






摘要
尽管大型语言模型(LLM)在各种任务中取得了显着的成功,但它们经常面临着幻觉问题,特别是在需要深度和可信度的推理的场景中。这些问题可以通过在 LLM 推理中引入外部知识图谱(KG)来部分解决。在本文中,我们提出了一种新的LLM-KG集成范式“ L L M ⊗ K G LLM⊗KG LLM⊗KG”,它将LLM视为一个agent,交互式地探索KG上的相关实体和关系,并根据检索到的知识进行推理。我们通过引入一种称为 Think-on-Graph (ToG) 的新方法来进一步实现这一范式,其中 LLM agent在 KG 上迭代执行集束搜索,发现最有希望的推理路径,并返回最可能的推理结果。我们使用大量精心设计的实验来检验和说明ToG的以下优点:1)与LLM相比,ToG具有更好的深度推理能力;2)利用LLM推理和专家反馈,ToG具备知识溯源和知识纠错能力;3)ToG为不同的LLM、KG和提示策略提供了灵活的即插即用框架,无需任何额外的训练成本;4)在某些场景下,小型LLM模型的ToG性能可能超过大型LLM(例如GPT-4),这降低了LLM部署和应用的成本。作为一种计算成本更低、通用性更好的免训练方法,ToG 在 9 个数据集中的 6 个数据集中实现了总体 SOTA,而之前的 SOTA 大多依赖于额外的训练。我们的代码可在 https://github.com/IDEA-FinAI/ToG 上公开获取。
1.介绍
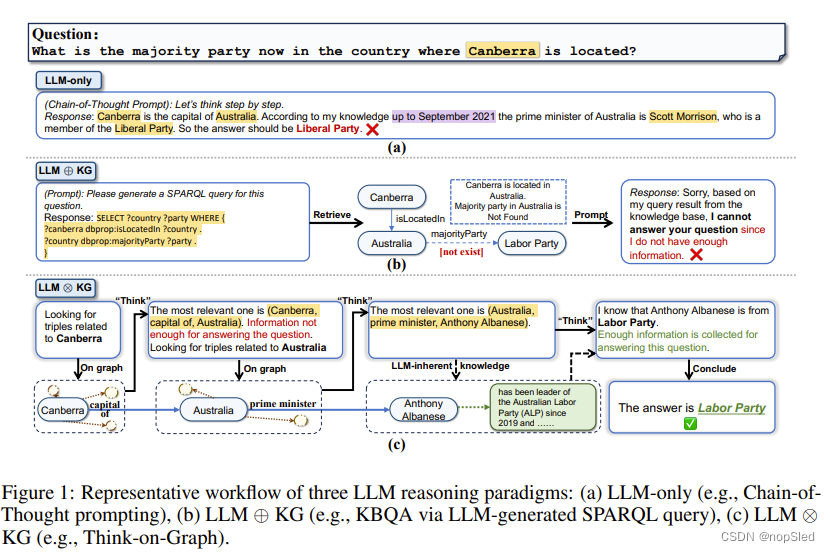
大型语言模型 (LLM) 在各种自然语言处理任务中表现出了卓越的性能。这些模型利用应用于大量文本语料库的预训练技术来生成连贯且上下文适当的响应。尽管LLM的表现令人印象深刻,但在面临需要复杂知识推理任务时,LLM仍存在很大的局限性。首先,LLM通常无法为超出了预训练阶段所包含的专业知识的问题(图1a中的过时知识)或需要长逻辑链和多跳知识推理的问题提供准确的答案。其次,LLM缺乏可信度、可解释性和透明度,引发了人们对幻觉或有毒文本风险的担忧。第三,LLM的训练过程通常既昂贵又耗时,这使得他们很难保持最新的知识。
认识到这些挑战,一个自然而有希望的解决方案是结合知识图谱 (KG) 等外部知识来帮助改进 LLM 推理。知识图谱提供结构化、明确且可编辑的知识表示,提出了缓解LLM局限性的补充策略。研究人员探索了使用知识图谱作为外部知识源来减轻LLM的幻觉。这些方法遵循一个惯例:从 KG 中检索信息,相应地增强提示,并将增强的提示输入 LLM(如图 1b 所示)。在本文中,我们将这种范式称为“LLM⊕KG”。虽然这种范式旨在整合LLM和KG的力量,其中LLM扮演了翻译器的角色,将输入问题转换为机器可理解的命令以进行KG搜索和推理,但它并不直接参与图推理过程。不幸的是,松耦合的
L
L
M
⊕
K
G
LLM⊕KG
LLM⊕KG范式有其自身的局限性,其成功在很大程度上取决于KG的完整性和高质量。例如,在图 1b 中,尽管 LLM 成功识别了回答问题所需的必要关系类型,但缺乏“majority party”关系会导致无法检索到正确答案。
基于这些考虑,我们提出了一种新的紧耦合范式“
L
L
M
⊗
K
G
LLM ⊗ KG
LLM⊗KG”,其中 KG 和 LLM 协同工作,在图推理的每个步骤中补充彼此的能力。图 1c 提供了一个示例,说明了
L
L
M
⊗
K
G
LLM ⊗ KG
LLM⊗KG 的优势。在这个例子中,导致图1b失败的缺失关系“majority party”可以通过具有动态推理能力的LLM agent发现的参考三元组 (Australia, prime minister, Anthony Albanese) 以及来自LLM的内部知识的 Anthony Albanese 的政党关系来补充。通过这种方式,LLM可以利用从知识图谱中检索到的可靠知识成功地生成正确答案。 作为该范式的实现,我们提出了一种算法框架“Think-on-Graph”(意思是:LLM沿着知识图谱上的推理路径一步步“思考”,下面缩写为ToG), 深度、可信、高效的LLM推理。 在KG/LLM推理中使用集束搜索算法,ToG允许LLM动态探索KG中的多个推理路径并做出相应的决策。给定一个输入问题,ToG 首先识别初始实体,然后迭代调用 LLM 通过探索(通过“on graph”步骤在 KG 中查找相关三元组)和推理(通过“think”步骤决定最相关的三元组)从 KG 中检索相关三元组,直到通过集束搜索中的前 N 个推理路径收集到足够的信息来回答问题(由“think”步骤中的LLM判断)或达到预定义的最大搜索深度。
ToG的优势可以简写为(1)深度推理:ToG从KG中提取多样化、多跳的推理路径作为LLM推理的基础,增强LLM对知识密集型任务的深度推理能力。(2)可信的推理:明确的、可编辑的推理路径提高了LLM推理过程的可解释性,并能够追踪和纠正模型输出的出处。(3)灵活性和效率:a)ToG是一个即插即用的框架,可以无缝地应用于各种LLM和KG。b)在ToG框架下,知识可以通过KG频繁更新,而不是LLM,后者知识更新昂贵且缓慢。c) ToG 增强了小型 LLM(例如 LLAMA2-70B)的推理能力,使其能够与大型 LLM(例如 GPT-4)竞争。
2.方法
ToG 通过要求 LLM 对知识图谱进行集束搜索来实现“ L L M ⊗ K G LLM⊗KG LLM⊗KG”范式。具体来说,它提示LLM在KG上迭代探索多种可能的推理路径,直到LLM确定可以根据当前推理路径回答问题。每次迭代后,ToG 不断更新和维护问题 x x x相关的top-N 推理路径 P = { p 1 , p 2 , . . . , p N } P=\{p_1, p_2,...,p_N\} P={p1,p2,...,pN},其中 N N N 表示集束搜索的宽度。ToG的整个推理过程包含以下3个阶段:初始化、探索和推理。
2.1 THINK-ON-GRAPH
2.1.1 INITIALIZATION OF GRAPH SEARCH
给定一个问题,ToG 利用底层 LLM 来局部化知识图谱上推理路径的初始实体。这个阶段可以看作是top-N推理路径 P P P的初始化。ToG首先提示LLM自动提取问题中的主题实体,并得到该问题的top-N主题实体 E 0 = { e 1 0 , e 2 0 , . . . , e N 0 } E^0=\{e^0_1, e^0_2, ..., e^0_N\} E0={e10,e20,...,eN0}。请注意,主题实体的数量可能小于 N N N。
2.1.2 EXPLORATION
在第
D
D
D 次迭代开始时,每条路径
p
n
p_n
pn 由
D
−
1
D−1
D−1 个三元组组成,即
p
n
=
{
(
e
s
,
n
d
,
r
j
,
n
d
,
e
o
,
n
d
)
}
d
=
1
D
−
1
p_n=\{(e^d_{s,n}, r^d_{j,n}, e^d_{o,n})\}^{D−1}_{d=1}
pn={(es,nd,rj,nd,eo,nd)}d=1D−1,其中
e
s
,
n
d
e^d_{s,n}
es,nd 和
e
o
,
n
d
e^d_{o,n}
eo,nd 表示主体和客体实体,
r
j
,
n
d
r^d_{j,n}
rj,nd 是它们之间的特定关系,(
e
s
,
n
d
,
r
j
,
n
d
,
e
o
,
n
d
e^d_{s,n}, r^d_{j,n}, e^d_{o,n}
es,nd,rj,nd,eo,nd) 和 (
e
s
,
n
d
+
1
,
r
j
,
n
d
+
1
,
e
o
,
n
d
+
1
e^{d+1}_{s,n}, r^{d+1}_{j,n}, e^{d+1}_{o, n}
es,nd+1,rj,nd+1,eo,nd+1) 彼此相连。
P
P
P 中尾实体集合和关系集合分别表示为
E
D
−
1
=
{
e
1
D
−
1
,
e
2
D
−
1
,
.
.
.
,
e
N
D
−
1
}
E^{D−1}=\{e^{D−1}_1, e^{D−1}_2, ..., e^{D−1}_N\}
ED−1={e1D−1,e2D−1,...,eND−1} 和
R
D
−
1
=
{
r
1
D
−
1
,
r
2
D
−
1
,
.
.
.
.
,
r
N
D
−
1
}
R^{D−1} =\{r^{D−1}_1, r^{D−1}_2, ... .,r^{D−1}_N\}
RD−1={r1D−1,r2D−1,....,rND−1}。
第
D
D
D 次迭代中的探索阶段旨在利用 LLM 根据问题 x 从当前 top-N 实体集
E
D
−
1
E^{D−1}
ED−1 的相邻实体中识别出最相关的 top-N 实体
E
D
E^D
ED,并使用
E
D
E^D
ED 扩展 top-N 推理路径
P
P
P。为了解决LLM处理大量相邻实体的复杂性,我们实施了两步探索策略:首先,探索重要关系,然后使用选定的关系来指导实体探索。
Relation Exploration。关系探索是一个从
E
D
−
1
E^{D−1}
ED−1 到
R
D
R^D
RD 的深度为 1、宽度为 N 的集束搜索过程。整个过程可以分解为两个步骤:搜索和修剪。 LLM作为agent自动完成这个过程。
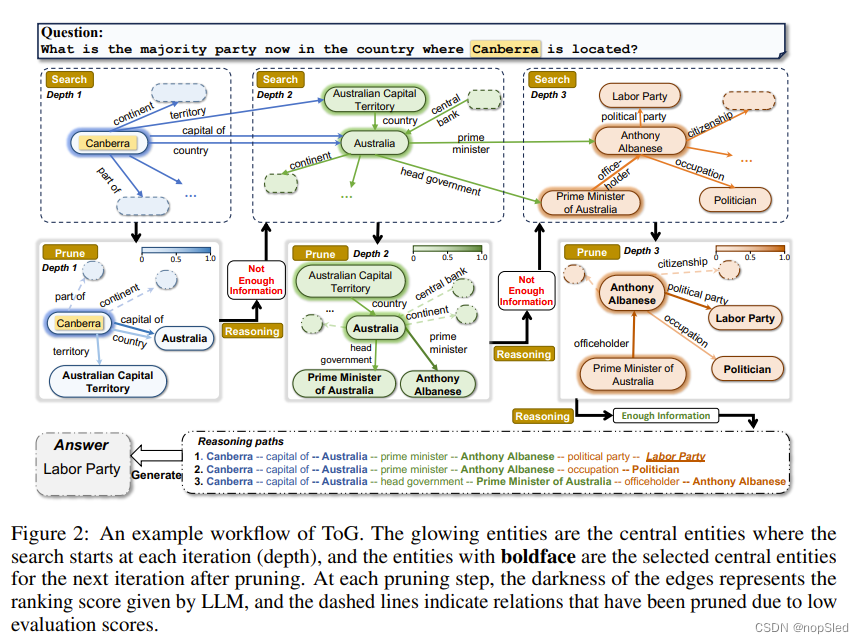
- Search。在第 D D D 次迭代开始时,关系探索阶段首先为每个推理路径 p n p_n pn 搜索链接到尾实体 e n D − 1 e^{D−1}_n enD−1 的关系 R c a n d , n D R^D_{cand,n} Rcand,nD 。这些关系被聚合到 R c a n d D R^D_{cand} RcandD 中。 在图 2 的情况下, E 0 = { C a n b e r r a } E^0 = \{Canberra\} E0={Canberra}, R c a n d 1 R^1_{cand} Rcand1 表示链接到Canberra的所有关系(包括出和入)的集合。值得注意的是,搜索过程可以通过执行附录 E.1 和 E.2 中所示的两个简单的预定义查询轻松完成,这使得 ToG 能够很好地适应不同的 KG,而无需任何训练成本。
- Prune。一旦我们从关系搜索中获得了候选关系集 R c a n d D R^D_{cand} RcandD和扩展的候选推理路径 P c a n d P_{cand} Pcand,我们就可以利用LLM根据问题 x x x 和候选关系 R c a n d D R^D_{cand} RcandD 的文字信息从 P c a n d P_{cand} Pcand中选出新的以尾关系 R D R^D RD结尾的top-N个推理路径 P P P。这里使用的提示可以在附录E.3.1中找到。如图 2 所示,LLM 在第一次迭代中从与实体Canberra相关的所有关系中选择了top-3 个关系{capital of, country, territory}。 由于Canberra是唯一的主题实体,因此前 3 个候选推理路径更新为 {(Canberra, capital of), (Canberra, country),(Canberra, territory)}。
Entity Exploration。与关系探索类似,实体探索也是LLM从 R D R^D RD到 E D E^D ED的集束搜索过程,由Search和Prune两个步骤组成。
- Search。一旦我们从关系探索中获得了新的 t o p − N top-N top−N 个推理路径 P P P 和新的尾部关系 R D R^D RD 集合,对于每个关系路径 p n ∈ P p_n ∈ P pn∈P,我们可以通过查询 ( e n D − 1 , r n D , ? ) (e^{D−1}_n, r^D_n, ?) (enD−1,rnD,?) 或 ( ? , r n D , e n D − 1 ) (?, r^D_n, e^{D−1}_n) (?,rnD,enD−1) 来探索候选实体集 E c a n d D E^D_{cand} EcandD,其中 e n D − 1 , r n e^{D−1}_n, r_n enD−1,rn 表示 p n p_n pn 的尾实体和关系。我们可以将 { E c a n d , 1 D , E c a n d , 2 D , . . . , E c a n d , N D } \{E^D_{cand,1}, E^D_{cand,2}, ..., E^D_{cand,N}\} {Ecand,1D,Ecand,2D,...,Ecand,ND} 聚合为 E c a n d D E^D_{cand} EcandD,并使用尾实体 E c a n d D E^D_{cand} EcandD 将top-N 个推理路径 P P P 扩展到 P c a n d P_{cand} Pcand。 对于所示的情况, E c a n d 1 E^1_{cand} Ecand1可以表示为{Australia, Australia, Australian Capital Territory}。
- Prune。由于每个候选集 E c a n d D E^D_{cand} EcandD 中的实体都是用自然语言表达的,因此我们可以利用 LLM 选择新的 top-N 个以来自 P c a n d P^{cand} Pcand 的尾实体 E D E^D ED 结尾的推理路径 P P P。这里使用的提示可以在附录E.3.2中找到。如图2所示,Australia和Australian Capital Territory得分为1,因为capital of, country 和 territory关系仅分别链接到一个尾实体,当前推理路径 p p p更新为{(Canberra, capital of, Australia),(Canberra, country, Australia), (Canberra, territory, Australian Capital Territory)}。
执行上述两个探索后,我们重建新的top-N 个推理路径 P P P,其中每个路径的长度增加 1。每个修剪步骤最多需要 N N N 次 LLM 调用。
2.1.3 REASONING
通过探索过程获得当前推理路径 P P P后,我们提示LLM评估当前推理路径是否足以生成答案。如果评估产生肯定的结果,我们会提示LLM使用推理路径和问题作为输入来生成答案,如图 2 所示。用于评估和生成的提示可以在附录 E.3.3 和 E.3.4 中找到。相反,如果评估产生否定结果,我们重复探索和推理步骤,直到评估为肯定或达到最大搜索深度 D m a x D_{max} Dmax。如果算法尚未得出结论,则意味着即使达到 D m a x D_{max} Dmax,ToG 仍然无法探索到解决问题的推理路径。在这种情况下,ToG 仅根据LLM的固有知识生成答案。ToG的整个推理过程包含 D D D个探索阶段和 D D D个评估步骤以及一个生成步骤,最多需要对LLM进行 2 N D + D + 1 2ND + D + 1 2ND+D+1次调用。
2.2 RELATION-BASED THINK-ON-GRAPH
以前的 KBQA 方法,特别是基于语义解析的方法,主要依赖问题中的关系信息来生成正式查询。受此启发,我们提出基于关系的 ToG (ToG-R),探索从主题实体
{
e
0
n
}
n
=
1
N
\{e0n\}^N_{n=1}
{e0n}n=1N 开始的top-N 个关系链
{
p
n
=
(
e
n
0
,
r
n
1
,
r
n
2
,
.
.
.
,
r
n
D
)
}
n
=
1
N
\{p_n =(e^0_n,r^1_n, r^2_n, ...,r^D_n)\}^N_{n=1}
{pn=(en0,rn1,rn2,...,rnD)}n=1N,而不是基于三元组的推理路径。ToG-R在每次迭代中依次执行关系搜索、关系剪枝和实体搜索,这与ToG相同。然后ToG-R基于实体搜索得到的所有以
E
c
a
n
d
D
E^D_{cand}
EcandD结尾的候选推理路径执行推理步骤。如果 LLM 确定检索到的候选推理路径没有包含足够的信息供 LLM 回答问题,我们会从候选实体
E
c
a
n
d
D
E^D_{cand}
EcandD 中随机采样 N 个实体,并继续下一次迭代。假设每个实体集
E
c
a
n
d
,
n
D
E^D_{cand,n}
Ecand,nD 中的实体很可能属于同一实体类并且具有相似的相邻关系,则实体集
{
E
c
a
n
d
,
n
D
}
n
=
1
N
\{E^D_{cand,n}\}^N_{n=1}
{Ecand,nD}n=1N 的剪枝结果可能对后续的关系探索影响不大。因此,我们使用随机集束搜索代替 ToG 中的 LLM 约束集束搜索进行实体剪枝,称为随机剪枝。算法1和算法2展示了ToG和ToG-R的实现细节。ToG-R 最多需要
N
D
+
D
+
1
ND + D + 1
ND+D+1 次调用 LLM。
与 ToG 相比,ToG-R 具有两个关键优势:1)它消除了使用 LLM 修剪实体的过程,从而减少了总体成本和推理时间。 2)ToG-R主要强调关系的字面信息,当中间实体的字面信息缺失或LLM不熟悉时,降低推理误导的风险。

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









