
与基于大型语言模型的向量模型相比,比如 e5-mistral-7b-instruct 有 71 亿参数和 4096 个输出维度,分别是 jina-embeddings-v3 的 12 倍和 4 倍,但在 MTEB 英文任务上的性能提升却只有 1%。
所以,如果你的项目对成本比较敏感,或者需要在生产环境和边缘设备上部署,jina-embeddings-v3 绝对是更合适的选择。
模型架构
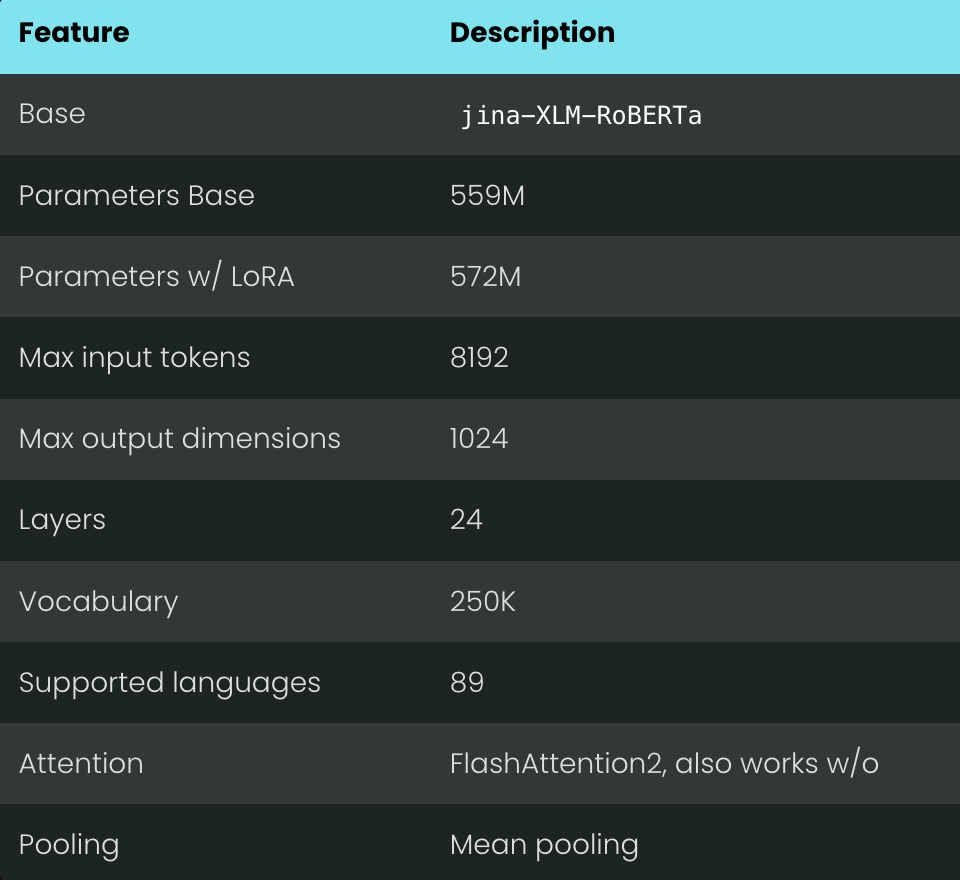
jina-embeddings-v3 基于 XLM-RoBERTa 模型架构,我们主要针对多语言长文本的处理,以及多任务场景进行了优化,核心改进有
高效长文本编码:采用 旋转位置编码 (RoPE) 支持高达 8192 个词元的序列长度,有效捕捉长文本语义信息。
任务特定适配器:集成 LoRA 适配器,可针对检索、分类、聚类、匹配等下游任务生成定制化嵌入向量,提升特定任务性能。
增强整体的效率:采用 FlashAttention 2 加速注意力计算,并结合激活检查点和 DeepSpeed 框架实现高效分布式训练,降低了计算和内存成本。
jina-embeddings-v3 也沿用了 XLM-RoBERTa 分词器,参数量为 5.7 亿,比 jina-embeddings-v2 的 1.37 亿多了不少,但和基于大型语言模型微调的向量模型相比,仍然算得上轻量级。
LoRA 适配器
不同的应用场景对文本向量模型的要求各不相同。在文本聚类任务中,我们希望模型能将语义相似的文本聚集在一起;而在信息检索任务中,我们则希望模型能够根据查询找到最相关的文档。也就是说模型需要针对不同的任务,采用不同的优化策略和相似度度量方法。
传统的做法是针对每个任务分别对模型进行微调,或者设计复杂的 Prompt 来引导模型。 但这两种方法都存在弊端:微调需要大量的训练数据和计算资源,而 Prompt 工程则依赖于专业的知识和经验,难以推广和应用,还可能导致模型效率低下。
Jina Embeddings V3 提供了一种更加灵活、高效、优雅的解决方案:任务特定的 LoRA 适配器。 我们为模型预先训练了五种 LoRA 适配器,分别对应四大类常见 NLP 任务,做到了开箱即用
语义检索:retrieval.query (用于查询) 和 retrieval.passage (用于文档)
文本聚类:separation
文本分类:classification
文本匹配:text-matching (例如语义相似度计算、对称检索等)
具体来说, 我们首先使用 XLM-RoBERTa 初始化模型,并冻结其权重;然后,针对上述四种任务,分别独立训练对应的 LoRA 适配器,确保每个适配器都能学习到特定任务所需的知识和模式。
使用时,你需要提供需要向量化的文档和任务类型。模型会根据你选择的任务,自动加载对应的 LoRA 适配器,生成针对该任务优化的向量,因为 LoRA 适配器的参数量很少,只占模型总参数量的不到 3%,所以对计算性能几乎没有影响,不用担心速度变慢。
提升模型鲁棒性
为了使模型在语义检索任务中更可靠,我们深入分析了 Jina Embeddings V2 的常见错误案例,把它们分门别类,用合成数据的方式来一一解决。
对于 模型容易被表面相似迷惑 、 不认识专有名词 和 搞不清是非题 这些挑战,我们设计了特殊的“提示词”,生成任务相关的正负数据,让模型学习如何区分真正相关的文档。
对于 模型只关注内容是否相似,而忽略了文档质量 的问题,我们收集了包含高质量和低质量答案的数据集,训练模型识别“低质量内容”,避免了检索结果被“垃圾信息”淹没。
快速上手
通过 Jina AI Search Foundation API
Jina Embeddings V3 已成为 Jina AI Search Foundation API 的默认模型,你只需要访问 Jina AI 官网 https://jina.ai/embeddings/,就能直接上手体验它的各种参数和功能了。
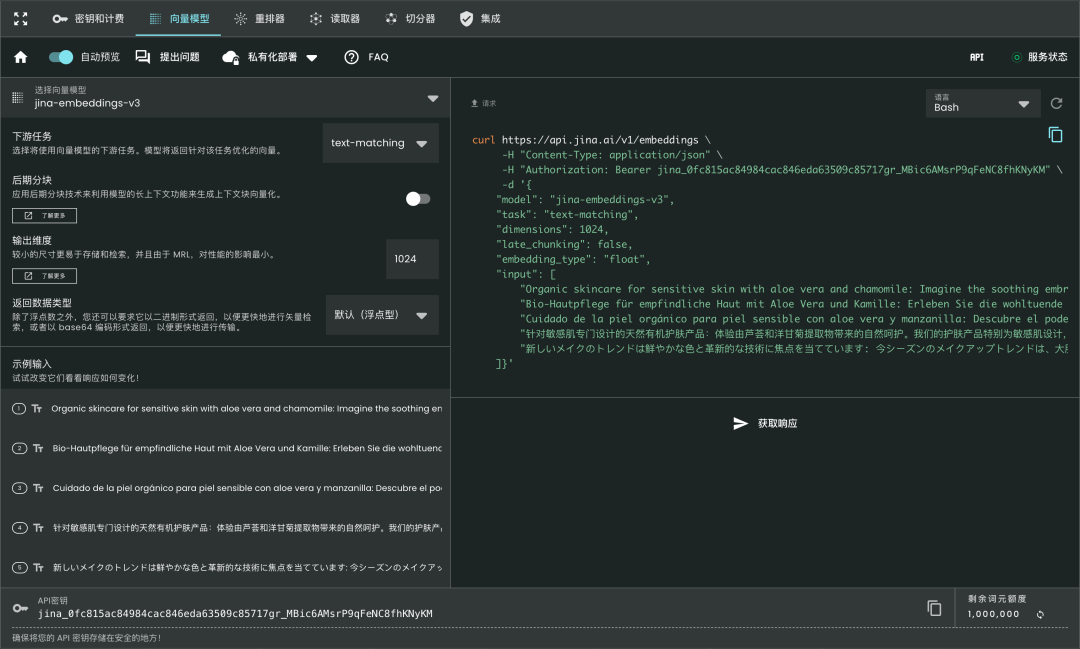
下面是用 curl 命令调用 API 的例子:
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'模型新参数
Jina Embeddings V3 的 API 在 v2 版本的基础上新增了三个参数,让你可以更精细地控制模型的行为:
task:指定下游任务
task 参数用于告诉模型你将用生成的文本向量做什么。不同的任务需要不同的向量表示方式,选择正确的 task 值可以显著提升模型效果。

dimensions:自定义向量维度
dimensions 参数你可以自定义文本向量的维度,更高的维度通常可以捕捉更丰富的语义信息,但也会占用更多存储空间和计算资源。
Jina Embeddings V3 采用了 俄罗斯套娃表示学习(Matryoshka Representation Learning,MRL),所以你可以根据需要把向量维度缩减到任意大小(甚至可以缩减到 1 维),性能几乎不会受到影响。如果你需要在向量数据库中存储大量向量,或者你的计算资源有限,可以考虑使用较小的向量维度。
late_chunking :优化长文本处理
late_chunking 参数控制模型如何处理长文本。通过迟分(late chunking)技术,可以更好地捕捉长文本中的上下文信息。
启用 late_chunking (设置为 true):
模型会将所有输入的句子连接成一个长字符串,再进行分块。每个分块生成的向量都会受到之前上下文的影响,能更好地理解整个文本的含义。
禁用 late_chunking (设置为 false,默认值):
模型会独立计算每个输入文本的向量,不考虑上下文信息。这种方式更适合处理短文本或者对上下文信息要求不高的场景。
要注意的是,
late_chunking 对 API 的输入和输出格式没有影响, 唯一的区别在于生成的向量值。
启用 late_chunking 时,每次请求的总 token 数不能超过 8192。但禁用 late_chunking 则没有 token 数量限制,只受到 Embedding API 的速率限制。
现已上线 Azure 和 AWS
jina-embeddings-v3 现已登陆 Azure Marketplace 和 AWS SageMaker 平台,方便你在云端快速部署和使用,且能确保数据不传输到第三方。
如果你需要在其他平台或公司内部署该模型,请注意该模型遵循 CC BY-NC 4.0 许可证。有关商业使用的更多信息,请联系我们:https://jina.ai/contact-sales/
与向量数据库与合作伙伴集成
Jina AI 与众多向量数据库供应商和 LLM 编排框架保持着紧密的合作关系,包括 Pinecone、Qdrant、Milvus、LlamaIndex、Haystack 和 Dify 等。
目前,Pinecone、Qdrant、Milvus 和 Haystack 已全面支持 jina-embeddings-v3,并集成了 task、dimensions 和 late_chunking 三个新参数。其他使用 v2 API 的合作伙伴也可以通过将模型名称更改为 jina-embeddings-v3 来支持新模型,但可能暂时无法使用 v3 版本新增的参数。
以下是部分合作伙伴的集成文档链接:
Pinecone: https://docs.pinecone.io/models/jina-embeddings-v3
Qdrant: https://qdrant.tech/documentation/embeddings/jina-embeddings/
Milvus: https://milvus.io/docs/integrate_with_jina.md
Haystack: https://haystack.deepset.ai/integrations/jina
结语
回顾 Jina AI 在文本向量模型领域的探索历程,我们在 2022 年 10 月发布了 jina-embeddings-v2-base-en,它是当时全球唯一一个支持 8K 上下文长度的开源向量模型,性能可与 OpenAI 闭源模型 text-embedding-ada-002 相媲美。经过一年多的不断探索和积累,我们终于推出了 Jina Embeddings V3,它是文本向量模型的新前沿,也是我司一个重要里程碑。
它不仅延续了我们在长文本向量方面的优势,更是在多语言支持、性能表现和功能丰富度上实现了质的飞跃。引入了多项前沿技术,任务特定的 LoRA 适配器、俄罗斯套娃表示学习和迟分等技术,使其在多语言长文本理解领域达到 SOTA 水平,并能够针对不同下游任务生成定制化向量表示,能够开箱即用地适应不同的应用场景。与一些基于大型语言模型的向量模型(如 NV-embed-v1/v2)相比,Jina Embeddings V3 具备更高的参数效率,更易于部署到生产环境和边缘设备,为构建检索增强生成 (RAG)、智能体等各种应用提供了理想的基础模型。
未来,我们会继续努力,提升模型在低资源语言上的性能,并解决数据稀缺带来的挑战。jina-embeddings-v3 的模型权重和前沿能力也将为我们即将发布的 jina-clip-v2、jina-reranker-v3 和 reader-lm-v2 等模型奠定坚实的基础,敬请期待!
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









