










23年10月来自澳大利亚两所大学的论文“Reasoning On Graphs: Faithful And Interpretable Large Language Model Reasoning“。
大语言模型(LLM)在复杂任务中表现出了令人印象深刻的推理能力。然而,他们在推理过程中缺乏最新的知识并经历幻觉现象,这可能导致不正确的推理过程,并降低性能和可信度。知识图(KG)以结构化的形式捕捉大量事实,为推理提供了可靠的知识来源。然而,现有基于KG的LLM推理方法只将KG视为事实知识库,忽略了其结构信息对推理的重要性。本文提出一种称为对图推理(RoG)的新方法,该方法使LLM与KGs协同工作,实现忠实和可解释的推理。具体来说,提出一个规划-检索-推理框架,其中RoG首先生成以KGs落地的关系路径作为忠实的规划。然后,这些规划被用于从KG中检索有效的推理路径,以便LLM进行忠实的推理。此外,RoG不仅从KGs中提取知识,通过训练提高LLM的推理能力,其允许在推理过程中与任意LLM做到无缝集成。
LLM仍然受到知识缺乏的限制,并且在推理过程中容易产生幻觉,这可能导致推理过程中的错误(Hong2023;Wang2023b)。如图所示,LLM没有最新的知识,并产生了一个错误的推理步骤:“有一个女儿”。这些问题在很大程度上降低了LLM在高风险情况下的性能和可信度,如法律判断和医疗诊断。
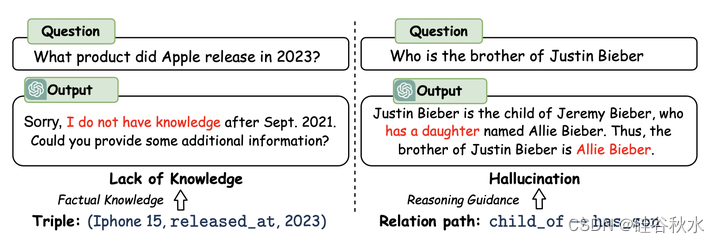
尽管语义解析方法可以通过利用KGs上的推理来生成更准确和可解释的结果,但由于语法和语义的限制,生成的逻辑查询通常是不可执行的,并且不会得到答案(Yu 2022a)。检索增强方法更灵活,并可以利用LLM的推理能力。然而,他们只将KGs视为事实知识库,忽视了其结构信息对推理的重要性(Jiang 2022)。例如,如上图所示,一个关系路径是一系列关系“child of→has son” 可以用来推断问题“谁是贾斯汀·比伯的哥哥?”的答案。因此,让LLM能够直接对KGs进行推理,去实现忠实和可解释的推理,是至关重要的。
知识图谱问答是一种典型的基于知识图谱的推理任务。给定一个自然语言问题 q 和一个KG G,该任务旨在设计一个函数f,基于来自G的知识用来预测答案a,即a=f(q,G)。根据之前的工作(Sun 2019;Jiang 2022),假设q中提到的实体eq和答案a被标记并链接到G中的相应实体,即Tq。
最近,人们探索了许多技术来通过规划来提高LLM的推理能力,即首先提示LLM生成推理规划,然后根据该规划进行推理(Wang 2023c)。然而,LLM以幻觉问题而闻名,幻觉问题容易产生错误的规划并导致错误的答案(Ji2023)。为了解决这个问题,本文提出了一个新的规划-检索-推理框架,其中推理规划以KGs为基础,然后为LLM推理对忠实的推理路径进行检索。
关系路径捕捉实体之间的语义关系,已被用于KGs上的许多推理任务(Wang 2021;Xu 2022)。此外,与动态更新的实体相比,KGs中的关系更稳定(Wang 2023a)。用关系路径,总是可以从KGs中检索最新的知识进行推理。因此,关系路径可以作为推理KGQA任务答案的忠实规划。
将关系路径视为规划,可以确保规划以KGs为基础,LLM能够对图进行忠实和可解释的推理。简言之,将RoG公式化为一个优化问题,该问题旨在通过生成关系路径z作为规划,最大限度地提高从知识图G推理答案的概率。
尽管将关系路径生成为规划具有优势,但LLM对KG中包含的关系一无所知。因此,LLM不能直接生成以KGs为基础的关系路径。此外,LLM可能无法正确理解推理路径并由此进行推理。为了解决这些问题,设计两个指令调优任务:1)规划优化,将知识从KGs提取到LLM中,生成作为规划的忠实关系路径;2) 检索-推理优化,使LLM能够根据检索的推理路径进行推理。
在规划优化中,目标是将知识从KGs提取到LLM中,生成作为规划的忠实关系路径。这个使用关系路径Q(z)的后验分布最小化KL发散来实现,该后验分布可以通过KGs中的有效关系路径来近似。在规划优化中,目标是将知识从KGs提取到LLM中,生成作为规划的忠实关系路径。这可以用忠实关系路径Q(z)的后验分布去最小化KL发散,该后验分布通过KGs中的有效关系路径来近似。
在检索-推理优化中,目标是使LLM能够根据检索的推理路径进行推理。对于检索-推理模块,遵循FiD框架(Izacard&Grave2021)在多个检索的推理路径上进行推理。RoG的最终目标函数是规划优化和检索-推理优化的结合。这里对规划和推理都采用了相同的LLM,是在两个指令调优任务上联合训练的,即(规划和检索-推理)。
规划模块旨在生成忠实关系路径作为回答问题的规划。为了利用LLM的指令跟从能力(Wei 2021),可设计一个简单的指令模板,提示LLM生成关系路径。
给定问题q和作为规划z的关系路径,检索模块旨在从KG图G检索这个推理路径wz。检索过程包括在G中查找路径,其从问题实体eq开始并遵循关系路径z。
采用一个约束的广度优先搜索(BFS)来检索来自KGs的推理路径wz。实验中,所有检索的路径都用于推理。其算法伪代码如下所示:首先用问题Tq的实体初始化当前推理路径Q的队列(第3-5行);然后添加连接到队列中实体的三元组来迭代扩展Q中的每个推理路径,该三元组遵循关系路径中的关系(第11-19行);扩展推理路径,直到长度等于关系路径的长度;扩展的推理路径添加到集合Wz中作为最终结果(第8-10行)。

尽管可以利用检索的推理路径,直接投票多数方法获得答案。但是检索的推理路径可能是含噪的和与问题无关的,从而导致错误的答案(He2021;Zhang2022)。因此,提出了一个推理模块来探索LLM的一种能力,即识别重要推理路径并以此回答问题。同样设计一个推理指令提示,引导LLM根据检索的推理路径Wz进行推理。
对于RoG,用LLaMA2-Chat-7B(Touvron2023)作为LLM主干,该主干是针对WebQSP、CWQ以及Freebase的训练进行了3个epochs的微调。批量处理大小设置为4,学习率设置为2e-5。用余弦的学习速率调度器策略,预热比率设置为0.03。训练在2台A100-80G GPU上进行,为期38小时。在推理过程中,首先采用LLM生成概率最高的top-K关系路径作为规划。然后,采用前面的BFS算法来检索推理路径,这些推理路径被输入LLM来推理最终答案。
对于LLM基线,用零样本提示来进行KGQA,直接要求LLM回答问题。对于其他基线,直接复制UniKGQA(Jiang 2022)和DECAF(Yu 2022a)中报告的结果进行比较。
实验中RoG与21个基线方法进行了比较,这些基线分为5类:1)基于嵌入的方法,2)增强检索的方法,3)语义解析方法,4)LLM,以及5)LLM+KGs方法。
最后说一下相关工作介绍。
首先是LLM推理提示。
已经有许多研究利用LLM的推理能力通过提示来处理复杂任务(Wei 2022;Wang2022;Yao2023;Besta2022)。思维链(Wei2022)使LLM能够生成有助于推理的推理链。思维树(Yao 2023)将推理链扩展为树结构,以探索更多的推理路径。思维图进一步将推理链建模为具有聚合操作的图,协同推理路径。规划-和-求解(Wang 2023c)提示LLM生成规划并在此基础上执行。DecomP(He 2021)提示LLMs将推理任务分解为一系列子任务,并逐步求解。然而,幻觉和知识缺乏的问题影响了推理的忠实性。ReACT(Yao 2022)将LLM视为智体,与环境交互获得最新的推理知识。为了探索忠实推理,Entailer(Tafjord 2022)引入了一个验证器来验证LLM生成的推理步骤。Creswell & Shanahan(2022)提出一个框架,包括两个LLM,分别用于选择和生成推理步骤。FAME(Hong 2023)引入蒙特卡罗规划来生成忠实的推理步骤。RR(He 2022)和KD CoT (Wang2023b)旨在从KGs中检索相关知识,为LLM制定忠实的推理计划。
再说知识图谱问答。
基于嵌入的方法对嵌入空间中的实体和关系进行建模,并设计特殊的模型架构来推理答案。KV-Mem(Miller 2016)采用KV内存网络存储三元组进行推理。Embedd KGQA(Saxena 2020)和NSM(He 2021)利用序列模型来模拟多步跳的推理过程。QA-GNN(Yasunaga 2021)和Greaselm(Zhang 2020)进一步采用图神经网络来捕捉图结构进行推理。然而,这些方法需要设计不同的模型体系结构,不灵活也不可泛化。
检索增强方法旨在从KGs中检索相关事实,提高推理性能。早期的工作采用页面排序(page rank)或随机行走算法从KGs中检索子图进行推理(Sun 2018;2019)。然而,它们忽略了问题中的语义信息,导致检索结果噪声较大。(Zhang2022)提出了一种基于关系路径的子图检索方法,获得了更好的检索和QA性能。其他研究系列通过BM25(Li2023)或DPR(Karpukhin2020;Yu2022b)从KGs中检索三元组,提高LLM的性能。他们丢弃KGs中的结构信息,这导致了次优结果。最近,UniKGQA(Jiang 2022)将图检索和推理过程统一为具有LLM的单个模型,在KGQA任务上实现了最先进的性能。
语义解析方法将问题解析为结构查询(例如,SPARQL),该查询可以由查询引擎执行获得答案(Sun 2020;Lan&Jiang,2020)。ArcaneQA(Gu&Su,2022)基于先前步骤的结果动态生成查询。RnG KBQA(Ye 2022)首先枚举所有可能的查询,然后对它们进行排序获得最终输出。这些方法在很大程度上依赖于生成的查询质量。如果查询不可执行,则不会生成任何答案。DECAF(Yu 2022a)结合语义解析和LLM推理来联合生成答案,这在KGQA任务中也达到了显著的性能。

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









