






导读
本文是对发表于 EMNLP 2024 的论文《MatchTime: Towards Automatic Soccer Game Commentary Generation》的解读。论文的共同第一作者为上海交通大学博士研究生饶珈源和上海交通大学博士研究生吴浩宁。

简述
针对当前已有足球解说数据集中普遍存在的视频文本时序不对齐问题,在此研究中,我们提出了三个贡献:
我们对部分比赛的解说时间戳进行手动标注,构建了一个精准的的足球比赛解说生成基准测试集SN-Caption-test-align。
在精标数据基础上,我们提出了一个多模态时序对齐流水线,实现对现有数据集自动校正和过滤,生成高质量的足球解说数据集 MatchTime。
最后,在MatchTime优质数据的加持下,我们训练了多模态足球解说模型型 MatchVoice,实现了对足球比赛的更为精准解说生成。
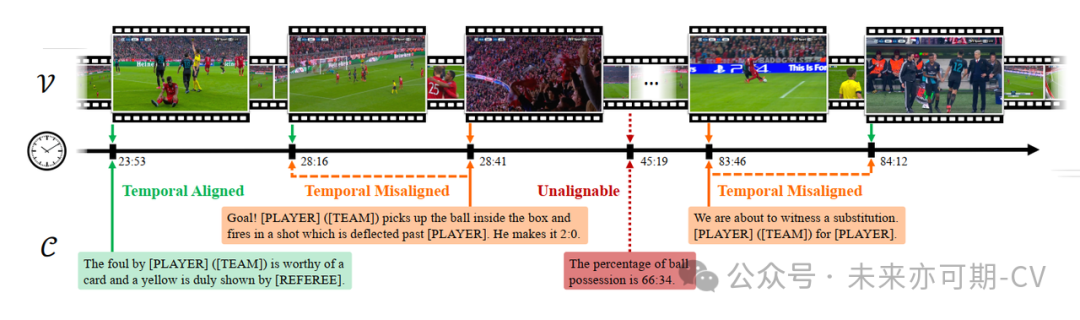
图1. 现有的足球比赛解说数据集在视觉内容和文本解说之间包含几类关系:对齐 (绿色)、无法对齐 (橙色) 以及无法对应 (红色)
所有代码、数据集均已开源
Code: github.com/jyrao/MatchTime
Web: haoningwu3639.github.io/MatchTime
Data: huggingface.co/datasets/Homie0609/MatchTime
Demo: www.bilibili.com/video/BV1L4421U76m
足球解说生成:视频理解与足球数据结合
随着人工智能技术的迅猛发展,AI在体育领域的理解能力不断提升。以SoccerNet[1]系列工作为代表的足球数据集,汇集了数百场欧洲主流足球联赛的比赛,为足球比赛理解建立了较为完整的基准体系。本研究所涉及的SoccerNet-Caption数据集包含471场足球比赛重点事件的时间节点与解说词。大量视频与文本的精确对齐是多模态模型学习理解视频的基础,然而,该数据集内解说词的时间戳远远无法达到AI模型训练所需的精准水平 (如图2所示)。
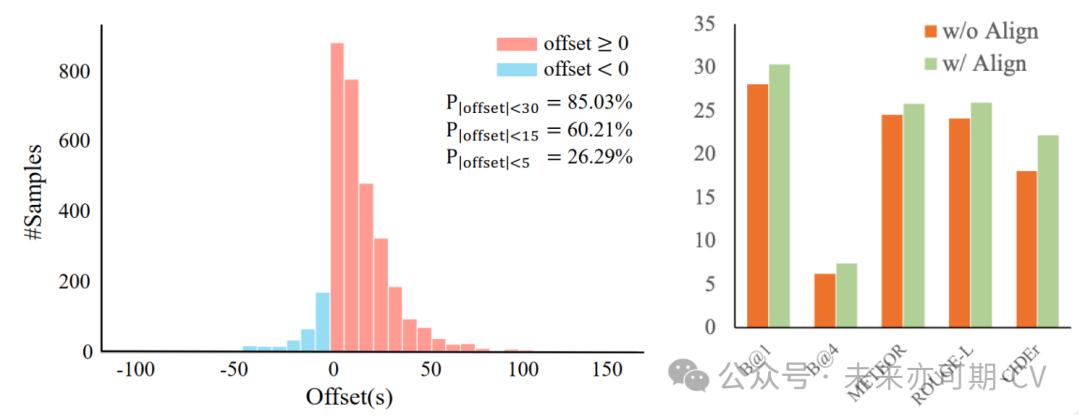
图2. 原数据集49场比赛解说时间戳偏差直方分布图 (左) 解说模型应在对齐后测试集展现更好的Zero-shot表现 (右)
建立精确的足球评论数据集MatchTime
Stage 1: 基于LLM Agent的粗粒度预处理
由于SoccerNet-Caption数据集解说词聚焦于少量关键事件,因此并未充分利用比赛音频解说中所蕴含的丰富语义信息。在预处理阶段,我们采用以下步骤 (如图3a所示),利用比赛解说音频与大语言模型,实现粗粒度的时间对齐:
音频文本提取与翻译:使用WhisperX[2]模型对比赛音频进行提取,得到带有秒级时间戳的音频文本 (Narration-text),并将其统一翻译为英文,其内部包含了当场解说嘉宾对于全场比赛的评述;
事件描述总结:使用 LLaMA-3 (8B) 模型,以10秒为单位对音频文本进行总结,提取语义信息更集中、句式更规整的事件描述 (Event-Description);
粗粒度时间戳对齐:继续使用 LLaMA-3 (8B) 模型,结合每条 SoccerNet-Caption 中的解说词及其时间戳附近的事件描述,进行初步判断,生成粗粒度对齐的时间戳 (Coarse-Aligned Timestamp)。
该方法利用大语言模型的推理能力,实现了对于大量解说音频的应用,生成了粗粒度对齐的时间戳。然而,由于解说音频存在碎片化叙述、缺乏视觉信息及语言表达方式差异等限制,这些时间戳仅作为预处理步骤,为下一阶段的细粒度对齐提供基础支持。
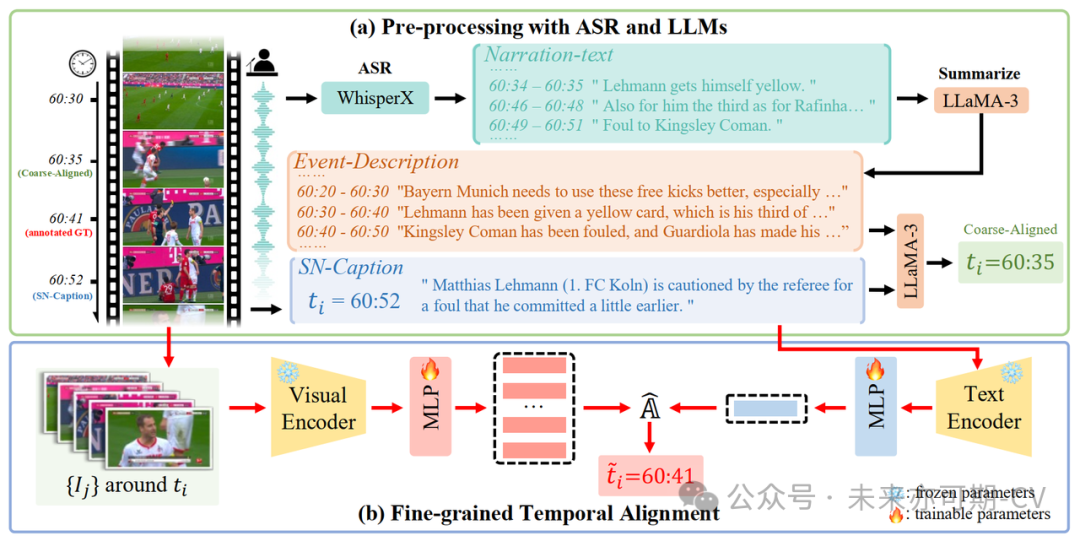
图3. 时间戳对齐流水线示意图:(a)基于LLM Agent的粗粒度预处理 (b)基于对比学习的细粒度对齐。
Stage 2: 基于对比学习的细粒度对齐
我们基于对比学习 (Contrastive Learning) 结合视觉元素,利用手动标注的SN-Caption-test-align数据集进行时序对齐训练 (如图3b所示)。按照如下步骤进行细粒度对齐:
图文特征编码:使用冻结的CLIP(ViT B-32)编码器以及可训练的多层感知器 (MLP) 编码器对每个粗粒度对齐时间戳 (Coarse-Aligned Timestamp) 周围的视频图像及解说词文本进行特征编码。
特征相似度筛取:计算解说文本特征与全部视频图像文本的相似度,选取相似度最高的一帧所在时间戳作为细粒度对齐时间戳 (Fine-grained Aligned Timestamp),收入MatchTime数据集中。
该对比学习模型的学习目的是最大化解说词文本其与对应图像的特征的相似度,从而加强模型基于文本特征选取视频中对应帧的能力。该步骤得到含有对齐后时间戳的解说词数据集MatchTime,作为后续解说模型训练与验证的数据集。
足球解说自动生成模型MatchVoice
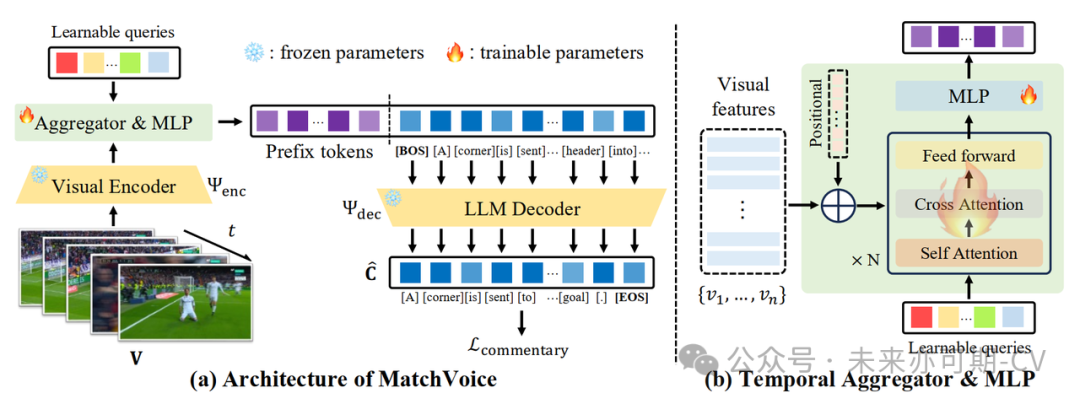
图4. MatchVoice架构示意图:(a)MatchVoice总体框架 (b)聚合模块内部框架
该工作中多模态模型使用提示微调 (Prompt Tuning) 方式进行训练,使用了以Q-former结构为基础的聚合模块连接视觉编码器与大语言模型,该模型结构框架如图4所示,主要分为以下几个部分:
视觉编码器 (Visual Encoder):用于对足球比赛视频片段进行特定帧率的图像采样和编码,提取视频的视觉特征;
聚合模块 (Aggregator & MLP):为图片特征序列加入时序信息后,在可学习序列(Learnable Queries)的作用下,依次经过多层自注意力、交叉注意力、前馈板块,得到与大语言模型前缀相同尺寸的张量;
大语言模型解码器 (LLM Decoder):将上述步骤得到的前缀张量放入大语言模型进行自回归推理,得到最终的解说文本,此处所使用的是 LLaMA-3 (8B) 模型。
该模型使用推理过程中各个令牌位置在词库中的预测概率分布的交叉熵作为损失函数,不断进行提示微调训练聚合模块,从而搭建视频模态与文本模态之间轻量化的桥梁,实现从足球视频到足球解说的推理过程。
实验
对齐流水线消融实验

图5. 对齐流水线消融实验 (左) 对齐模型使用案例 (右)
为验证对齐流水线的合理性,本研究从SN-Caption-test-align中选出4场比赛作为测试集 (292段解说样本),测试预处理对齐和细粒度对齐的效果。结果表明 (如图5所示),在依照我们提出的对齐流水线操作过后,时间戳的平均偏差从10.21秒降至0.03秒,平均偏差绝对值从13.89秒降至6.89秒。且此方法对齐后的时间戳在正确值周边各个窗口尺寸的比例均为最高值。
视觉编码器 & 解说模型消融实验
由于MatchVoice模型和现有足球解说模型 (SN-Caption) 中的聚合模块适用于任何尺寸的视频特征,本研究围绕几种不同的视觉编码器进行训练效果测试。我们采用了传统的语言评估模型 (BLEU, METEOR, ROUGE-L, CIDEr) 以及使用GPT-3.5模型进行评分的几类指标,对于不同视觉编码器和不同解说模型的训练效果进行消融实验:
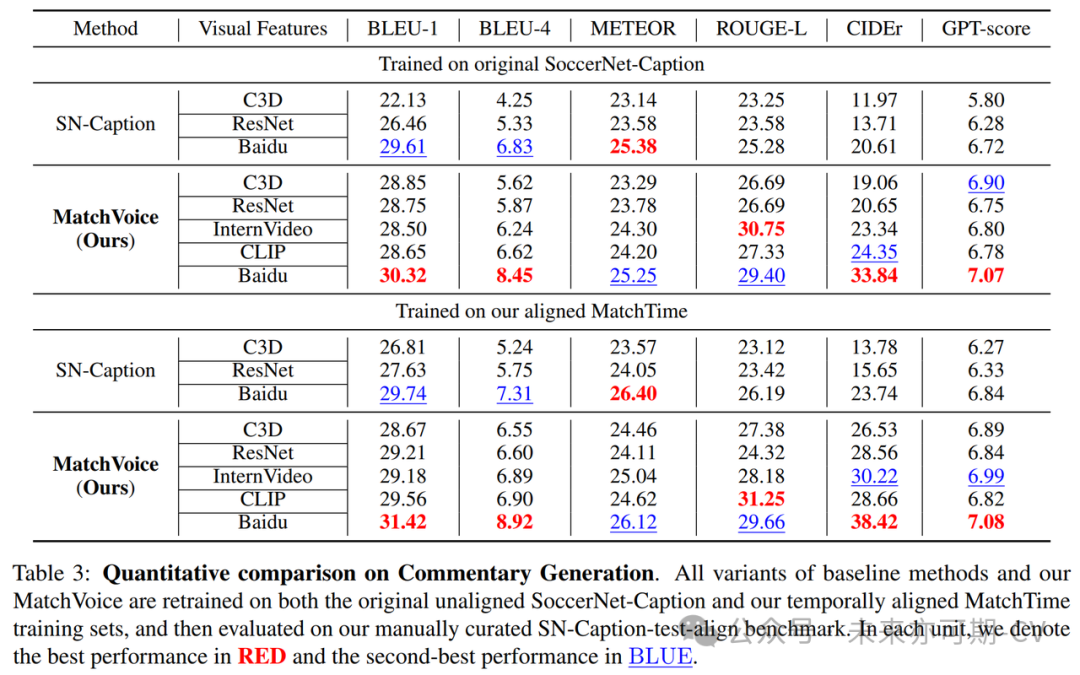
表1. 视觉编码器、数据集、解说模型消融实验
表1中消融实验结果表明,我们的模型MatchVoice在几乎全部视频解码器的测试表现均好于基于LSTM的SN-Caption模型。在几种不同的视觉编码器中,经过足球视频分类预训练的baidu视觉编码器[3]均能呈现几近最好的效果。上述消融实验体现了MatchVoice模型在足球解说任务的先进性,在各项指标上超越现有最佳足球解说模型。

图6. 不同解说模型解说案例
一些样例 (如图6所示) 也展现了此模型所产出的足球解说具有更丰富的语义描述、对多事件更全面的涵盖、更准确的叙述以及对未来事件的预测等优越性能。
实现效果
基于对齐后的数据集MatchTime与本研究中的MatchVoice解说模型,下方图7中展示了更多对于职业足球比赛内容精准解读的案例。
图片效果

图7. MatchVoice 足球解说图片效果
视频效果
MatchVoice 足球解说视频效果
结语
感谢您阅读至此。现阶段,人工智能在体育领域的应用难点主要在于高质量数据的匮乏。这篇工作与我们后续足球系列的工作也将以构建更好的数据集为基础而展开,从而推动这个领域的发展。对于笔者本人而言,我投身这个领域的梦想,就是借助AI让更多人感受到体育本身的魅力和激情。
体育常常教会我们怎么正确的面对成功与失败,然而关于足球,对于中国球迷而言,却总有清一色说不完的苦楚,我们一起经历了太多遗憾、痛心的时刻。但我始终相信“足球是圆的”,任何违背规律的奇迹,都不会理所应当的发生,足球如此,科研如此,生活也是如此。所以当我们看见我们的联赛正在向真正的职业化和大众化慢慢摸索;当我们看见一个个孙继海、董路们用自己的力量为中国足球提供新的思路,我们仍有理由对未来抱有企盼。在未来,希望我们在AI体育领域的工作能够真正的对通用模型、体育媒体,甚至体育竞技水平的进步,贡献更多的力量。
参考文献
[1] Hassan Mkhallati, Anthony Cioppa, Silvio Giancola, Bernard Ghanem, and Marc Van Droogenbroeck. 2023. Soccernet-caption: Dense video captioning for soccer broadcasts commentaries. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 5074–5085.
[2] Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. Whisperx: Time-accurate speech transcription of long-form audio. INTERSPEECH 2023.
[3] Xin Zhou, Le Kang, Zhiyu Cheng, Bo He, and Jingyu Xin. 2021. Feature combination meets attention: Baidu soccer embeddings and transformer based temporal detection. arXiv preprint arXiv:2106.14447.
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









