







1.问题发现:上下文长度被限制为2048(2k)
当我们使用ollama安装本地大模型,并且使用openai的api去调用本地大模型的时候。
发现无论我们的输入多长的内容,最终返回的提示词 prompt_tokens 长度只有2048。
当我们进行长文本问答的时候,大模型总是回答不知道我们想要的问题,这说明在问答的过程中很多重要的信息被截断舍弃了,这不是我们想要的。
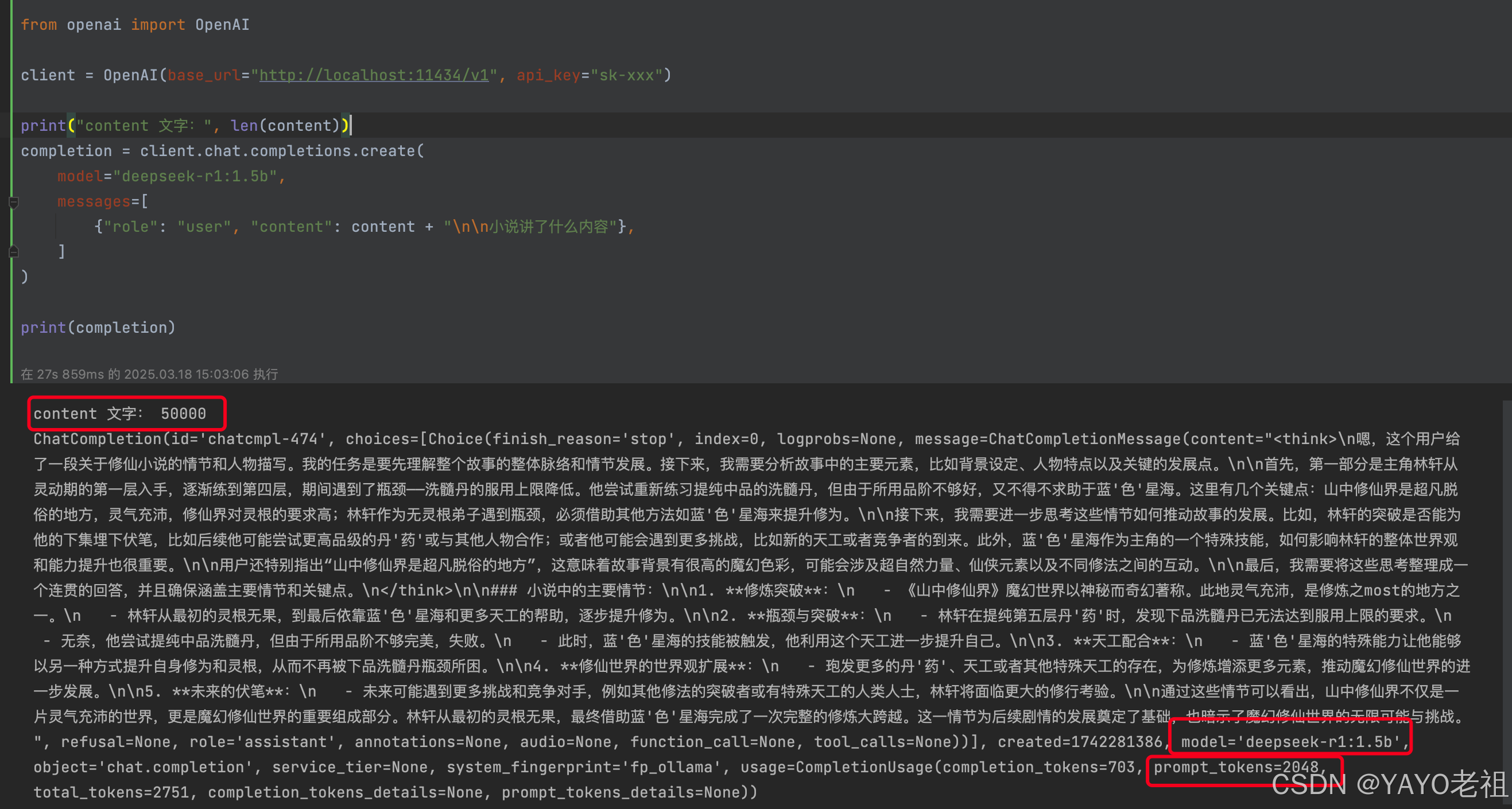
上图中,我使用了deepseek-r1的大模型去进行问答,deepseek-r1的上下文长度是128k,而问答内容有5w字,结果prompt_tokens只有2048
2.为啥ollama要限制上下文长度
主要是对机器性能的考量
实际实验中:当上下文长度从2048增加到4096时,显存占用和计算量会直接翻倍(甚至更高),这对GPU等硬件资源提出了更高要求。
当上下文长度调整为8192(4k)的时候,大概需要30g显存。
当上下文长度调整为32k的时候,大约需要200g显存。
3.如何突破限制了
1.导出模型配置文件到本地(以deepseek-r1:1.5b为例)
ollama show --modelfile deepseek-r1:1.5b > /data/model/deepseek-r1_1.5b_Modelfile

2.添加上下文配置 num_ctx
这里我写8192(4k),有条件的可以写更高
PARAMETER num_ctx 8192
PARAMETER stop <|begin▁of▁sentence|>
PARAMETER stop <|end▁of▁sentence|>
PARAMETER stop <|User|>
PARAMETER stop <|Assistant|>
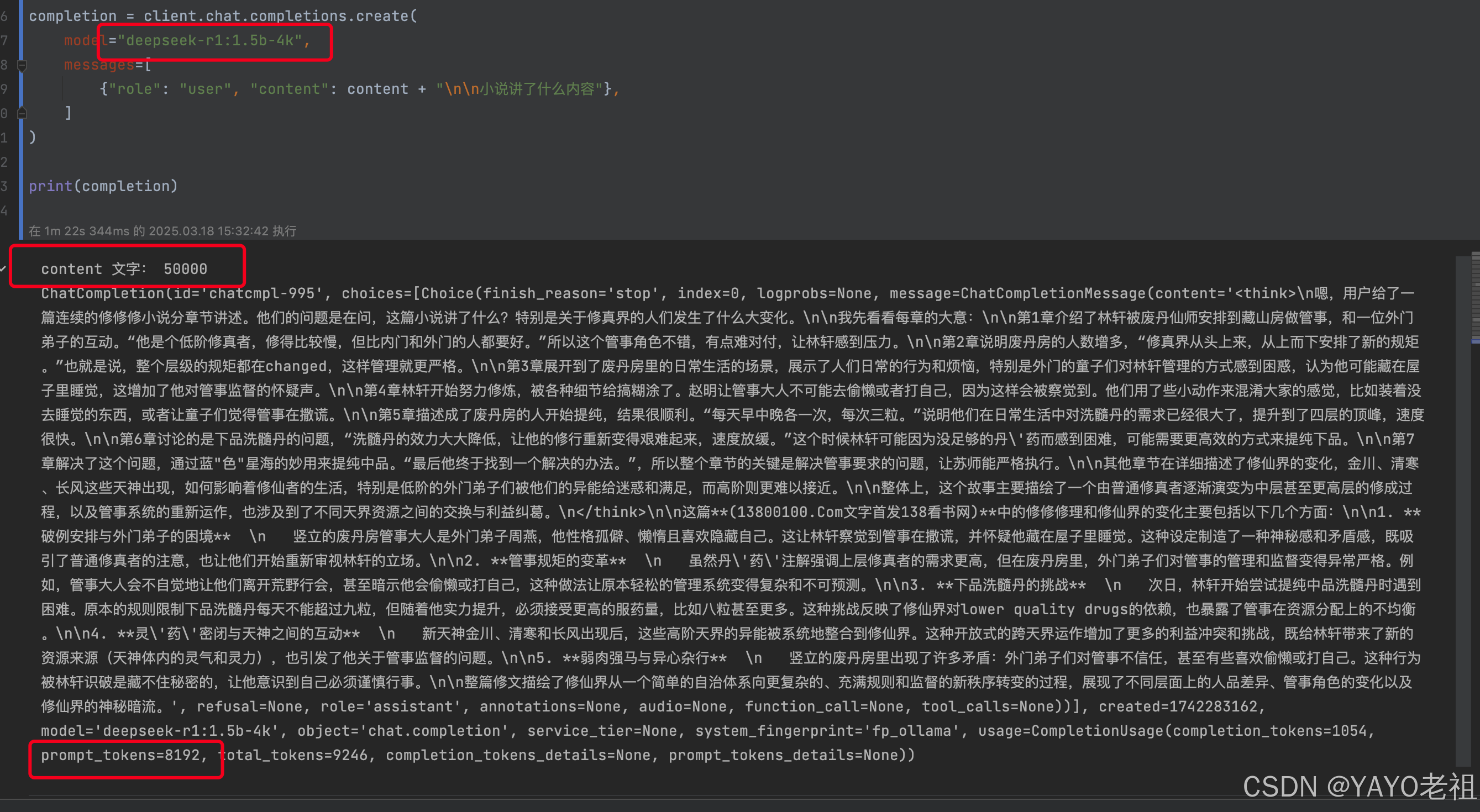
3.根据配置文件重新部署大模型
命名的时候可以加个后缀,代表这是上下文几k的模型
这里 -4k 就是上下文大小是4k
ollama create deepseek-r1:1.5b-4k -f /data/model/deepseek-r1_1.5b_Modelfile

4.验证 OK
4.踩坑:请求中添加配置的方式也可以修改上下文
这种方式只能调用ollama自己的的api(/api/chat),而不能使用openai的api(/v1/xxx)去调用大模型,用处不大
import requests
# ollama的api,而非openai的请求方式
url = "http://localhost:11434/api/chat"
payload = {
"model": "deepseek-r1:1.5b",
"stream": False,
"messages": [
{"role": "user", "content": content + "\n\n小说讲了什么内容"},
],
"options": {"num_ctx": 8192} # 上下文参数
}
response = requests.post(url, json=payload)
print(response.text)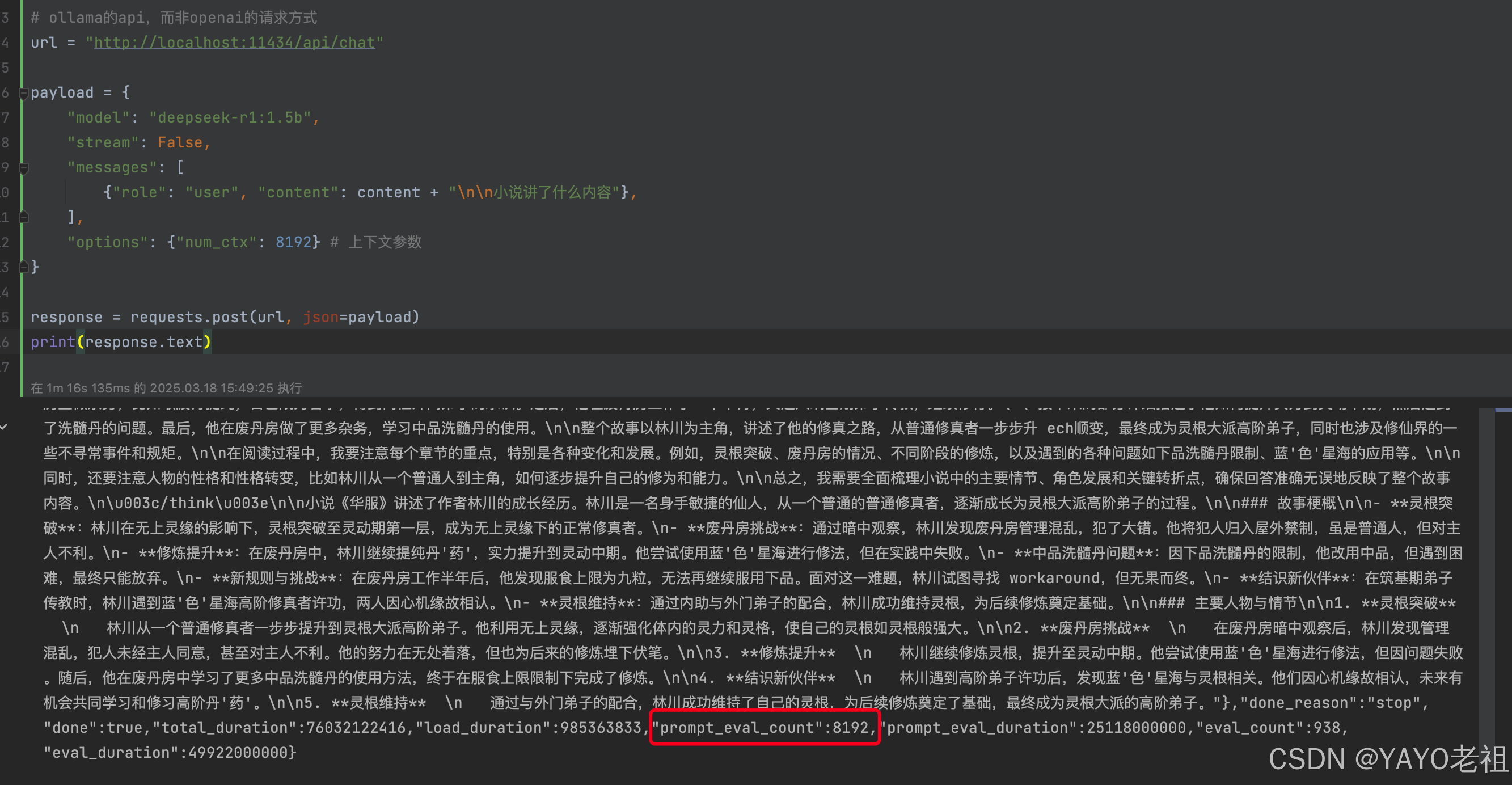

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









